Seymour Papert is credited as saying that tools to support learning should have “high ceilings” and “low floors.” The phrase is meant to suggest that tools should allow learners to do complex and intellectually sophisticated things but should also be easy to begin using quickly. Mitchel Resnick extended the metaphor to argue that learning toolkits should also have “wide walls” in that they should appeal to diverse groups of learners and allow for a broad variety of creative outcomes. In a new paper, Benjamin Mako Hill and I attempted to provide the first empirical test of Resnick’s wide walls theory. Using a natural experiment in the Scratch online community, we found causal evidence that “widening walls” can, as Resnick suggested, increase both engagement and learning.
Over the last ten years, the “wide walls” design principle has been widely cited in the design of new systems. For example, Resnick and his collaborators relied heavily on the principle in the design of the Scratch programming language. Scratch allows young learners to produce not only games, but also interactive art, music videos, greetings card, stories, and much more. As part of that team, I was guided by “wide walls” principle when I designed and implemented the Scratch cloud variables system in 2011-2012.
While designing the system, I hoped to “widen walls” by supporting a broader range of ways to use variables and data structures in Scratch. Scratch cloud variables extend the affordances of the normal Scratch variable by adding persistence and shared-ness. A simple example of something possible with cloud variables, but not without them, is a global high-score leaderboard in a game (example code is below). After the system was launched, I saw many young Scratch users using the system to engage with data structures in new and incredibly creative ways.
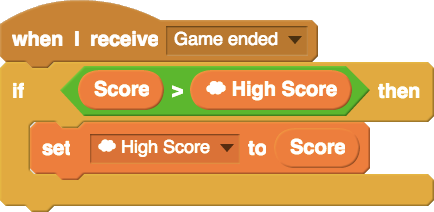
Although these examples reflected powerful anecdotal evidence, I was also interested in using quantitative data to reflect the causal effect of the system. Understanding the causal effect of a new design in real world settings is a major challenge. To do so, we took advantage of a “natural experiment” and some clever techniques from econometrics to measure how learners’ behavior changed when they were given access to a wider design space.
Understanding the design of our study requires understanding a little bit about how access to the Scratch cloud variable system is granted. Although the system has been accessible to Scratch users since 2013, new Scratch users do not get access immediately. They are granted access only after a certain amount of time and activity on the website (the specific criteria are not public). Our “experiment” involved a sudden change in policy that altered the criteria for who gets access to the cloud variable feature. Through no act of their own, more than 14,000 users were given access to feature, literally overnight. We looked at these Scratch users immediately before and after the policy change to estimate the effect of access to the broader design space that cloud variables afforded.
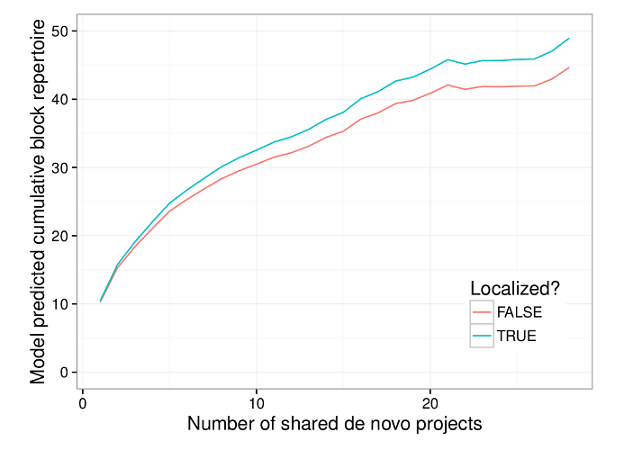
We found that use of data-related features was, as predicted, increased by both access to and use of cloud variables. We also found that this increase was not only an effect of projects that use cloud variables themselves. In other words, learners with access to cloud variables—and especially those who had used it—were more likely to use “plain-old” data-structures in their projects as well.
The graph below visualizes the results of one of the statistical models in our paper and suggests that we would expect that 33% of projects by a prototypical “average” Scratch user would use data structures if the user in question had never used used cloud variables but that we would expect that 60% of projects by a similar user would if they had used the system.
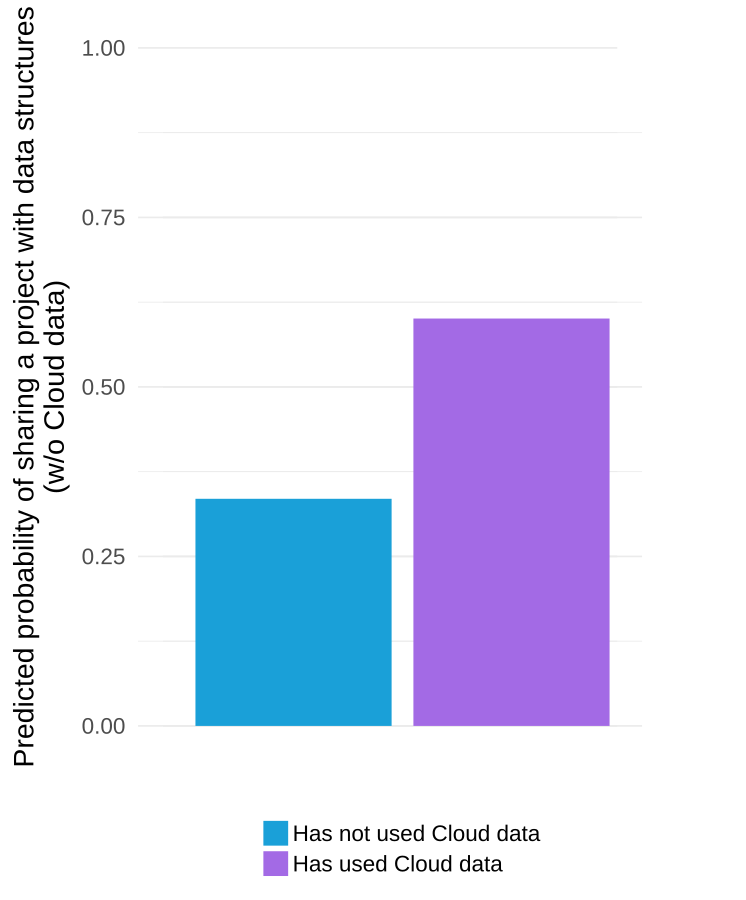
It is important to note that the estimated effective above is a “local average effect” among people who used the system because they were granted access by the sudden change in policy (this is a subtle but important point that we explain this in some depth in the paper). Although we urge care and skepticism in interpreting our numbers, we believe our results are encouraging evidence in support of the “wide walls” design principle.
Of course, our work is not without important limitations. Critically, we also found that rate of adoption of cloud variables was very low. Although it is hard to pinpoint the exact reason for this from the data we observed, it has been suggested that widening walls may have a potential negative side-effect of making it harder for learners to imagine what the new creative possibilities might be in the absence of targeted support and scaffolding. Also important to remember is that our study measures “wide walls” in a specific way in a specific context and that it is hard to know how well our findings will generalize to other contexts and communities. We discuss these caveats, as well as our methods, models, and theoretical background in detail in our paper which now available for download as an open-access piece from the ACM digital library.
This blog post, and the open access paper that it describes, is a collaborative project with Benjamin Mako Hill. Financial support came from the eScience Institute and the Department of Communication at the University of Washington. Quantitative analyses for this project were completed using the Hyak high performance computing cluster at the University of Washington.