Earlier this year, a team led by Kaylea Champion were announced as recipients of a generous grant from the Ford and Sloan Foundations to support research into into peer produced software infrastructure. Now that the project is moving forward in earnest, we’re thrilled to tell you about it.
Rapid Transit. Photo by Anthony Doudt, via flickr. CC BY-NC-ND 2.0
The project is motivated by the fact that peer production communities have produced awesome free (both as in freedom and beer) resources—sites like Wikipedia that gather the world’s knowledge, and software like Linux that enables innovation, connection, commerce, and discovery. Over the last two decades, these resources have become key elements of public digital infrastructure that many of us rely on every day. However, some pieces of digital infrastructure we rely on most remain relatively under-resourced—as security vulnerabilities like Heartbleed in OpenSSL reveal. The grant from Ford and Sloan aims will support a research effort to understand how and why some software packages that are heavily used receive relatively little community support and maintenance.
We’re tackling this challenge by seeking to measure and model patterns of usage, contribution, and quality in a population of free software projects. We’ll then try to identify causes and potential solutions to the challenges of relative underproduction. Throughout, we’ll draw on both insight from the research community and on-the-ground observations from developers and community managers. We aim to create practical guidance that communities and software developers can actually use as well as novel research contributions. Underproduction is, appropriately enough, a challenge that has not gotten much attention from researchers previously, so we’re excited to work on it.
Although Kaylea Champion is leading the project, the team working on the project includes Benjamin Mako Hill, Aaron Shaw, and collective affiliate Morten Warncke-Wang who did pioneering work on underproduction in Wikipedia.
The reproducibility movement in science has sought to increase our confidence in scientific knowledge by having research teams disseminate their data, instruments, and code so that other researchers can reproduce their work. Unfortunately, all approaches to reproducible research to date suffer from the same fundamental flaw: they seek to reproduce the results of previous research while making no effort to reproduce the research process that led to those results. We propose a new method of Exceedingly Reproducible Research (ERR) to close this gap. This blog post will introduce scientists to the error of their ways, and to the ERR of ours.
Even if a replication appears to have succeeded in producing tables and figures that appear identical to those in the original, they differ in that they are providing answers to different questions. An example from our own work illustrates the point.
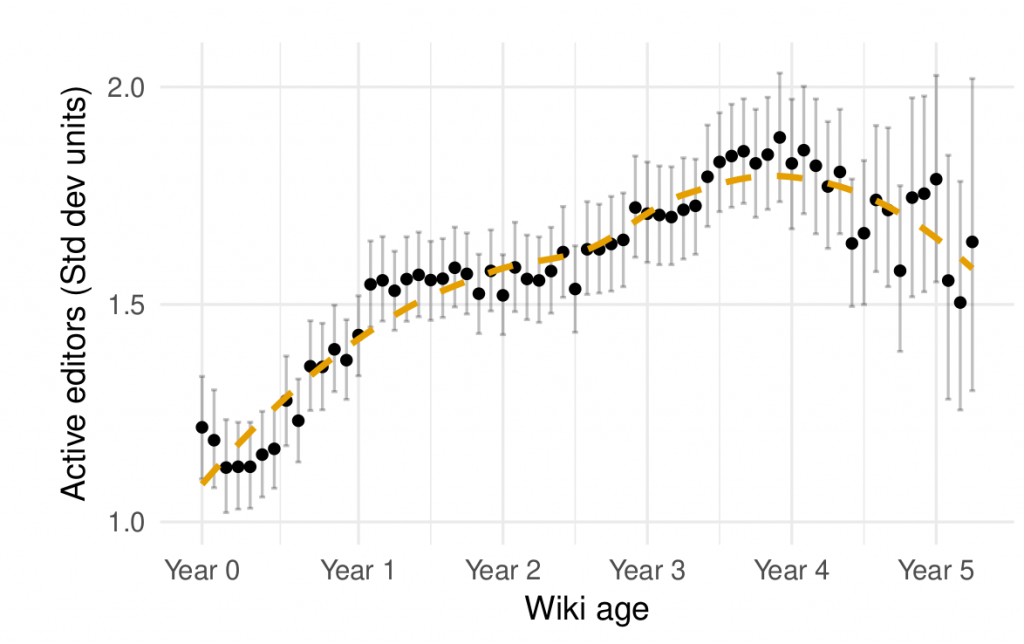
Figure 1: Active editors on Wikia wikis over time (taken from TeBlunthuis, Shaw, and Hill 2018)
Figure 1 above shows the average number of contributors (in standardized units) to a series of large wikis drawn from Wikia. It was created to show the life-cycles of large online communities and published in a paper last year.
Figure 2: Replication of Figure 1 from TeBlunthuis, Shaw, and Hill (2018)
Results from a replication are shown in Figure 2. As you can see, the plots have much in common. However, deeper inspection reveals that the similarity is entirely superficial. Although the dots and lines fall in the same places on the graphs, they fall there for entirely different reasons.
Tilting at windmills in Don Quixote.
Figure 1 reflects a lengthy exploration and refinement of a (mostly) original idea and told us something we did not know. Figure 2 merely tells us that the replication was “successful.” They look similar and may confuse a reader into thinking that they reflect the same thing. But they are as different as night as day. We are like Pierre Menard who reproduced two chapters of Don Quixote word-for-word through his own experiences: the image appears similar but the meaning is completely changed. In that we made no attempt to reproduce the research process, our attempt at replication was doomed before it began.
How Can We Do Better?
Scientific research is not made by code and data, it is made by people. In order to replicate a piece of work, one should reproduce all parts of the research. One must retrace another’s steps, as it were, through the garden of forking paths.
In ERR, researchers must conceive of the idea, design the research project, collect the data, write the code, and interpret the results. ERR involves carrying out every relevant aspect of the research process again, from start to finish. What counts as relevant? Because nobody has attempted ERR before, we cannot know for sure. However, we are reasonably confident that successful ERR will involve taking the same courses as the original scientists, reading the same books and articles, having the same conversations at conferences, conducting the same lab meetings, recruiting the same research subjects, and making the same mistakes.
There are many things that might affect a study indirectly and that, as a result, must also be carried out again. For example, it seems likely that a researcher attempting to ERR must read the same novels, eat the same food, fall prey to the same illnesses, live in the same homes, date and marry the same people, and so on. To ERR, one must have enough information to become the researchers as they engage in the research process from start to finish.
It seems likely that anyone attempting to ERR will be at a major disadvantage when they know that previous research exists. It seems possible that ERR can only be conducted by researchers who never realize that they are engaged in the process of replication at all. By reading this proposal and learning about ERR, it may be difficult to ever carry it out successfully.
Despite these many challenges, ERR has important advantages over traditional approaches to reproducibility. Because they will all be reproduced along the way, ERR requires no replication datasets or code. Of course, to verify that one is “in ERR” will require access to extensive intermediary products. Researchers wanting to support ERR in their own work should provide extensive intermediary products from every stage of the process. Toward that end, the Community Data Science Collective has started creating videos of our lab meetings in the form of PDF flipbooks well suited to deposition in our university’s institutional archives. A single frame is shown in Figure 3. We have released our video_to_pdf tool under a free license which you can use to convert your own MP4 videos to PDF.
Figure 3: PDF representation of one frame of a lab meeting between three members of the lab, produced using video_to_pdf. The full lab meeting is 25,470 pages (an excerpt is available).
With ERR, reproduction results in work that is as original as the original work. Only by reproducing the original so fully, so totally, and in such rigorous detail will true scientific validation become possible. We do not so much seek stand on the shoulders of giants, but rather to inhabit the body of the giant. If to reproduce is human; to ERR is divine.
In exciting news, Benjamin Mako Hill was just announced as a winner of a 2019 Research Symbiont Award. Mako received the second annual General Symbiosis Award which “is given to a scientist working in any field who has shared data beyond the expectations of their field.” The award was announced at a ceremony in Hawaii at the Pacific Symposium in Biocomputing.
A photo of the award itself: a plush fish complete with a parasitic lamprey.
The Research Symbionts Awards are given annually to recognize “symbiosis” in the form of data sharing. They are a companion award to the Research Parasite Awards which recognize superb examples of secondary data reuse. The award includes money to travel to the Pacific Symposium Computing (unfortunately, Mako wasn’t able to take advantage of this!) as well the plush fish with parasitic lamprey shown here.
In addition to the award given to Mako, Dr. Leonardo Collado-Torres was announced as the recipient of the health-specific Early Career Symobiont award for his work on Recount2.
It’s Ph.D. application season and the Community Data Science Collective is recruiting! As always, we are looking for talented people to join our research group. Applying to one of the Ph.D. programs that Aaron, Mako, and Sayamindu are affiliated with is a great way to do that.
This post provides a very brief run-down on the CDSC, the different universities and Ph.D. programs we’re affiliated with, and what we’re looking for when we review Ph.D. applications. It’s quite close to the deadline for some of our programs, but we hope this post will still be useful to prospective applicants now and in the future.
Members of the CDSC and friends assembled for a group meeting at UW in April, 2018. From left to right the people in the picture are: Julia, Charlie, Nate, Aaron, Salt, Sneha, Emilia, Sayamindu (hiding), Kaylea, Jeremy, Mako. Photo credit: Sage Ross (cc-by-sa)
What are these different Ph.D. programs? Why would I choose one over the other?
The group currently includes three faculty principal investigators (PIs): Aaron Shaw (Northwestern University), Benjamin Mako Hill (University of Washington in Seattle), and Sayamindu Dasgupta (University of North Carolina at Chapel Hill). The three PIs advise Ph.D. students in multiple Ph.D. programs at their respective universities. Our programs are each described below.
Although we often work together on research and serve as co-advisors to students in each others’ projects, each faculty person has specific areas of expertise and unique interests. The reasons you might choose to apply to one Ph.D. program or to work with a specific faculty member include factors like your previous training, career goals, and the alignment of your specific research interests with our respective skills.
At the same time, a great thing about the CDSC is that we all collaborate and regularly co-advise students across our respective campuses, so the choice to apply to or attend one program does not prevent you from accessing the expertise of our whole group. But please keep in mind that our different Ph.D. programs have different application deadlines, requirements, and procedures!
Benjamin Mako Hill is an Assistant Professor of Communication at the University of Washington. He is also an Adjunct Assistant Professor at UW’s Department of Human-Centered Design and Engineering (HCDE). Although almost all of Mako’s students are in the Department of Communication, he also advises students in the Department of Computer Science and Engineering and can advise students in HCDE as well—although he typically has no ability to admit students into those programs. Mako’s research focuses on population-level studies of peer production projects, computational social science, and efforts to democratize data science.
Aaron Shaw is an Assistant Professor in the Department of Communication Studies at Northwestern. In terms of Ph.D. programs, Aaron’s primary affiliations are with the Media, Technology and Society (MTS) and the Technology and Social Behavior (TSB) Ph.D. programs. Aaron also has a courtesy appointment in the Sociology Department at Northwestern, but he has not directly supervised any Ph.D. advisees in that department (yet). Aaron’s current research projects focus on comparative analysis of the organization of peer production communities and social computing projects, participation inequalities in online communities, and empirical research methods.
What do you look for in Ph.D. applicants?
There’s no easy or singular answer to this. In general, we look for curious, intelligent people driven to develop original research projects that advance scientific and practical understanding of topics that intersect with any of our collective research interests.
To get an idea of the interests and experiences present in the group, read our respective bios and CVs (follow the links above to our personal websites). Specific skills that we and our students tend to use on a regular basis include experience consuming and producing social science and/or social computing (human-computer interaction) research; applied statistics and statistical computing, various empirical research methods, social theory and cultural studies, and more.
Formal qualifications that speak to similar skills and show up in your resume, transcripts, or work history are great, but we are much more interested in your capacity to learn, think, write, analyze, and/or code effectively than in your credentials, test scores, grades, or previous affiliations. It’s graduate school and we do not expect you to show up pre-certified in all the ways or knowing how to do all the things already.
Intellectual creativity, persistence, and a willingness to acquire new skills and problem-solve matter a lot. We think doctoral education is less about executing a task that someone else hands you and more about learning how to identify a new, important problem; develop an appropriate approach to solving it; and explain all of the above and why it matters so that other people can learn from you in the future. Evidence that you can or at least want to do these things is critical. Indications that you can also play well with others and would make a generous, friendly colleague are really important too.
All of this is to say, we do not have any one trait or skill set we look for in prospective students. We strive to be inclusive along every possible dimension. Each person who has joined our group has contributed unique skills and experiences as well as their own personal interests. We want our future students and colleagues to do the same.
Now what?
Still not sure whether or how your interests might fit with the group? Still have questions? Still reading and just don’t want to stop? Follow the links above for more information. Feel free to send at least one of us an email. We are happy to try to answer your questions and always eager to chat.
This post was co-authored by Benjamin Mako Hill and Aaron Shaw. We wrote it following a conversation with the CSCW 2018 papers chairs. At their encouragement, we put together this proposal that we plan to bring to the CSCW town hall meeting. Thanks to Karrie Karahalios, Airi Lampinen, Geraldine Fitzpatrick, and Andrés Monroy-Hernández for engaging in the conversation with us and for facilitating the participation of the CSCW community.
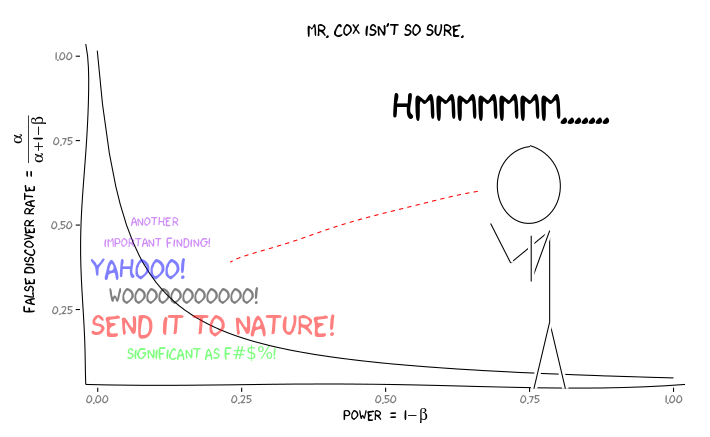
Quantitative methodologists argue that the high rates of false discovery are, among other reasons, a function of common research practices carried out in good faith. Such practices include accidental or intentional p-hacking where researchers try variations of their analysis until they find significant results; a garden of forking paths where researcher decisions lead to a vast understatement of the number of true “researcher degrees of freedom” in their research designs; the file-drawer problem which leads only statistically significant results to be published; and underpowered studies, which make it so that only overstated effect sizes can be detected.
Graph of the relationship between statistical power and the rates of false discovery. [Taken from this answer on the statistics Q&A site Cross Validated.]
To the degree that much of CSCW and HCI use the same research methods and approaches as these other social scientific fields, there is every reason to believe that these issues extend to social computing research. Of course, given that replication is exceedingly rare in HCI, HCI researchers will rarely even find out that a result is wrong.
To date, no comprehensive set of solutions to these issues exists. However, scholarly communities can take steps to reduce the threat of false discovery. One set of approaches to doing so involves the introduction of changes to the way quantitative studies are planned, executed, and reviewed. We want to encourage the CSCW community to consider supporting some of these practices.
Among the approaches developed and adopted in other research communities, several involve breaking up research into two distinct stages: a first stage in which research designs are planned, articulated, and recorded; and a second stage in which results are computed following the procedures in the recorded design (documenting any changes). This stage-based process ensures that designs cannot shift in ways that shape findings without some clear acknowledgement that such a shift has occurred. When changes happen, adjustments can sometimes be made in the computation of statistical tests. Readers and reviewers of the work can also have greater awareness of the degree to which the statistical tests accurately reflect the analysis procedures or not and adjust their confidence in the findings accordingly.
Versions of these stage-based research designs were first developed in biomedical randomized controlled trials (RCTs) and are extremely widespread in that domain. For example, pre-registration of research designs is now mandatory for NIH funded RCTs and several journals are reviewing and accepting or rejecting studies based on pre-registered designs before results are known.
A proposal for CSCW
In order to address the challenges posed by false discovery, CSCW could adopt a variety of approaches from other fields that have already begun to do so. These approaches entail more or less radical shifts to the ways in which CSCW research gets done, reviewed, and published.
As a starting point, we want to initiate discussion around one specific proposal that could be suitable for a number of social computing studies and would require relatively little in the way of changes to the research and reviewing processes used in our community.
Drawing from a series of methodological pieces in the social sciences ([1], [2], [3]), we propose a method based on split-sample designs that would be entirely optional for CSCW authors at the time of submission.
Essentially, authors who chose to do so could submit papers which were written—and which will be reviewed and revised—based on one portion of their dataset with the understanding that the paper would be published using identical analytic methods also applied to a second, previously un-analyzed portion of the dataset. Authors submitting under this framework would choose to have their papers reviewed, revised and resubmitted, and accepted or rejected based on the quality of the research questions, framing, design, execution, and significance of the study overall. The decision would not be based on the statistical significance of final analysis results.
The idea follows from the statistical technique of “cross validation,” in which an analysis is developed on one subset of data (usually called the “training set”) and then replicated on at least one other subset (the “test set”).
To conduct a project using this basic approach, a researcher would:
Randomly partition their full dataset into two (or more) pieces.
Design, refine, and complete their analysis using only one piece identified as the training sample.
Undergo the CSCW review process using the results from this analysis of the training sample.
If the submission receives a decision of “Revise and Resubmit,” authors would then make changes to the analysis of the training sample as requested by ACs and reviewers in the current normal way.
If the paper is accepted for publication, the authors would then (and only then) run the final version of the analysis using another piece of their data identified as the test sample and publish those results in the paper.
We expect that authors would also publish the training set results used during review in the online supplement to their paper uploaded to the ACM Digital Library.
Like any other part part of a paper’s methodology, the split sample procedure would be documented in appropriate parts of the paper.
We are unaware of prior work in social computing that has applied this process. Researchers in data mining, machine learning, and related fields of computer science use cross-validation all the time, they do so differently in order to solve distinct problems (typically related to model overfitting).
The main benefits of this approach (discussed in much more depth in the references at the beginning of this section) would be:
Heightened reliability and reproducibility of the analysis.
Reduced risk that findings reflect spurious relationships, p-hacking, researcher or reviewer degrees of freedom, or other pitfalls of statistical inference common in the analysis of behavioral data—i.e., protection against false discovery.
A procedural guarantee that the results do not determine the publication (or not) of the work—i.e., protection against publication bias.
The most salient risk from the approach is that results might change when authors run the final analysis on the test set. In the absence of p-hacking and similar issues, such changes will usually be small and will mostly impact the magnitude of effects estimates and their associated standard errors. However, some changes might be more dramatic. Dealing with changes of this sort would be harder for authors and reviewers and would potentially involve something along the lines of the shepherding that some papers receive now.
Let’s talk it over!
This blog post is meant to spark a wider discussion. We hope this can happen during CSCW this year and beyond. We believe the procedure we have proposed would enhance the reliability of our work and is workable in CSCW because it involves narrow changes to the way that quantitative CSCW research and reviewing is usually conducted. We also believe this procedure would serve the long term interests of the HCI and social computing research community. CSCW is a leader in building better models of scientific publishing within HCI through the R&R process, eliminated page limits, the move to PACM, and more. We would like to extend this spirit to issues of reproducibility and publication bias. We are eager to discuss our proposal and welcome suggestions for changes.
Michael L Anderson and Jeremy Magruder. Split-sample strategies for avoiding false discoveries. Technical report, National Bureau of Economic Research, 2017. https://www.nber.org/papers/w23544
Susan Athey and Guido Imbens. Recursive partitioning for heterogeneous causal effects. Proceedings of the National Academy of Sciences, 113(27):7353–7360, 2016. https://doi.org/10.1073/pnas.1510489113
Marcel Fafchamps and Julien Labonne. Using split samples to improve inference on causal effects. Political Analysis, 25(4):465–482, 2017. https://doi.org/10.1017/pan.2017.22
The last decade has seen a massive increase in formality and rigor in quantitative and statistical research methodology in the social scientific study of online communities. These changes have led to higher reliability, increased reproducibility, and increased faith that our findings accurately reflect empirical reality. Unfortunately, these advancements have not come without important costs. When high methodological standards make it harder for scientists to know things, we lose the ability to speak about important phenomena and relationships.
There are many studies that simply cannot be done with the highest levels of statistical rigor. Significant social concepts such as race and gender can never truly be randomly assigned. There are relationships that are rare enough that they can never be described with a p-value of less than 0.05. To understand these phenomena, our methodology must be more relaxed. In our rush to celebrate the benefits of rigor and formality, social scientists are not exploring the ways in which more casual forms of statistical inference can be useful.
To discuss these issues and their impact in social computing research, the Community Data Science Collective will be holding the first ever workshop on Casual Inference in Online Communities this coming October in Evanston, Illinois. We hope to announce specific dates soon.
Although our program remains to be finalized, we’re currently planning to organize the workshop around five panels:
Panel 1: Relaxing Assumptions
A large body of work in statistics has critiqued the arbitrary and rigid “p < .05” significance standard and pointed to problems like “p-hacking” that it has caused. But what about the benefits that flow from a standard of evidence that one out of twenty non-effects can satisfy? In this panel, we will discuss some of the benefits of p-value standards that allow researchers to easily reject the null hypothesis that there is no effect.
For example, how does science benefit from researchers’ ability to keep trying models until they find a publishable result? What do we learn when researchers can easily add or drop correlated measures to achieve significance? We will also talk about promising new methods available to scientists for overcoming high p-values like choosing highly informative Bayesian priors that ensure credible intervals far away from 0. We will touch on unconstrained optimization, a new way of fitting models by “guesstimating” parameters.
Panel 2: Exputation of Missing Data
Missing data is a major problem in social research. The most common ways of addressing missing data are imputation methods. Of course, imputation techniques bring with them assumptions that are hard to understand and often violated. How might types of imputation less grounded in data and theory help? How might we relax assumptions to infer things more casually about data—and with data—that we can not, and will not, ever have? How can researchers use their beliefs and values to infer data?
Our conversation will focus on exputation, a new approach that allows researches to use their intuition, beliefs, and desires to imagine new data. We will touch on multiple exputation techniques where researchers engage in the process repeatedly to narrow in on desired results.
Panel 3: Quasi-Quasi Experiments
Not every study can be at the scientific gold standard of a randomized control experiment. The idea of quasi-experiments are designed to relax certain assumptions and requirements in order to draw similar types of inference from non-experimental settings. This panel will ask what might we gain if we were relax things even more.
What might we learn from quasi-quasi experiments, where shocks aren’t quite exogenous (and might not even be that shocking)? We also hope to discuss superficial intelligence, post hoc ergo propter hoc techniques, supernatural experiments, and symbolic matching based on superficial semantic similarities.
Panel 4: Irreproducible Results
Since every researcher and every empirical context is unique, why do we insist that the same study conducted by different researchers should not be? What might be gained from embracing, or even pursuing, irreproducible methods in our research? What might we see if we allow ourselves to be the giants upon whose shoulders we stand?
Panel 5: Research Ethics
[Canceled]
Although we are hardly the first people to talk about casual inference, we believe this will be the first academic meeting on the topic in any field. Please plan to join us if you can!
If you would like to apply to participate, please send a position paper or extended abstract (no more than 1000 words) to casualinference@communitydata.cc. We plan to post a list of the best submissions.