Note: We have missed publishing blog posts about academic papers over the past few years. To ensure that my blog contains a more comprehensive record of our published papers and to surface these for folks who missed them, I will be periodically publishing blog posts about some “older” published projects.
It seems natural to think of online communities competing for the time and attention of their participants. Over the last few years, I’ve worked with a team of collaborators—led by Nathan TeBlunthuis—to use mathematical and statistical techniques from ecology to understand these dynamics. What we’ve found surprised us: competition between online communities is rare and typically short-lived.
When we started this research, we figured competition would be most likely among communities discussing similar topics. As a first step, we identified clusters of such communities on Reddit. One surprising thing we noticed in our Reddit data was that many of these communities that used similar language also had very high levels of overlap among their users. This was puzzling: why were the same groups of people talking to each other about the same things in different places? And why don’t they appear to be in competition with each other for their users’ time and activity?
We didn’t know how to answer this question using quantitative methods. As a result, we recruited and interviewed 20 active participants in clusters of highly related subreddits with overlapping user bases (for example, one cluster was focused on vintage audio).
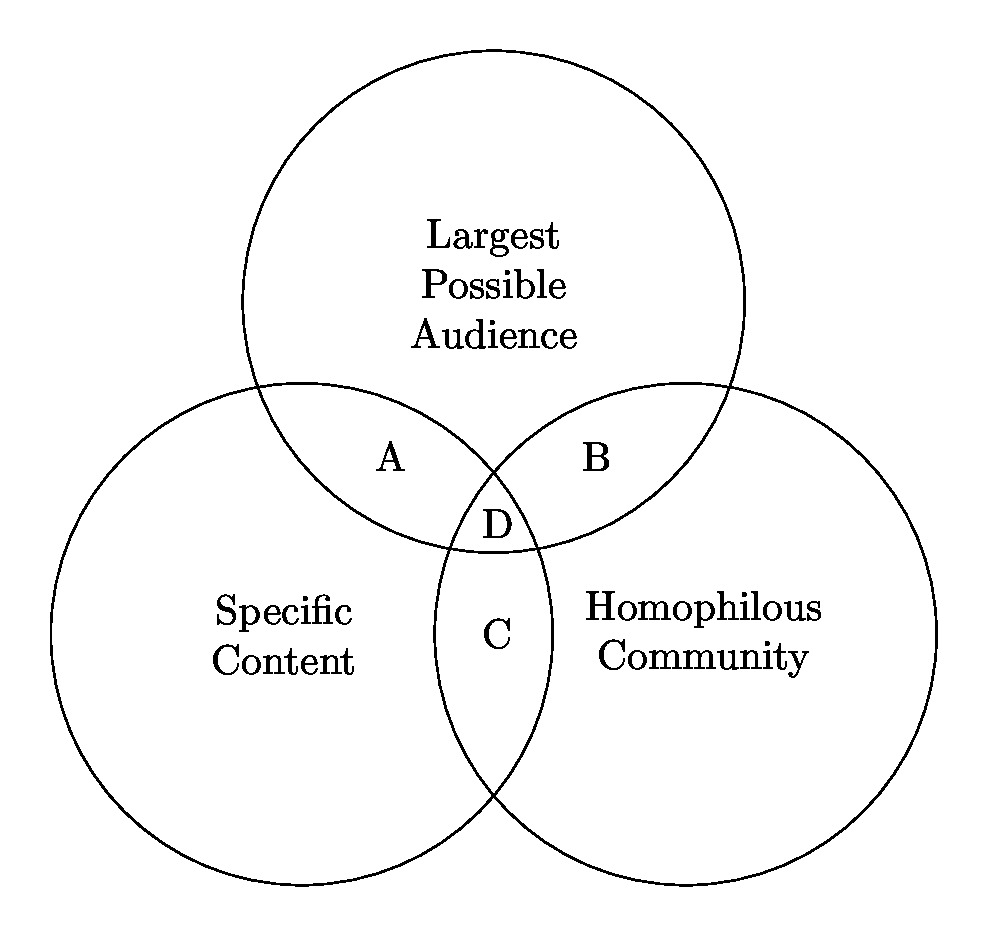
We found that the answer to the puzzle lay in the fact that the people we talked to were looking for three distinct things from the communities they worked in:
The ability to connect to specific information and narrowly scoped discussions.
The ability to socialize with people who are similar to themselves.
Attention from the largest possible audience.
Critically, we also found that these three things represented a “trilemma,” and that no single community can meet all three needs. You might find two of the three in a single community, but you could never have all three.
Figure from “No Community Can Do Everything: Why People Participate in Similar Online Communities” depicts three key benefits that people seek from online communities and how individual communities tend not to optimally provide all three. For example, large communities tend not to afford a tight-knit homophilous community.
The end result is something I recognize in how I engage with online communities on platforms like Reddit. People tend to engage with a portfolio of communities that vary in size, specialization, topical focus, and rules. Compared with any single community, such overlapping systems can provide a wider range of benefits. No community can do everything.
This work was published as a paper at CSCW: TeBlunthuis, Nathan, Charles Kiene, Isabella Brown, Laura (Alia) Levi, Nicole McGinnis, and Benjamin Mako Hill. 2022. “No Community Can Do Everything: Why People Participate in Similar Online Communities.” Proceedings of the ACM on Human-Computer Interaction 6 (CSCW1): 61:1-61:25. https://doi.org/10.1145/3512908.
This work was supported by the National Science Foundation (awards IIS-1908850, IIS-1910202, and GRFP-2016220885). A full list of acknowledgements is in the paper.
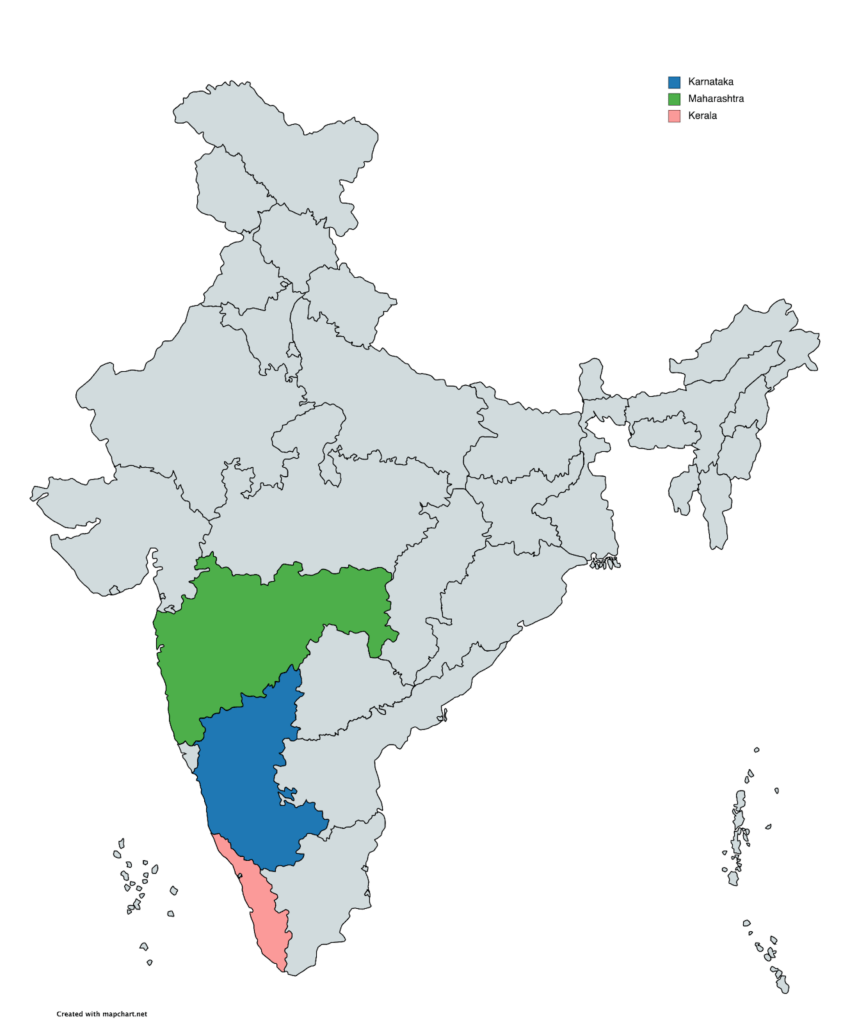
More than a billion people visit Wikipedia each month and millions have contributed as volunteers. Although Wikipedia exists in 300+ language editions, more than 90% of Wikipedia language editions have fewer than one hundred thousand articles. Many small editions are in languages spoken by small numbers of people, but the relationship between the size of a Wikipedia language edition and that language’s number of speakers—or even the number of viewers of the Wikipedia language editions—varies enormously. Why do some Wikipedias engage more potential contributors than others? We attempted to answer this question in a study of three Indian language Wikipedias that will be published and presented at the ACM Conference on Human Factors in Computing (CHI 2022).
To conduct our study, we selected 3 Wikipedia language communities that correspond to the official languages of 3 neighboring states of India: Marathi (MR) from the state of Maharashtra, Kannada (KN) from the state of Karnataka, and Malayalam (ML) from the state of Kerala (see the map in right panel of the figure above). While the three projects share goals, technological infrastructure, and a similar set of challenges, Malayalam Wikipedia’s community engaged its language speakers in contributing to Wikipedia at a much higher rate than the others. The graph above (left panel) shows that although MR Wikipedia has twice as many viewers as ML Wikipedia, ML has more than double the number of articles on MR.
Our study focused on identifying differentiating factors between the three Wikipedias that could explain these differences. Through a grounded theory analysis of interviews with 18 community participants from the three projects, we identified two broad explanations of a “positive participation cycle” in Malayalam Wikipedia and a “negative participation cycle” in Marathi and Kannada Wikipedias.
As the first step of our study, we conducted semistructured interviews with active participants of all three projects to understand their personal experiences and motivation; their perceptions of dynamics, challenges, and goals within their primary language community; and their perceptions of other language Wikipedia.
We found that MR and KN contributors experience more day-to-day barriers to participation than ML, and that these barriers hinder contributors’ day-to-day activity and impede engagement. For example, both MR and KN members reported a large number of content disputes that they felt reduced their desire to contribute.
But why do some Wikipedias like MR or KN have more day-to-day barriers to contribution like content disputes and low social support than others? Our interviews pointed to a series of higher-level explanations. For example, our interviewees reported important differences in the norms and rules used within each community as well as higher levels of territoriality and concentrated power structures in MR and KN.
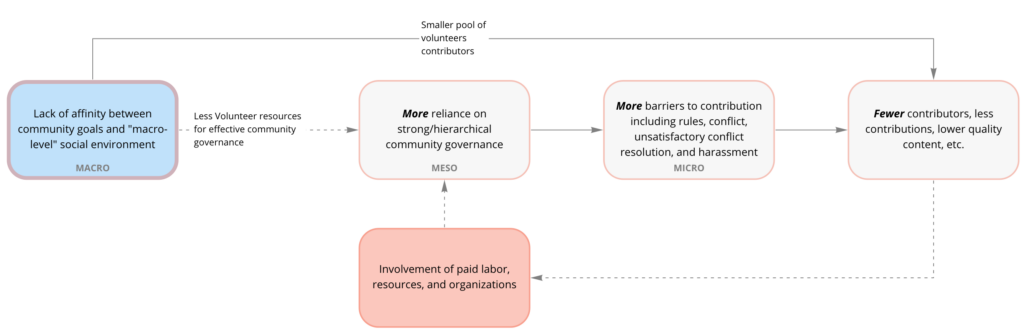
Once again, though: why do the MR and KN Wikipedias have these issues with territoriality and centralized authority structures? Here we identify a third, even higher-level set of differences in the social and cultural contexts of the three language-speaking communities. For example, MR and KN community members attributed low engagement to broad cultural attitudes toward volunteerism and differences in their language community’s engagement with free software and free culture.
The two flow charts above visualize the explanatory mapping of divergent feedback loops we describe. The top part of the figure illustrates how the relatively supportive macro-level social environment in Kerala led to a larger group of potential contributors to ML as well as a chain reaction of processes that led to a Wikipedia better able to engage potential contributors. The process is an example of a positive feedback cycle. The second, bottom part of the figure shows the parallel, negative feedback cycle that emerged in MR and KN Wikipedias. In these settings, features of the macro-level social environment led to a reliance on a relatively small group of people for community leadership and governance. This led, in turn, to barriers to entry that reduced contributions.
One final difference between the three Wikipedias was the role that paid labor from NGOs played. Because the MR and KN Wikipedias struggled to recruit and engage volunteers, NGOs and foundations deployed financial resources to support the development of content in Marathi and Kannada, but not in ML to the same degree. Our work suggested this tended to further concentrate power among a small group of paid editors in ways that aggravated the meso-level community struggles. This is shown in the red box in the second (bottom) row of the figure.
The results from our study provide a conceptual framework for understanding how the embeddedness of social computing systems within particular social and cultural contexts shape various aspects of the systems. We found that experience with participatory governance and free/open-source software in the Malayalam community supported high engagement of contributors. Counterintuitively, we found that financial resources intended to increase participation in the Marathi and Kannada communities hindered the growth of these communities. Our findings underscore the importance of social and cultural context in the trajectories of peer production communities. These contextual factors help explain patterns of knowledge inequity and engagement on the internet.
Please refer to the preprint of the paper for more details on the study and our design suggestions for localized peer production projects. We’re excited that this paper has been accepted to CHI 2022 and received the Best Paper Honorable Mention Award! It will be published in the Proceedings of the ACM on Human-Computer Interaction and presented at the conference in May. The full citation for this paper is:
Sejal Khatri, Aaron Shaw, Sayamindu Dasgupta, and Benjamin Mako Hill. 2022. The social embeddedness of peer production: A comparative qualitative analysis of three Indian language Wikipedia editions. In CHI Conference on Human Factors in Computing Systems (CHI ’22), April 29-May 5, 2022, New Orleans, LA, USA. ACM, New York, NY, USA, 18 pages. https://doi.org/10.1145/3491102.3501832
Attending the conference in New Orleans? Come attend our live presentation on May 3 at 3 pm at the CHI program venue, where you can discuss the paper with all the authors.
Should online communities require people to create accounts before participating?
This question has been a source of disagreement among people who start or manage online communities for decades. Requiring accounts makes some sense since users contributing without accounts are a common source of vandalism, harassment, and low quality content. In theory, creating an account can deter these kinds of attacks while still making it pretty quick and easy for newcomers to join. Also, an account requirement seems unlikely to affect contributors who already have accounts and are typically the source of most valuable contributions. Creating accounts might even help community members build deeper relationships and commitments to the group in ways that lead them to stick around longer and contribute more.
In a new paper published in Communication Research, Benjamin Mako Hill and Aaron Shaw provide an answer. We analyze data from “natural experiments” that occurred when 136 wikis on Fandom.com started requiring user accounts. Although we find strong evidence that the account requirements deterred low quality contributions, this came at a substantial (and usually hidden) cost: a much larger decrease in high quality contributions. Surprisingly, the cost includes “lost” contributions from community members who had accounts already, but whose activity appears to have been catalyzed by the (often low quality) contributions from those without accounts.
The full citation for the paper is: Hill, Benjamin Mako, and Aaron Shaw. 2020. “The Hidden Costs of Requiring Accounts: Quasi-Experimental Evidence from Peer Production.” Communication Research, 48 (6): 771–95. https://doi.org/10.1177/0093650220910345.
In exciting collective news, the US National Science Foundation announced that Benjamin Mako Hill has received of one of this year’s CAREER awards. The CAREER is the most prestigious grant that the NSF gives to early career scientists in all fields.
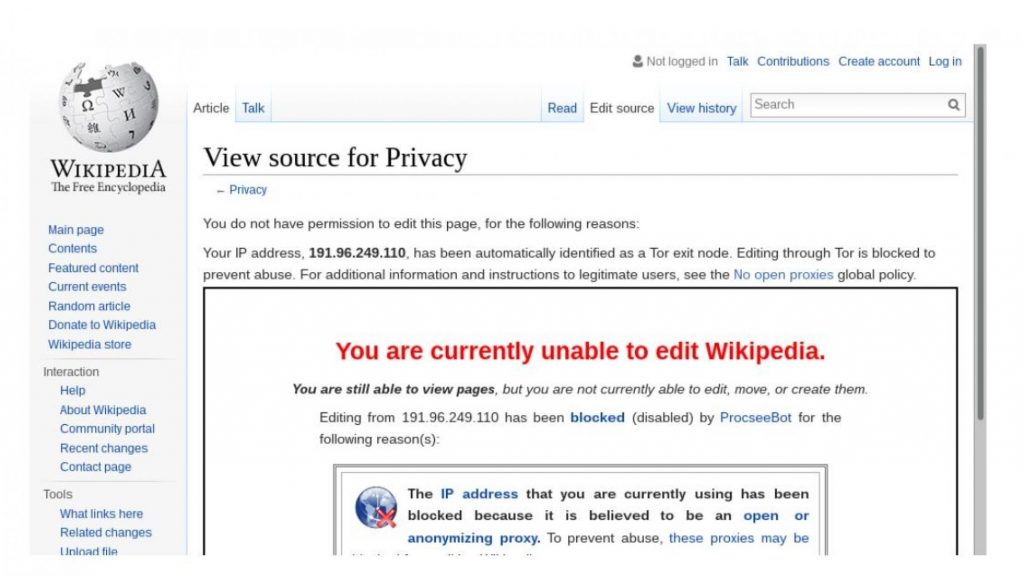
An image displaying the message that Tor users typically receive when trying to make edits on Wikipedia, stating that the user’s IP address has been identified as a Tor exit node, and that “editing through Tor is blocked to prevent abuse.”
Like everyone else, Internet users who protect their privacy by using the anonymous browsing software Tor are welcome to read Wikipedia. However, when Tor users try to contribute to the self-described “encyclopedia that anybody can edit,” they typically come face-to-face with a notice explaining that their participation is not welcome.
Our new paper—led by Chau Tran at NYU and authored by a group of researchers from the University of Washington, the Community Data Science Collective, Drexel, and New York University—was published and presented this week at the IEEE Symposium on Security & Privacy and provides insight into what Wikipedia might be missing out on by blocking Tor. By comparing contributions from Tor that slip past Wikipedia’s ban to edits made by other types of contributors, we find that Tor users make contributions to Wikipedia that are just as valuable as those made by new and unregistered Wikipedia editors. We also found that Tor users are more likely to engage with certain controversial topics.
One-minute “Trailer” for our paper and talk at the IEEE Symposium on Security & Privacy. Video was produced by Tommy Ferguson at the UW Department of Communication.
To conduct our study, we first identified more than 11,000 Wikipedia edits made by Tor users who were able to bypass Wikipedia’s ban on contributions from Tor between 2007 and 2018. We then used a series of quantitative techniques to evaluate the quality of these contributions. We found that Tor users made contributions that were similar in quality to, and in some senses even better than, contributions made by other users without accounts and newcomers making their first edits.
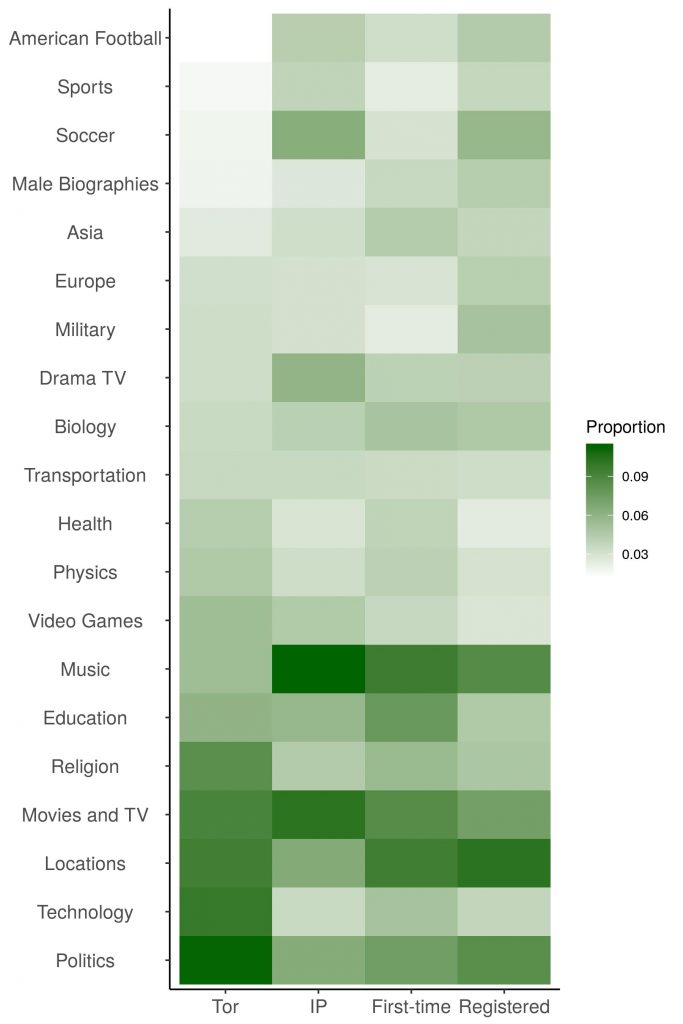
An image from the study showing the differences in topics edited by Tor users and other Wikipedia users. The image suggests that Tor users are more likely to edit pages discussing topics such as politics, religion, and technology. Other types of users, including IP, First-time, and Registered editors, are more likely to edit pages discussing topics such as music and sports.
We used a range of analytical techniques including direct parsing of article histories, manual inspections of article changes, and a machine learning platform called ORES to analyze contributions. We also used a machine learning technique called topic modeling to analyze Tor users’ areas of interest by checking their edits against clusters of keywords. We found that Tor-based editors are more likely than other users to focus on topics that may be considered controversial, such as politics, technology, and religion.
In a closely connected study led by Kaylea Champion and published several months ago in the Proceedings of the ACM on Human Computer Interaction (CSCW), we conducted a forensic qualitative analysis of contributions of the same dataset. Our results in that study are described in a separate blog post about that project and paint a complementary picture of Tor users engaged—in large part—in uncontroversial and quotidian types of editing behavior.
Across the two papers, our results are similar to other work that suggests that Tor users are very similar to other internet users. For example, one previous study has shown that Tor users frequently visit websites in the Alexa top one million.
Much of the discourse about anonymity online tends toward extreme claims backed up by very little in the way of empirical evidence or systematic study. Our work is a step toward remedying this gap and has implications for many websites that limit participation by users of anonymous browsing software like Tor. In the future, we hope to conduct similar systematic studies in contexts beyond Wikipedia.
Video of the conference presentation at the IEEE Symposium on Security & Privacy 2020 by Chau Tran.
In terms of Wikipedia’s own policy decisions about anonymous participation, we believe that our paper suggests that the benefits of a “pathway to legitimacy” for Tor contributors to Wikipedia might exceed the potential harm due to the value of their contributions. We are particularly excited about exploring ways to allow contributors from anonymity-seeking users under certain conditions: for example, requiring review prior to changes going live. Of course, these are questions for the Wikipedia community to decide but it’s a conversation that we hope our research can inform and that we look forward to participating in.
Paper Citation: Tran, Chau, Kaylea Champion, Andrea Forte, Benjamin Mako Hill, and Rachel Greenstadt. “Are Anonymity-Seekers Just like Everybody Else? An Analysis of Contributions to Wikipedia from Tor.” In 2020 IEEE Symposium on Security and Privacy (SP), 1:974–90. San Francisco, California: IEEE Computer Society, 2020. https://doi.org/10.1109/SP40000.2020.00053.
In May 2019, we were invited to give short remarks on the impact of Janet Fulk and Peter Monge at the International Communication Association‘s annual meeting as part of a session called “Igniting a TON (Technology, Organizing, and Networks) of Insights: Recognizing the Contributions of Janet Fulk and Peter Monge in Shaping the Future of Communication Research.”
Youtube: Mako Hill @ Janet Fulk and Peter Monge Celebration at ICA 2019
Mako Hill gave a four-minute talk on Janet and Peter’s impact to the work of the Community Data Science Collective. Mako unpacked some of the cryptic acronyms on the CDSC-UW lab’s whiteboard as well as explaining that our group has a home in the academic field of communication, in no small part, because of the pioneering scholarship of Janet and Peter. You can view the talk in WebM or on Youtube.
The conference marks the official publication of four papers by collective students and faculty. All four papers were published in the journal Proceedings of the ACM on Human-Computer Interaction: CSCW.
Information on the talks as well as links to the papers are available here (CSCW members are listed in italics):
Mon, Nov 11 14:30 – 16:00: A Forensic Qualitative Analysis of Contributions to Wikipedia from Anonymity-Seeking Users by Kaylea Champion (UW), Nora McDonald (Drexel), Stephanie E Bankes (Drexel), Joseph Zhang (Drexel), Rachel Greenstadt (NYU), Andrea Forte (Drexel), Benjamin Mako Hill (UW). Kaylea will present! [Paper]
Mon, Nov 11 14:30 – 16:00: Wikipedia and Wiki Research
Salt, Kaylea, Charlie, Regina, and Kaylea will all be at the conference as will affiliate Andrés Monroy-Hernández and tons of our social computing friends. Please come and say “Hello” to any of us, introduce yourself if you don’t already know us, and pick up a CDSC sticker!
Online anonymity often gets a bad rap and complaints about antisocial behavior from anonymous Internet users are as old as the Internet itself. On the other hand, research has shown that many Internet users seek out anonymity to protect their privacy while contributing things of value. Should people seeking to contribute to open collaboration projects like open source software and citizen science projects be required to give up identifying information in order to participate?
We conducted a two-part study to better understand how open collaboration projects balance the threats of bad behavior with the goal of respecting contributors’ expectations of privacy. First, we interviewed eleven people from five different open collaboration “service providers” to understand what threats they perceive to their projects’ mission and how these threats shape privacy and security decisions when it comes to anonymous contributions. Second, we analyzed discussions about anonymous contributors on publicly available logs of the English language Wikipedia mailing list from 2010 to 2017.
In the interview study, we identified three themes that pervaded discussions of perceived threats. These included threats to:
community norms, such as harrassment;
sustaining participation, such as loss of or failure to attract volunteers; and
contribution quality, low-quality contributions drain community resources.
We found that open collaboration providers were most concerned with lowering barriers to participation to attract new contributors. This makes sense given that newbies are the lifeblood of open collaboration communities. We also found that service providers thought of anonymous contributions as a way of offering low barriers to participation, not as a way of helping contributors manage their privacy. They imagined that anonymous contributors who wanted to remain in the community would eventually become full participants by registering for an account and creating an identity on the site. This assumption was evident in policies and technical features of collaboration platforms that barred anonymous contributors from participating in discussions, receiving customized suggestions, or from contributing at all in some circumstances. In our second study of the English language Wikipedia public email listserv, we discovered that the perspectives we encountered in interviews also dominated discussions of anonymity on Wikipedia. In both studies, we found that anonymous contributors were seen as “second-class citizens.”
This is not the way anonymous contributors see themselves. In a study we published two years ago, we interviewed people who sought out privacy when contributing to open collaboration projects. Our subjects expressed fears like being doxed, shot at, losing their job, or harassed. Some were worried about doing or viewing things online that violated censorship laws in their home country. The difference between the way that anonymity seekers see themselves and the way they are seen by service providers was striking.
One cause of this divergence in perceptions around anonymous contributors uncovered by our new paper is that people who seek out anonymity are not able to participate fully in the process of discussing and articulating norms and policies around anonymous contribution. People whose anonymity needs means they cannot participate in general cannot participate in the discussions that determine who can participate.
We conclude our paper with the observation that, although social norms have played an important role in HCI research, relying on them as a yardstick for measuring privacy expectations may leave out important minority experiences whose privacy concerns keep them from participating in the first place. In online communities like open collaboration projects, social norms may best reflect the most privileged and central users of a system while ignoring the most vulnerable
Both this blog post and the paper, Privacy, Anonymity, and Perceived Risk in Open Collaboration: A Study of Service Providers, was written by Nora McDonald, Benjamin Mako Hill, Rachel Greenstadt, and Andrea Forte and will be published in the Proceedings of the 2019 ACM CHI Conference on Human Factors in Computing Systems next week. The paper will be presented at the CHI conference in Glasgow, UK on Wednesday May 8, 2019. The work was supported by the National Science Foundation (awards CNS-1703736 and CNS-1703049).
I’ve heard a surprising “fact” repeated in the CHI and CSCW communities that receiving a best paper award at a conference is uncorrelated with future citations.
Although it’s surprising and counterintuitive, it’s a nice thing to
think about when you don’t get an award and its a nice thing to say to
others when you do. I’ve thought it and said it myself.
It also seems to be untrue. When I tried to check the “fact”
recently, I found a body of evidence that suggests that computing papers
that receive best paper awards are, in fact, cited more often than
papers that do not.
The source of the original “fact” seems to be a CHI 2009 study by Christoph Bartneck and Jun Hu titled “Scientometric Analysis of the CHI Proceedings.”
Among many other things, the paper presents a null result for a test of
a difference in the distribution of citations across best papers
awardees, nominees, and a random sample of non-nominees.
Although the award analysis is only a small part of Bartneck and Hu’s
paper, there have been at least two papers have have subsequently
brought more attention, more data, and more sophisticated analyses to
the question. In 2015, the question was asked by Jaques Wainer, Michael
Eckmann, and Anderson Rocha in their paper “Peer-Selected ‘Best Papers’—Are They Really That ‘Good’?“
Wainer et al. build two datasets: one of papers from 12 computer
science conferences with citation data from Scopus and another papers
from 17 different conferences with citation data from Google Scholar.
Because of parametric concerns, Wainer et al. used a non-parametric
rank-based technique to compare awardees to non-awardees. Wainer et al.
summarize their results as follows:
The probability that a best paper
will receive more citations than a non best paper is 0.72 (95% CI =
0.66, 0.77) for the Scopus data, and 0.78 (95% CI = 0.74, 0.81) for the
Scholar data. There are no significant changes in the probabilities for
different years. Also, 51% of the best papers are among the top 10% most
cited papers in each conference/year, and 64% of them are among the top
20% most cited.
Lee looked at 43,000 papers from 81 conferences and built a
regression model to predict citations. Taking into an account a number
of controls not considered in previous analyses, Lee finds that the
marginal effect of receiving a best paper award on citations is
positive, well-estimated, and large.
Why did Bartneck and Hu come to such a different conclusions than later work?
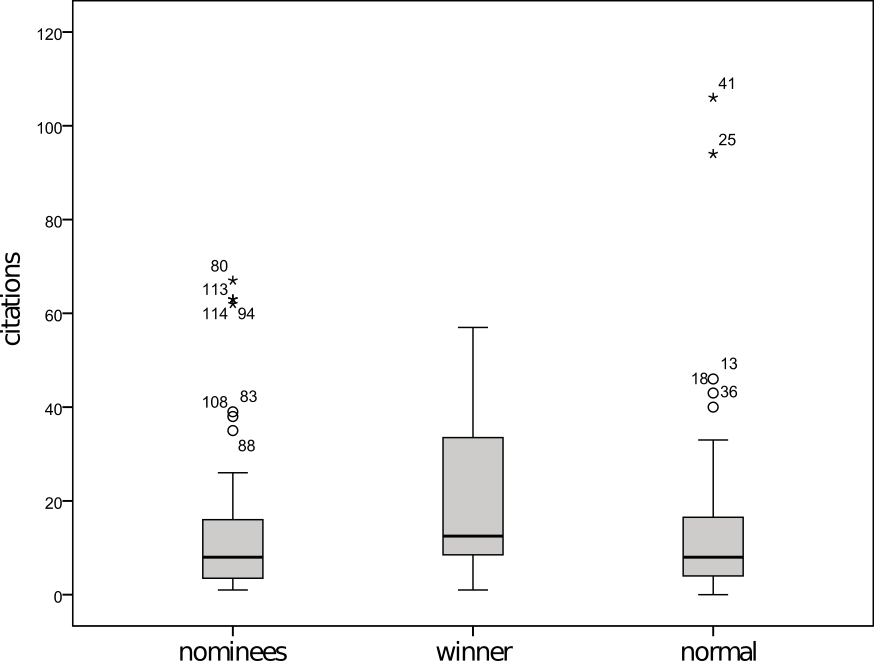
Distribution of citations (received by 2009) of CHI papers published between 2004-2007 that were nominated for a best paper award (n=64), received one (n=12), or were part of a random sample of papers that did not (n=76).
My first thought was that perhaps CHI is different than the rest of
computing. However, when I looked at the data from Bartneck and Hu’s
2009 study—conveniently included as a figure in their original study—you
can see that they did find a higher mean among the award
recipients compared to both nominees and non-nominees. The entire
distribution of citations among award winners appears to be pushed
upwards. Although Bartneck and Hu found an effect, they did not find a statistically significant effect.
Given the more recent work by Wainer et al. and Lee, I’d be willing
to venture that the original null finding was a function of the fact
that citations is a very noisy measure—especially over a 2-5
post-publication period—and that the Bartneck and Hu dataset was small
with only 12 awardees out of 152 papers total. This might have caused
problems because the statistical test the authors used was an omnibus
test for differences in a three-group sample that was imbalanced heavily
toward the two groups (nominees and non-nominees) in which their
appears to be little difference. My bet is that the paper’s conclusions
on awards is simply an example of how a null effect is not evidence of a
non-effect—especially in an underpowered dataset.
Of course, none of this means that award winning papers are better.
Despite Wainer et al.’s claim that they are showing that award winning
papers are “good,” none of the analyses presented can disentangle the
signalling value of an award from differences in underlying paper
quality. The packed rooms one routinely finds at best paper sessions at
conferences suggest that at least some additional citations received by
award winners might be caused by extra exposure caused by the awards
themselves. In the future, perhaps people can say something along these
lines instead of repeating the “fact” of the non-relationship.
This post was originally posted on Benjamin Mako Hill’s blog Copyrighteous.