The CDSC hosted the Science of Community Track on July 15th at FOSSY this year — it was an awesome day of learning and conversation with a fantastic group of senior scholars, industry partners, students, practitioners, community members, and more! We are so grateful and eager to build on the discussions we began.
If you missed the sessions, watch this space! Most sessions were recorded, and we’ll post links and materials as they’re released.
Special thanks to Molly de Blanc for all the long distance organizing work; Shauna Gordon McKeon for stepping in to help share some closing thoughts on the Science of Community track at the very last minute, and to the FOSSY organizing team for convening such a warm, welcoming inaugural event (indeed, the warmth was palpable as it nearly hit 100° F on Friday and Saturday in Portland).
One tangible result of a free software conference: new laptop stickers!
Although we might not notice it, much of the technology we rely on, from cell phones to cloud servers, is fueled by decades of effort by volunteers who create innovative software as well as the organizations necessary to sustain it. Despite this powerful legacy, we now are facing a crisis: not all of these critical components have been sufficiently maintained. Can we detect that an important software component is becoming neglected before major failures occur? Are these neglected packages just a matter of resources — old code and too few contributors — or can we see broader patterns that play a role, such as collaboration and organizational structures? Kaylea Champion has been working to answer these questions in her dissertation. As part of this work, she joined the software community metrics enthusiasts gathered at this year’s CHAOSSCon EU on September 12, 2022 as part of the Open Source Summit.
Kaylea’s presentation shares work in progress about the sources of underproduction, or when highly important packages see low quality development, in open software development. This presentation marks her second time at CHAOSSCon and builds on her work shared at last year’s conference in a lightning talk about detecting underproduction in Debian (see coverage of this work as presented to Debian folks here). Engaging with communities is a key part of this work: when we understand practitioner perspectives on underproduction and its causes, we can do science that supports taking immediate action. If you are interested in measuring the health of your collaborative community, let’s talk!
Crumbling infrastructure. J.C. Burns (jcburns) via flickr, CC BY-NC-ND 2.0
Critical software we all rely on can silently crumble away beneath us. Unfortunately, we often don’t find out software infrastructure is in poor condition until it is too late. Over the last year or so, I have been leading a project I announced earlier to measure software underproduction—a term I use to describe software that is low in quality but high in importance.
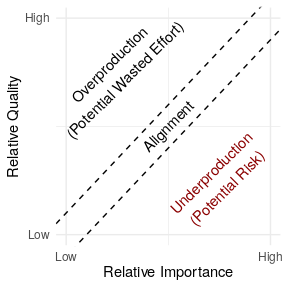
Underproduction reflects an important type of risk in widely used free/libre open source software (FLOSS) because participants often choose their own projects and tasks. Because FLOSS contributors work as volunteers and choose what they work on, important projects aren’t always the ones to which FLOSS developers devote the most attention. Even when developers want to work on important projects, relative neglect among important projects is often difficult for FLOSS contributors to see.
Conceptual diagram showing how our conception of underproduction relates to quality and importance of software.
In the paper—coauthored with Benjamin Mako Hill—we describe a general approach for detecting “underproduced” software infrastructure that consists of five steps: (1) identifying a body of digital infrastructure (like a code repository); (2) identifying a measure of quality (like the time to takes to fix bugs); (3) identifying a measure of importance (like install base); (4) specifying a hypothesized relationship linking quality and importance if quality and importance are in perfect alignment; and (5) quantifying deviation from this theoretical baseline to find relative underproduction.
To show how our method works in practice, we applied the technique to an important collection of FLOSS infrastructure: 21,902 packages in the Debian GNU/Linux distribution. Although there are many ways to measure quality, we used a measure of how quickly Debian maintainers have historically dealt with 461,656 bugs that have been filed over the last three decades. To measure importance, we used data from Debian’s Popularity Contest opt-in survey. After some statistical machinations that are documented in our paper, the result was an estimate of relative underproduction for the 21,902 packages in Debian we looked at.
One of our key findings is that underproduction is very common in Debian. By our estimates, at least 4,327 packages in Debian are underproduced. As you can see in the list of the “most underproduced” packages—again, as estimated using just one more measure—many of the most at risk packages are associated with the desktop and windowing environments where there are many users but also many extremely tricky integration-related bugs.
These 30 packages have the highest level of underproduction in Debian according to our analysis.
We hope these results are useful to folks at Debian and the Debian QA team. We also hope that the basic method we’ve laid out is something that others will build off in other contexts and apply to other software repositories.
Paper Citation: Kaylea Champion and Benjamin Mako Hill. 2021. “Underproduction: An Approach for Measuring Risk in Open Source Software.” In Proceedings of the IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER 2021). IEEE.
Contact Kaylea Champion (kaylea@uw.edu) with any questions or if you are interested in following up.