CDSC member Kaylea Champion’s dissertation, “Social and Technical Sources of Risk in Sustaining Digital Infrastructure,” has been selected for two awards: the 2025 Annie Lang Dissertation Award from the International Communication Association Information Systems Division, and the 2025 Faculty Award for Outstanding Research – Ph.D. Dissertation Award from the Department of Communication University of Washington.
Kaylea’s dissertation develops new methods to measure and understand risks to our shared digital infrastructure–including platforms, communication systems, the web, and the cloud. Digital infrastructure faces a form of risk called underproduction–highly important, but low-quality software. She argues we can identify this risk by examining the social and technical conditions of software production communities.
Using analysis methods she developed and validated, she found thousands of at-risk software packages. These packages are often old, or written in older languages. However, simply directing more resources toward software maintenance may not be enough: at-risk packages are more likely to be maintained by larger numbers of people and by people who are already highly active in the development community. She identified two factors associated with lower risk: empowerment and retention. Kaylea’s work joins a growing base of scholarship across the CDSC focusing attention toward contributors as a key part of building thriving peer production communities for the benefit of the greater public.
Kaylea will join the faculty of the University of Washington Bothell as an Assistant Professor in the Division of Computing and Software Systems, School of STEM, in Fall 2025.
Does your work touch open source, communities, technology, or cooperation? Do you want to help bridge the gaps between research and practice? Join us at FOSSY! The Free and Open Source Software Yearly conference (FOSSY) is back this summer and the call for proposals is open!
We’ll be running the Science of Community track, and are looking for presenters to speak to an audience of FOSS practitioners, developers, community organizers, contributors, and people just generally into and curious about FOSS.
The Science of Community track is inspired by the CDSC Science of Community Dialogues, which bring together practitioners and researchers to discuss scholarly work that is relevant to the efforts of practitioners. As researchers, we benefit so much from the communities we work with and study and we want them to also learn from the research they so generously take part in. While the Dialogues cover a broad range of topics and communities, FOSSY presentations will focus on how that work relates to free and open source software communities, projects, and practitioners.
FOSSY is a low-stress opportunity to talk to people who your work can benefit. For topics, consider presenting implications from past papers, synthesizing work from your field overall, or floating ideas and problems (lightning talks! long talks! short talks!). A full track description and answers to common questions is available on our wiki.
How can we create more trustworthy and accountable social media that support diverse communities? Decentralized social media—systems that allow users to connect and communicate across independent services like Mastodon or BlueSky—offer promising alternatives to centralized commercial platforms like Instagram, TikTok, or X. However, decentralized social media also face urgent design challenges, especially when it comes to content integrity, protecting community trust and safety, and forging collective governance. What happens when there is no central authority to review posts or ban abusive users? How can networks of autonomous communities build and adopt systems to govern effectively? What critical infrastructure can prevent the pervaisve harms of existing social media and support the integrity of public discourse?
Join Northwestern’s Center for Human-Computer Interaction + Design (HCI+D) and the Community Data Science Collective (CDSC) for an engaging conversation about the challenges and opportunites of decentralized social media on May 23rd from 4 to 5:15 p.m. CST. This panel features designers, leaders, and researchers involved in federated social media and will address opportunities for effective design and governance in this space.
Panelists include Jaz-Michael King, Bryan Newbold, and Christine Lemmer-Webber. Short presentations will be followed by discussion and Q&A moderated by Aaron Shaw (Northwestern HCI+D, CDSC).
Moderator: Aaron Shaw, photograph by Nikki Ritcher Photography
Speaker: Christine Lemmer-Webber, Executive Director of Spritely Networked Communities Institute
Christine has devoted her life to advancing user freedom. Realizing that the federated social web was fractured by a variety of incompatible protocols, she co-authored and shepherded ActivityPub‘s standardization. She has also contributed to many other free and open source projects, including co-founding MediaGoblin.
Christine established the open source Spritely Project to solve known problems in existing centralized and decentralized social media platforms and to re-imagine the way we build networked applications – work that now continues here at the institute under her guidance as Executive Director.
Speaker: Jaz-Michael King, Executive Director of IFTAS (Federated Trust & Safety)
An accomplished professional with an extraordinary record of enabling data-driven decisions, developing innovative products, creating new business opportunities, driving strong operational performance, and building high-performing, agile teams. Highly versatile, with extensive experience in data and technology from a privacy, improvement, and reporting perspective, Jaz has a proven record in building solutions for non-profit programs. As Executive Director of IFTAS, Jaz is now focused on independent, open Social Web activities, with the aim of creating #BetterSocialMedia by supporting trust and safety at scale in federated social media networks.
Speaker: Bryan Newbold, Protocol Engineer at BlueSky
Bryan works at Bluesky, a startup company building a federated social media protocol called “atproto”. Until a few months ago he worked at the Internet Archive collecting scientific research datasets and publications, and created scholar.archive.org. And before that he worked on infrastructure at Stripe, attended the Recurse Center in New York City, and built Atomic Magnetometers for a small New Jersey company called Twinleaf.
Over that same time period, Bryan climbed up and down the ladder of abstraction, obtaining an undergraduate degree in physics (at MIT), operating under-ice robots in Antarctica, developing open hardware lab instrumentation for large-scale brain probing (at LeafLabs), cataloging hundreds of millions of electronics components (at Octopart), and improved production service reliability at Stripe (a financial infrastructure start-up).
Bryan is a transplant from the East Coast and enjoys the road biking, large trees, generous salads, used bookstores, and world-class tech non-profits. This will be his third year serving on the Code of Conduct team at DWeb Camp.
Madison Deyo has recently joined the CDSC as a Program Coordinator and we couldn’t be more thrilled to welcome her to the team!
Madison is based at Northwestern. With the CDSC, Madison’s role includes a mix of event planning and coordination; outreach and communications; and supporting the operations of the group. She also works with the Northwestern Center for Human-Computer Interaction + Design. Madison brings experience working with community-based non-profits in several different capacities.
Madison currently lives in Chicago, and grew up in Wisconsin, where she attended the University of Wisconsin-Madison. There, she received my B.S. in Art (with a focus on illustration) and Communications: Radio-TV-Film. In addition to her position at Northwestern, Madison also works as a freelance artist designing mead labels, tattoos, and occasionally album/EP covers. You can check out her portfolio.
Wikimania, the annual global conference of the Wikimedia movement, took place in Singapore last month. For the first time since 2019, the conference was held in person again. It was attended by over 670 people in-person and more than 1,500 remotely.
At the conference, Benjamin Mako Hill, Tilman Bayer, and Miriam Redi presented “The State of Wikimedia Research: 2022–2023”, an overview of scholarship and academic research on Wikipedia and other Wikimedia projects from the last year. This resumed an annual Wikimania tradition started by Mako back in 2008 as a graduate student, aiming to provide “a quick tour … of the last year’s academic landscape around Wikimedia and its projects geared at non-academic editors and readers.” With hundreds of research publications every year featuring Wikipedia in their title (and more recently, Wikidata too), is it of course impossible to cover all important research results within one hour. Hence our presentation aimed to identify a set of important themes that attracted researchers’ attention during the past year, and illustrate each theme with a brief “research postcard” summary of one particular publication. Unfortunately, Miriam was not able to be in Singapore to present..
This year’s presentation focused on seven such research themes:
Theme 2. Wikidata as a community While Wikidata is the subject of over 100 published studies each year, the vast majority of these have been primarily concerned with the project’s content as a database which scientists use to advance research about e.g. the semantic web, knowledge graphs and ontology management. This year also saw several papers studying Wikidata as a community, including a study of how Wikidata contributors use talk page to coordinate (preprint).
Theme 4. Rules and governance Research on rules and governance continues to attract researchers’ attention. Here, we featured a new paper by a political scientist that documented important changes in how English Wikipedia’s NPoV (Neutral Point of View) policy has been applied over time, and used this to advance an explanation for political change in general.
Theme 6. Measuring Wikipedia’s own content bias Despite the huge interest in content gaps along dimensions such as race and gender, systematic approaches to measuring them have not been as frequent as one might hope. We featured a paper that advanced our understanding in this regard, presented a useful method, and is also one of the first to study differences in intersectional identities.
Theme 7. Critical and humanistic approaches Although most of the published research work related to Wikipedia is based in the sciences or engineering disciplines, a growing body of humanities scholarship can offer important insights as well. We highlighted a recent humanities paper about the measuring of race and ethnicity gaps on Wikipedia, which focused in particular on gaps in such measurements themselves, placing them into a broader social context.
Again, this work represents just a tiny fraction of what has been published about Wikipedia in the last year. In particular, we avoided research that was presented elsewhere in Wikimania’s research track.
It’s Ph.D. application season and the Community Data Science Collective is recruiting! As always, we are looking for talented people to join our research group. Applying to one of the Ph.D. programs that the CDSC faculty members are affiliated with is a great way to get involved in research on communities, collaboration, and peer production.
Because we know that you may have questions for us that are not answered in this webpage, we will be hosting a panel discussion and Q&A about the CDSC and Ph.D. opportunities on October 20 at 7:30pm UTC (3:30pm US Eastern, 2:30pm US Central, 12:30pm US Pacific). You can register online.
This post provides a very brief run-down on the CDSC, the different universities and Ph.D. programs our faculty members are affiliated with, and some general ideas about what we’re looking for when we review Ph.D. applications.
Group photo of the collective at a recent virtual retreat.
What are these different Ph.D. programs? Why would I choose one over the other?
This year the group includes three faculty principal investigators (PIs) who are actively recruiting PhD students: Aaron Shaw (Northwestern University), Benjamin Mako Hill (University of Washington in Seattle), and Jeremy Foote (Purdue University). Each of these PIs advise Ph.D. students in Ph.D. programs at their respective universities. Our programs are each described below.
Although we often work together on research and serve as co-advisors to students in each others’ projects, each faculty person has specific areas of expertise and interests. The reasons you might choose to apply to one Ph.D. program or to work with a specific faculty member could include factors like your previous training, career goals, and the alignment of your specific research interests with our respective skills.
At the same time, a great thing about the CDSC is that we all collaborate and regularly co-advise students across our respective campuses, so the choice to apply to or attend one program does not prevent you from accessing the expertise of our whole group. But please keep in mind that our different Ph.D. programs have different application deadlines, requirements, and procedures!
Who is actively recruiting this year?
If you are interested in applying to any of the programs, we strongly encourage you to reach out the specific faculty in that program before submitting an application.
Ph.D. Advisors
Benjamin Mako Hill
Benjamin Mako Hill is an Associate Professor of Communication at the University of Washington. He is also an Adjunct Assistant Professor at UW’s Department of Human-Centered Design and Engineering (HCDE), Computer Science and Engineering (CSE) and Information School. Although many of Mako’s students are in the Department of Communication, he has also advised students in all three other departments—although he typically has more limited ability to admit students into those programs on his own and usually does so with a co-advisor in those departments. Mako’s research focuses on population-level studies of peer production projects, computational social science, efforts to democratize data science, and informal learning. Mako has also put together a webpage for prospective graduate students with some useful links and information..
AaronShaw is an Associate Professor in the Department of Communication Studies at Northwestern. This year, he’s also the “Scholar in Residence” for King County, Washington. In terms of Ph.D. programs, Aaron’s primary affiliations are with the Media, Technology and Society (MTS) and the Technology and Social Behavior (TSB) Ph.D. programs (please note: the TSB program is a joint degree between Communication and Computer Science). Aaron also has a courtesy appointment in the Sociology Department at Northwestern, but he has not directly supervised any Ph.D. advisees in that department (yet). Aaron’s current projects focus on comparative analysis of the organization of peer production communities and social computing projects, participation inequalities in online communities, and collaborative organizing in pursuit of public goods.
Jeremy Foote
Jeremy Foote is an Assistant Professor at the Brian Lamb School of Communication at Purdue University. He is affiliated with the Organizational Communication and Media, Technology, and Society programs. Jeremy’s current research focuses on how individuals decide when and in what ways to contribute to online communities, how communities change the people who participate in them, and how both of those processes can help us to understand which things become popular and influential. Most of his research is done using data science methods and agent-based simulations.
What do you look for in Ph.D. applicants?
There’s no easy or singular answer to this. In general, we look for curious, intelligent people driven to develop original research projects that advance scientific and practical understanding of topics that intersect with any of our collective research interests.
To get an idea of the interests and experiences present in the group, read our respective bios and CVs (follow the links above to our personal websites). Specific skills that we and our students tend to use on a regular basis include consuming and producing social science and/or social computing (human-computer interaction) research; applied statistics and statistical computing, various empirical research methods, social theory and cultural studies, and more.
Formal qualifications that speak to similar skills and show up in your resume, transcripts, or work history are great, but we are much more interested in your capacity to learn, think, write, analyze, and/or code effectively than in your credentials, test scores, grades, or previous affiliations. It’s graduate school and we do not expect you to show up knowing how to do all the things already.
Intellectual creativity, persistence, and a willingness to acquire new skills and problem-solve matter a lot. We think doctoral education is less about executing tasks that someone else hands you and more about learning how to identify a new, important problem; develop an appropriate approach to solving it; and explain all of the above and why it matters so that other people can learn from you in the future. Evidence that you can or at least want to do these things is critical. Indications that you can also play well with others and would make a generous, friendly colleague are really important too.
All of this is to say, we do not have any one trait or skill set we look for in prospective students. We strive to be inclusive along every possible dimension. Each person who has joined our group has contributed unique skills and experiences as well as their own personal interests. We want our future students and colleagues to do the same.
Now what?
Still not sure whether or how your interests might fit with the group? Still have questions? Still reading and just don’t want to stop? Follow the links above for more information. Feel free to send at least one of us an email. We are happy to try to answer your questions and always eager to chat. You can also join our panel discussion on October 20 at 3:30pm ET (UTC-5).
The International Communication Association (ICA)’s 72nd annual conference is coming up in just a couple of weeks. This year, the conference takes place in Paris and a subset of our collective is flying out to present work in person. We are looking forward to meeting up, talking research, and eating croissants. À bientôt!
ICA takes place from Thursday, May 26th to Monday, May 30th, and we are presenting a total of ten (!!) times. All presentations given by members of the collective are scheduled between Friday and Sunday.
Friday
We start off with a presentation by Nathan TeBlunthuis on Friday at 11.00 AM, in Room 351 M (Palais des Congres). In a high-density paper session on Computational Approaches to Online Communities, Nate will present a paper entitled “Dynamics of Ecological Adaptation in Online Communities.”
Later that same day, at 3.30 PM in the Amphitheatre Havana (level 3; Palais des Congres), Carl Colglazier will discuss a paper that he collaborated on with Nick Diakopoulos: “Predictive Models in News Coverage of the COVID-19 Pandemic in the U.S.” This paper session is part of the ICA division Journalism Studies.
Saturday
On Saturday, Floor Fiers will present in the paper session “Impression Management Online: FabriCATing An Image.” Their project, which they wrote with Nathan Walter, discusses “Comments on Airbnb and the Potential for Racial Bias” at 2.00 PM in Regency 1 (Hyatt).
Shortly after, that same afternoon, you’ll find two of our poster presentations at 5.00 PM in the Exhibit Hall (Havana; Palais des Congres, level 3). In one of them, Jeremy Foote will discuss his take on “a systems approach to studying online communities.”
The other poster, presented at the same time and place, is by Kaylea Champion and Benjamin Mako Hill on “Resisting Taboo in the Collaborative Production of Knowledge: Evidence from Wikipedia.”
Sunday
Most of our presentations are on the fourth day of the conference. At 9.30 AM, we’ll be presenting in three locations at the same time! First, Floor will discuss their paper “Inequality and Discrimination in the Online Labor Market: a Scoping Review” in Room 311+312 (Palais des Congres). This presentation is part of the paper session “All Things Are Not Equal: CompliCATions From Digital Inequalities.”
Second, Carl will present work on behalf of himself, Aaron Shaw, and Benjamin Mako Hill during a high-density paper session in Room 242A (Palais des Congres). The title of their project is “Extended Abstract: Exhaustive Longitudinal Trace Data From Over 70,000 Wiki.”
Lastly, at the same time in Room 352B (Palais des Congres), Jeremy will present an interview study entitled “What Communication Supports Multifunctional Public Goods in Organizations? Using Agent-Based Modeling to Explore Differential Uses of Enterprise Social Media.” Jeremy’s co-authors on this paper are Jeffrey Treem and Bart van den Hooff.
On Sunday afternoon, at 3.30 PM in Room 311+312 (Palais des Congres), Tiwaladeoluwa Adekunle will talk about a qualitative project she collaborated on with Jeremy, Nate, and Laura Nelson: “Co-Creating Risk Online: Exploring Conceptualizations of COVID-19 Risk in Ideologically Distinct Online Communities.”
We will finish off our ICA 2022 presentations at 5.00 PM in Room 313+314 (Palais des Congres), where Kaylea will present on behalf of Isabella Brown, Lucy Bao, Jacinta Harshe, and Mako. The title of their paper is “Making Sense of Covid-19: Search Results and Information Providers”.
We look forward to sharing our research and connecting with you at ICA!
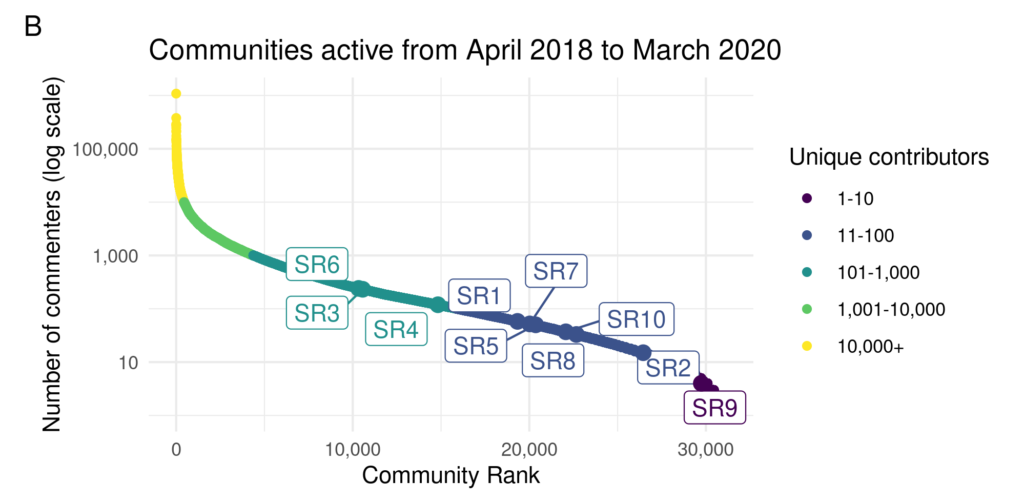
The number of unique commenters who commented on subreddits in March 2020, for subreddits that had at least 1 comment in the each of the previous 23 months. The “SR” communities are those we drew our interview sample from.
When it comes to online communities, we often assume that bigger is better. Large communities can create robust interactions, have access to broad and extensive body of experiences, and provide many opportunities for connections. As a result, small communities are often thought as failed attempts to build big ones. In reality, most online communities are very small and most small communities remain small throughout their lives. If growth and a large number of members are so advantageous, why do small communities not only exist but persist in their smallness?
In a recent research study, we investigated why individuals participate in these persistently small online communities by interviewing twenty participants of small subreddits on Reddit. We asked people about their motivations and explicitly tried to get them to compare their experiences in small subreddits with their experience in larger subreddits. Below we present three of the main things that we discovered through analyzing our conversations.
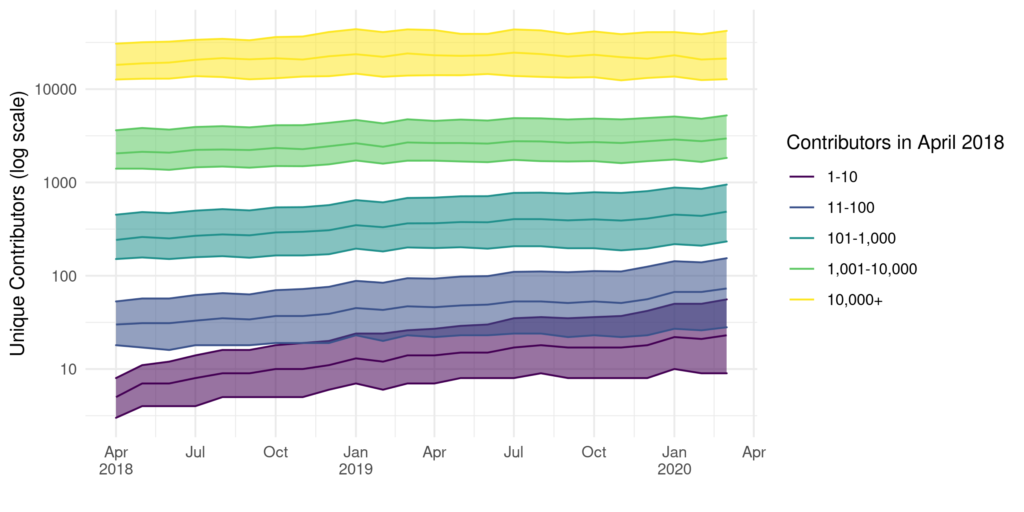
Size of consistently active subreddits over time (i.e., those with at least one comment per month from April 2018 to March 2020). Subreddits are grouped by their size in April 2018. Lines represent the median size each month, and ribbons show the first and third quartiles.
Informational niches
First, we found that participants saw their small communities as unique spaces for information and interaction. Frequently, small communities are narrower versions or direct offshoots of larger communities. For example, the r/python community is about the programming language Python while the r/learnpython community is a smaller community explicitly for newcomers to the language.
By being in a smaller, more specific community, our participants described being able to better anticipate the content, audience, and norms: a specific type of content, people who cared about the narrow topic just like them, and expectations of how to behave online. For example, one participant said:
[…] I can probably make a safe assumption that people there more often than not know what they’re talking about. I’ll definitely be much more specific and not try to water questions down with like, my broader scheme of things—I can get as technical as possible, right? If I were to ask like the same question over at [the larger parent community], I might want to give a little bit background on what I’m trying to do, why I’m trying to do it, you know, other things that I’m using, but [in small community], I can just be like, hey, look, I’m trying to use this algorithm for this one thing. Why should I? Or should I not do it for this?
Curating online experiences
More broadly, participants explained their participation in these small communities as part of an ongoing strategy of curating their online experience. Participants described a complex ecosystem of interrelated communities that the small communities sat within, and how the small communities gave them the ability to select very specific topics, decide who to interact with, and manage content consumption.
In this sense, small communities give individuals a semblance of control on the internet. Given the scale of the internet—and a widespread sense of malaise with online hate, toxicity, and harassment—it is possible that controlling the online experience is more important to users than ever. Because of their small size, these small communities were largely free of the vandals and trolls that plague large online communities, and several participants described their online communities as special spaces to get away from the negativity on the rest of the internet.
Relationships
Finally, one surprise from our research was what we didn’t find. Previous research led us to predict that people would participate in small communities because they would make it easier to develop friendships with other people. Our participants described being interested in the personal experiences of other group members, but not in building individual relationships with them.
Conclusions
Our research shows that small online communities play an important and underappreciated role. At the individual level, online communities help people to have control over their experiences, curating a set of content and users that is predictable and navigable. At the platform level, small communities seem to have a symbiotic relationship with large communities. By breaking up broader topical niches, small communities likely help to keep a larger set of users engaged.
We hope that this paper will encourage others to take seriously the role of small online communities. They are qualitatively different from large communities, and more empirical and theoretical research is needed in order to understand how communities of different sizes operate and interact in community ecosystems.
A preprint of the paper is available here. We’re excited that this paper has been accepted to CSCW2021 and will be published in the Proceedings of the ACM on Human-Computer Interaction and presented at the conference in November. If you have any questions about this research, please feel free to reach out to one of the authors: Sohyeon Hwang or Jeremy Foote.
It’s Ph.D. application season and the Community Data Science Collective is recruiting! As always, we are looking for talented people to join our research group. Applying to one of the Ph.D. programs that the CDSC faculty members are affiliated with is a great way to do that.
This post provides a very brief run-down on the CDSC, the different universities and Ph.D. programs we’re affiliated with, and what we’re looking for when we review Ph.D. applications. It’s close to the deadline for some of our programs, but we hope this post will still be useful to prospective applicants now and in the future.
Group photo of the collective at a recent virtual retreat.
What are these different Ph.D. programs? Why would I choose one over the other?
This year the group includes four faculty principal investigators (PIs) who are actively recruiting PhD students: Aaron Shaw (Northwestern University), Benjamin Mako Hill and Sayamindu Dasgupta (University of Washington in Seattle), and Jeremy Foote (Purdue University). Each of these PIs advise Ph.D. students in Ph.D. programs at their respective universities. Our programs are each described below.
Although we often work together on research and serve as co-advisors to students in each others’ projects, each faculty person has specific areas of expertise and interests. The reasons you might choose to apply to one Ph.D. program or to work with a specific faculty member could include factors like your previous training, career goals, and the alignment of your specific research interests with our respective skills.
At the same time, a great thing about the CDSC is that we all collaborate and regularly co-advise students across our respective campuses, so the choice to apply to or attend one program does not prevent you from accessing the expertise of our whole group. But please keep in mind that our different Ph.D. programs have different application deadlines, requirements, and procedures!
Who is actively recruiting this year?
Given the disruptions and uncertainties associated with the COVID19 pandemic, the faculty PIs are more constrained in terms of whether and how they can accept new students this year. If you are interested in applying to any of the programs, we strongly encourage you to reach out the specific faculty in that program before submitting an application.
Aaron Shaw is an Associate Professor in the Department of Communication Studies at Northwestern. In terms of Ph.D. programs, Aaron’s primary affiliations are with the Media, Technology and Society (MTS) and the Technology and Social Behavior (TSB) Ph.D. programs. Aaron also has a courtesy appointment in the Sociology Department at Northwestern, but he has not directly supervised any Ph.D. advisees in that department (yet). Aaron’s current research projects focus on comparative analysis of the organization of peer production communities and social computing projects, participation inequalities in online communities, and empirical research methods.
Jeremy Foote
Jeremy Foote is an Assistant Professor at the Brian Lamb School of Communication at Purdue University. He is affiliated with the Organizational Communication and Media, Technology, and Society programs. Jeremy’s current research focuses on how individuals decide when and in what ways to contribute to online communities, how communities change the people who participate in them, and how both of those processes can help us to understand which things become popular and influential. Most of his research is done using data science methods and agent-based simulations.
What do you look for in Ph.D. applicants?
There’s no easy or singular answer to this. In general, we look for curious, intelligent people driven to develop original research projects that advance scientific and practical understanding of topics that intersect with any of our collective research interests.
To get an idea of the interests and experiences present in the group, read our respective bios and CVs (follow the links above to our personal websites). Specific skills that we and our students tend to use on a regular basis include experience consuming and producing social science and/or social computing (human-computer interaction) research; applied statistics and statistical computing, various empirical research methods, social theory and cultural studies, and more.
Formal qualifications that speak to similar skills and show up in your resume, transcripts, or work history are great, but we are much more interested in your capacity to learn, think, write, analyze, and/or code effectively than in your credentials, test scores, grades, or previous affiliations. It’s graduate school and we do not expect you to show up knowing how to do all the things already.
Intellectual creativity, persistence, and a willingness to acquire new skills and problem-solve matter a lot. We think doctoral education is less about executing a task that someone else hands you and more about learning how to identify a new, important problem; develop an appropriate approach to solving it; and explain all of the above and why it matters so that other people can learn from you in the future. Evidence that you can or at least want to do these things is critical. Indications that you can also play well with others and would make a generous, friendly colleague are really important too.
All of this is to say, we do not have any one trait or skill set we look for in prospective students. We strive to be inclusive along every possible dimension. Each person who has joined our group has contributed unique skills and experiences as well as their own personal interests. We want our future students and colleagues to do the same.
Now what?
Still not sure whether or how your interests might fit with the group? Still have questions? Still reading and just don’t want to stop? Follow the links above for more information. Feel free to send at least one of us an email. We are happy to try to answer your questions and always eager to chat.
Debian is one of the oldest, largest, and most influential peer production communities and has produced an operating system used by millions for over the last three decades. DebConf is that community’s annual meeting. This year, the Community Data Science Collective was out in force at Debian’s virtual conference to present several Debian-focused research projects that we’ve been working on.
First, Wm Salt Hale presented work from his master thesis project on “Resilience in FLOSS: Do founder decisions impact development activity after crisis events?” His work tried to understand the social dynamics behind organizational resilience among free software projects based on what Salt calls “founder decisions.” He did so by estimating the relationship between changes in developer activity after security bugs and testing several theories about how this relationship might vary between permissive and copyleft licensed software packages.












{kind=link}