In the fifth talk of the Science of Community track at FOSSY 2025, Laura Langdon shared lessons learned from the early stages of building a network of academic Open Source Program Office’s (OSPO) across the University of California system. She discussed both the benefits and challenges encountered while developing this first-of-its-kind system-wide network.
This is the 5th of our 12 part series sharing highlights from the Science of Community track at FOSSY 2025. Visit the FOSSY site for bio details and a full abstract.
Our fourth speaker of the Science of Community, Cathy Richards, shared lessons learned from the Open Environmental Data Project (OEDP), focusing on how the toolkit translates open infrastructure into inclusive, practical frameworks that empower communities to use data for local action and advocacy.
This is the 4th of our 12 part series sharing highlights from the Science of Community track at FOSSY 2025. Visit the FOSSY site for bio details and a full abstract.
Mike Jang, the third talk of the Science of Community track at FOSSY 2025, covered how open sourcing existing software is more than just “pushing a button”, it involves things like auditing security, sharing with your community, setting ground rules, and more. Jang shared insights on how to access a template repository, a checklist to follow, tips for hackathons, and how to understand the work required to move to open source.
This is the 3rd of our 12 part series sharing highlights from the Science of Community track at FOSSY 2025. Visit the FOSSY site for bio details and a full abstract.
In the second talk of the Science of Community track, Dr. Justin Ribeiro discussed how development approaches shape creativity at the project level, drawing from a study of 40 open source projects, over 10,000 releases, and interview with developers across corporate and community-run efforts.
This is the second of our 12 part series sharing highlights from the Science of Community track at FOSSY 2025. Visit the FOSSY site for bio details and a full abstract.
Matt kicked off the Science of Community track on Friday, August 1st, discussing his current research on how the recent growth of sponsored open source libraries (projects stewarded by large, formally incorporated organizations) provides new organization relationships and processes to better understand FOSS libraries organized as communities of volunteer contributors.
(Matt’s talk starts at 16:30 and ends at 45:51).
This is the first of our 12 part series sharing highlights from the Science of Community track at FOSSY 2025. Visit the FOSSY site for bio details and a full abstract [https://2025.fossy.us/schedule/presentation/350/].
Let the countdown begin! FOSSY 2025 begins next week July 31st through August 3rd. We’ll be there, running the Science of Community track on Friday, August 1st and Saturday August 2nd.
The Science of Community track is inspired by the CDSC Science of Community Dialogues, which aim to bring together practitioners and researchers to discuss scholarly work that is relevant to the efforts of practitioners. As researchers, we get so much from the communities we work with and study and we want them to also learn from the research they so generously take part in. While the Dialogues cover a broad range of topics and communities, FOSSY presentations focus on how that work related to free and open source software communities, projects, and practitioners.
We have a number of great presenters, including the CDSC’s very own Matt Gaughan and Dr. Kaylea Champion. You can check our full schedule below:
Tickets are still available at every price tier, check them out here.
Interested in free and open source software? Want to hear insights from researchers, community leaders, contributors, and advocates working on and with FOSS?
We will be running the Science of Community track on Friday August 1st and Saturday August 2nd. We’re excited to have a number of awesome presenters speaking about their work. You can find the schedule here.
The Science of Community track is inspired by the CDSC Science of Community Dialogues, which aim to bring together practitioners and researchers to discuss scholarly work that is relevant to the efforts of practitioners. As researchers, we get so much from the communities we work with and study and we want them to also learn from the research they so generously take part in. While the Dialogues cover a broad range of topics and communities, FOSSY presentations focus on how that work related to free and open source software communities, projects, and practitioners.
Collaborations between practitioners and researchers can be transformative! Let’s get to know each other.
Tickets are still available at every price tier, check them out here.
Often, several different online communities exist where similar people talk about similar things. This is really easy to observe from browsing platforms like Reddit or Facebook groups.
Names of bicycle-related subreddits in cluster of subreddits with many overlapping users.
For example, as we can see from this visualization of clustered subreddits with overlapping users, there are many different subreddits related to cycling. We see some communities have different emphases in complementary ways like “fixedgearbicycle” and “bicycletouring” — these are different types of cycling. But why have a community for “cycling” and a different one for “bicycling”? A number of puzzles appear when we reflect on the existence of such related communities.
How do online communities relate to each other?
Why not have one large community that does everything?
How do people construct these systems of related online communities?
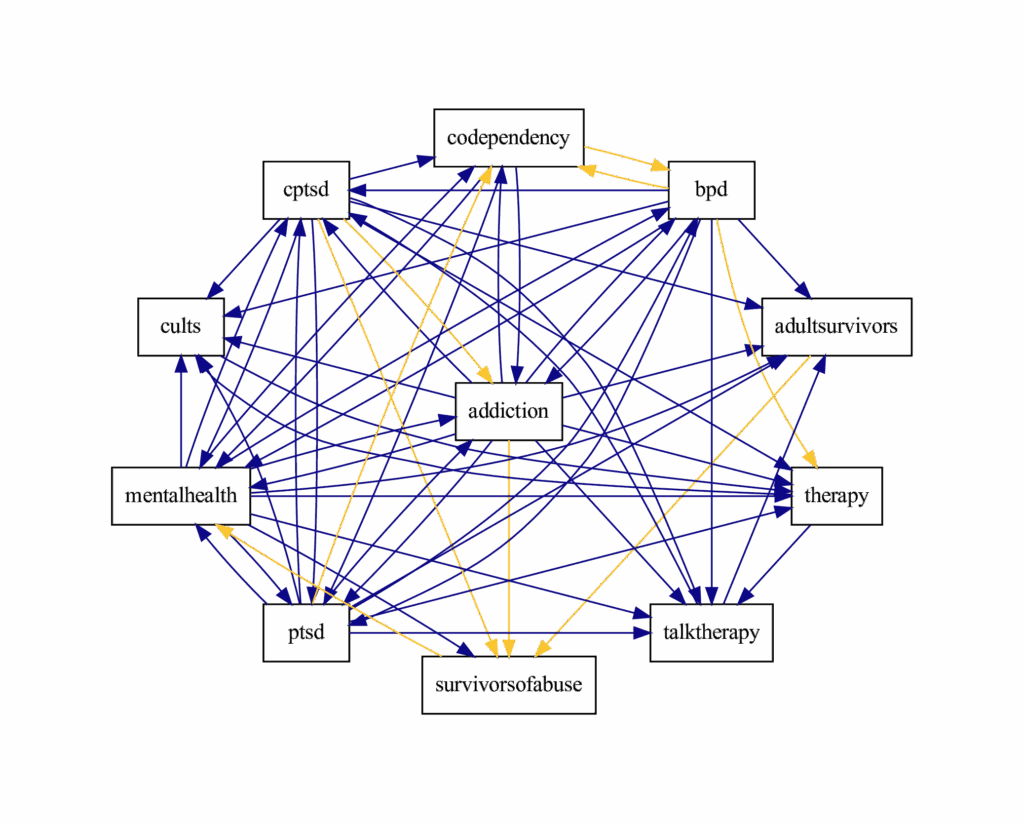
I investigated these questions in my dissertation using the theoretical lens of organizational ecology drawn from organizational sociology. This new paper explored some findings from earlier projects in more depth. The paper I published in ICWSM 2022 (pdf), takes up the question of ecological relationships among online communities. I used time series models to infer networks of competition and mutualism between overlapping online communities. This work found evidence that they tended to be mutualistic. For example, the diagram below shows a network of mental health subreddits that is dense with mutualism.
Ecological network of a cluster of mental subreddits. Blue arrows indicate mutualism and yellow arrows indicate competition according to a vector autoregression model.
However, this method, based on vector autoregression (VAR) models of activity, assumes that these relationships are static and constant over time. But dynamics of attention online are often bursty, and online communities grow, decline, and change over time in other ways. So, in this new work, I adopted nonlinear models called (regularized) S-map that can model more complex dynamics.
Since I found in the previous work that mutualism tended to happen more often than competition, I wanted to find out if that result was robust using the S-map. Since the S-map breaks these relationships down into episodes of competition or mutualism it afforded testing a more nuanced hypothesis about this tendency towards mutualism.
H1: Mutualistic interactions will be more frequent and longer lasting than competitive interactions.
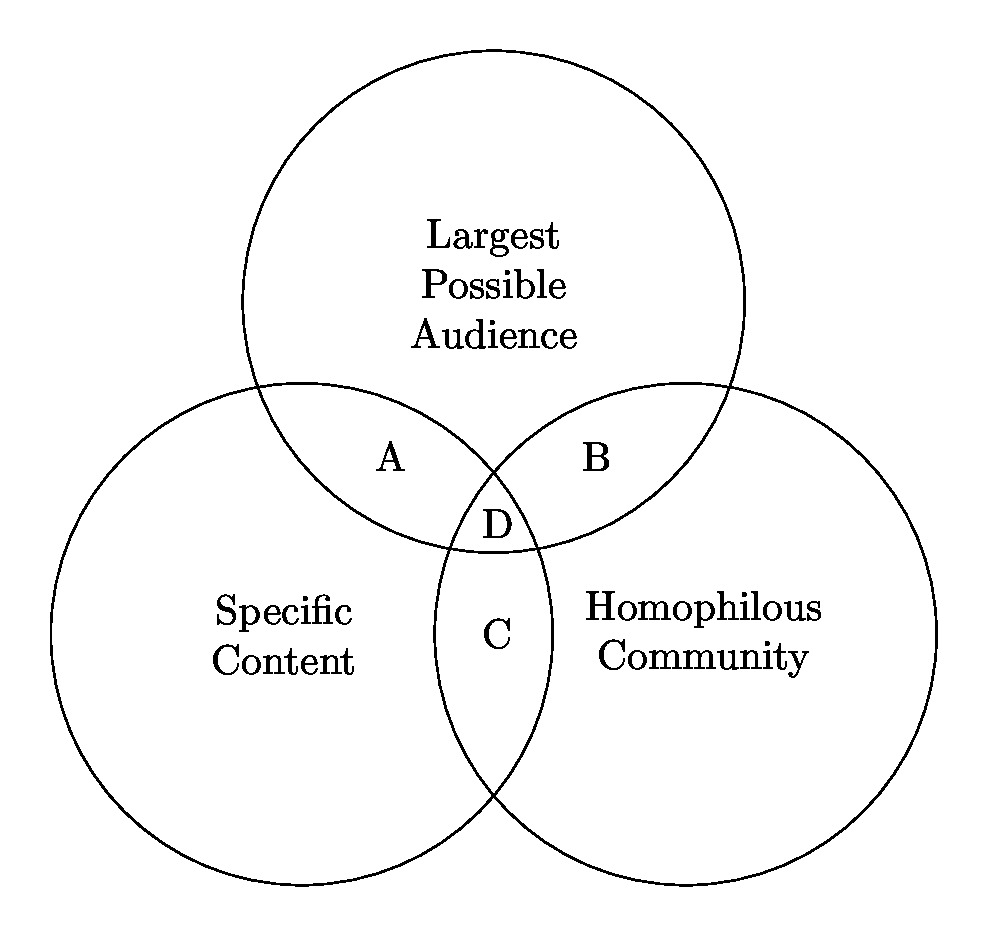
In the another empirical paper previously published at CSCW 2022 (acm dl), we focused on the question of why people build overlapping online communities and found that they complementary sets of benefits to members, as illustrated below. Trade-offs between the benefits lead to specialized roles for different types of communities.
Figure from “No Community Can Do Everything: Why People Participate in Similar Online Communities” depicts three key benefits that people seek from online communities and how individual communities tend not to optimally provide all three. For example, large communities tend not to afford tight-knit homophilous community.
This reflects propositions from ecology that specialization can be a strategy to avoid competition. The new study seeks to provide more generalizable quantitative evidence about how online communities find their specialized niches. Ecology theory suggests that online communities, similar to organizations or organisms, might adapt to increase specialization and thereby promote more mutualistic relationships. To investigate whether people build specialized online communities through such an adaptive feedback process, I set out to test the following two hypotheses:
H2: Two communities having greater competition (mutualism) will subsequently have greater decreases (increases) in overlap.
H3: Two subreddits having decreasing (increasing) overlap will subsequently have greater mutualism (competition).
Methods and measures
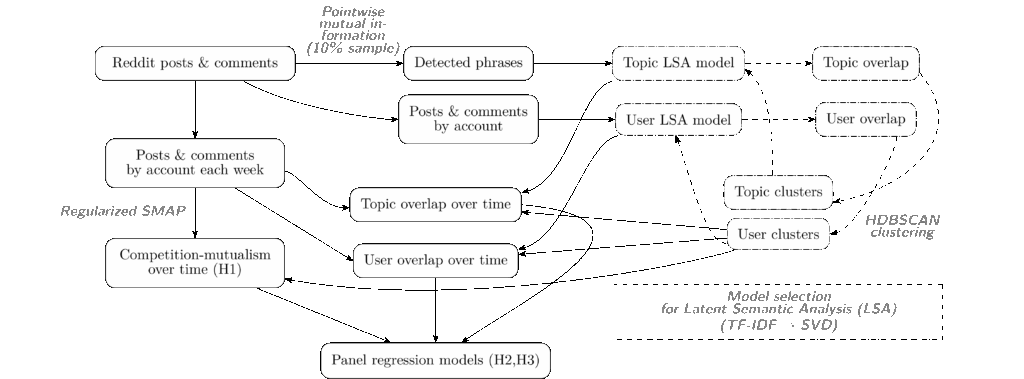
To test these three hypotheses, I had to measure competition/mutualism, and overlap within clusters of related subreddits over time. I made topic- and user-overlap measures based on a community embedding via the LSA algorithm. To create the clusters I reused the approach from the earlier paper by using the HDBSCAN algorithm based on user overlap. As mentioned above I used the Regularized S-MAP algorithm to create a dynamic measure of ecological influence. With these longitudinal measures in hand I could test the hypotheses using two-way fixed-effects panel data estimators with dyad-robust standard errors. That’s a brief and dense summary of the methods. The chart below might help you make sense of it, but if you care to fully understand you’ll want to check out the full paper.
This flowchart illustrates the dataset and measures in the study. On the left-hand side, nonline “Regularized S-Map models” are fit to time series of posts and comments in clusters of subreddits with high user-overlap to test hypothesis 1. In the middle, competition and mutualism from the S-Map models are used with longitidunal measures of topic and user overlap based on community embeddings in panel regression models to test hypotheses 2 and 3. Model selection is on the right-hand side.
Here are a few final notes on the data and methods. The data came from the Pushshift Reddit archive of submissions and comments from December 5th 2015 to April 13th 2020. I Started with the 19,533 subreddits that were active during at least 20% of study period weeks, excluding NSFW subreddits. HDBSCAN clustering discovered related 1,919 clusters of 8,806 subreddits having 48,484 relationships measured 17,374,116 times over 758 weeks.
Results
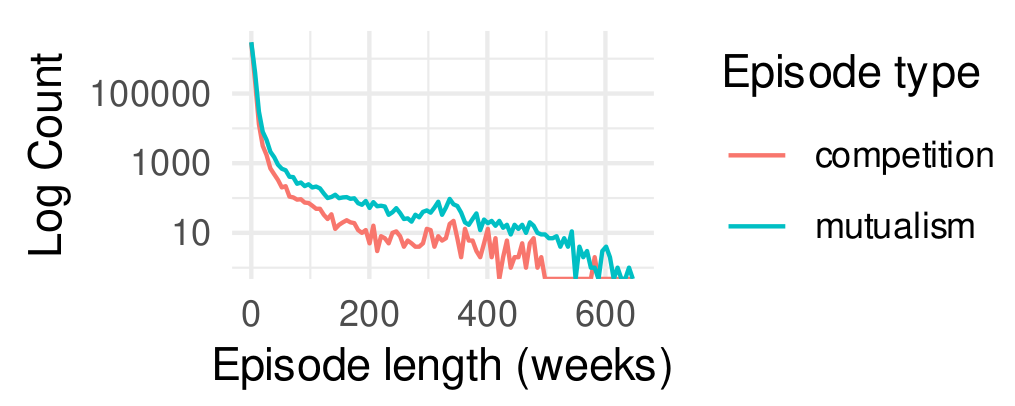
I found support for H1, which predicted that mutualistic interactions will be more frequent and longer lasting than competitive interactions. The plot below shows evidence in favor of the hypothesis. First, we can see clearly that the longest episodes tend to be mutualistic. Notably, these ecological relationships are often bursty and short-lived. The average length of a mutualistic episode was 2.13 weeks and the average length of a competitive episode was just 1.83 weeks.
Frequency plot of the durations of competition and mutualism episodes. Mutualism tends to last longer than competition. The y-axis is log-transformed. The axes truncated to omit outliers for visibility.
I also found support for H2, which predicted that I’d find positive coefficients for previous ecological interaction indicating that competition predicts decreases in overlap. Indeed, the panel regression models found that online communities tend to increase their specialization a bit in relatively competitive conditions, by about 0.02 standard deviations in term or user overlap for every 1-unit increase in competition.
Do increasingly specialized communities tend to decrease their competition as predicted by H3? My analysis didn’t find evidence for this. In fact, according to the panel regression models, after specialization increases, competition actually tends to increase as well.
Discussion
What to take away from all this? I still think the most important finding from this work to me is the robustness of the tendency toward mutualism among online communities. Unlike firms or other organizations that demand relatively exclusive commitments from their members, it is easy to participate in many online communities. Where classical organizations (imagine firms, churches, sports teams, nonprofit, and state organizations) seem likely to compete over employees, customers, or members online communities seem to benefit to some extant from sharing users with each other. I suspect this has to do with the ease with which nonrival content, ideas, and knowledge move between communities.
A second important takeaway from this work is that I think the evidence it finds for the adaptation explanation for the tendency toward mutualism isn’t all that convincing. Sure, communities in competition tend to become more specialized, but the effect size is pretty small and the fact that specialization doesn’t reduce competition suggests that it isn’t truly adaptive in the strongest sense. Put another way, specialized online communities might be made via an adaptive process, or they might be born out of the intentions and designs of their founders and early joiners. This work finds a bit of evidence for how specialization might be made, but the born process merits more investigation.
One clue about the significance of design for specialization comes from fellow CDSC-er Jeremy Foote‘s a nice CHI paper (acm dl) last year on how the early stages of a subreddit’s development are important to its trajectory and found that most subreddit creators didn’t set out to create a large community. Another study (arxiv.org), by Chenhao Tan on “community genealogy” shows how the growth of new subreddits often seems to depend on having high overlap with a “parent” subreddit. These papers don’t focus on specialization, but it would be cool to see future work take up these ideas.
If you enjoyed reading this summary or want to learn more, please check out the full paper. I got the chance to speculate a bit about what sorts of future technology designs might assist community leaders in crafting online communities to fill ecological roles. I also got to engage with ecological theory in a new way writing this. I hope you read and enjoy.
Finally, I wasn’t able to attend ICWSM in person this year, so I want to thank Kristen Engel for presenting on my behalf. I also want to note that CDSC-er Kaylea Champion and I were both recognized as “best reviewers” at the conference.
This work started as a chapter of my dissertation. Thanks to the committee — Professors Benjamin Mako Hill, Kirsten Foot, Aaron Shaw, David McDonald and Emma Spiro.
I also gratefully acknowledge support by NSF grants IIS-1908850 and IIS-1910202 and GRFP \#2016220885. This work was facilitated through the use of the advanced computational infrastructure provided by the Hyak supercomputer system at the University of Washington and TACC at the University of Texas.
Below, you can find the schedule of where our CDSC members will be:
Friday
10:30 – 11:45, HIGH-DENSITY: Advances and Best Practices in Text Classification: Computational Methods. Centennial A (Regency 3) (Benjamin Mako Hill will be the Session Chair)
13:30 – 14:45, Political Communication Poster Session: Political Communication. “The Politics of the Non-Political: A Scoping Review (2004–2024)” by Yufan Guo, Chinese U of Hong Kong, and Yibin Fan, University of Washington
13:30 – 14:45, HIGH-DENSITY: GIFTS in Instructional and Developmental Communication: Instructional and Developmental Communication. “Welcome Aboard: Simulating an Outsider-Within’s Organizational Assimilation and Socialization Through Role-Play” by Mavis Akom, Purdue U, Haley Sawyer, Purdue U, Loizos Bitsikokos, Purdue U, Alyssa Reed, Purdue U, Favour Ojike, Purdue U, Pamela Boateng, Purdue U, Onyinyechi Beatrice, Purdue U, Inusah Mohammed, Purdue U, Seungyoon Lee, Purdue U
Saturday
15:00 PM – 16:15, HIGH-DENSITY: Expression and Debates in Politics: “Unintended Politics: Partisan Opinion Expression and Incivility in Incidental Political Discussion” by Yibin Fan, U of Washington, Benjamin Mako Hill, U. of Washington, Patricia Moy, U. of Washington.
Sunday
12:00 – 13:15, Organizational Communication Research Escalator. “But Have You Tried to Ignore Them?” A Cross-National Comparison of Resilience Against Gendered Cyberhate in India and the USA by Bedadyuti Jha, Purdue U and Jeremy Foote, Purdue U.
15:00 – 16:15, Intergroup Communication Top Papers. Effects of Racial Minority Language Use on the Conversational Sustenance of Online Discussions by Haomin Lin, University of Washington, and Wang Liao, University of Washington.
Monday
10:30 – 11:45, NEKO-tiating Later Life: Digital Health, News Habits, and Tech Support: Communication and Technology. “Gig Work in Later Life: Sociodemographic and Digital Determinants of Older Adults’ Participation” by Floor Fiers, U of Amsterdam, Will Marler, Tilburg U, and Eszter Hargittai, U of Zurich.
Also, congratulations to Dr. Kaylea Champion, as her dissertation, “Social and Technical Sources of Risk in Sustaining Digital Infrastructure,” will be given the 2025 Annie Lang Dissertation Award from the International Communication Association Information Systems Division. The award will be given out at the ICA 2025 Information Systems business meeting 16:30 – 17:45 in Granite (Regency 3). Kaylea’s dissertation also received the 2025 Faculty Award for Outstanding Research Ph.D. Dissertation Award from the Department of Communication University of Washington. You can read more about Kaylea and her research on her homepage here.
Congrats to our CDSC folks on their accomplishments, and have safe travels to Denver this weekend!
CDSC member Kaylea Champion’s dissertation, “Social and Technical Sources of Risk in Sustaining Digital Infrastructure,” has been selected for two awards: the 2025 Annie Lang Dissertation Award from the International Communication Association Information Systems Division, and the 2025 Faculty Award for Outstanding Research – Ph.D. Dissertation Award from the Department of Communication University of Washington.
Kaylea’s dissertation develops new methods to measure and understand risks to our shared digital infrastructure–including platforms, communication systems, the web, and the cloud. Digital infrastructure faces a form of risk called underproduction–highly important, but low-quality software. She argues we can identify this risk by examining the social and technical conditions of software production communities.
Using analysis methods she developed and validated, she found thousands of at-risk software packages. These packages are often old, or written in older languages. However, simply directing more resources toward software maintenance may not be enough: at-risk packages are more likely to be maintained by larger numbers of people and by people who are already highly active in the development community. She identified two factors associated with lower risk: empowerment and retention. Kaylea’s work joins a growing base of scholarship across the CDSC focusing attention toward contributors as a key part of building thriving peer production communities for the benefit of the greater public.
Kaylea will join the faculty of the University of Washington Bothell as an Assistant Professor in the Division of Computing and Software Systems, School of STEM, in Fall 2025.