Welcome to part 2 of a 7-part series spotlighting the excellent talks we were fortunate enough to host during the Science of Community track at FOSSY 23!
Matt Gaughan delivered a rapid introduction to his dataset highlighting the numerous places where the Linux Kernel is using unsafe memory practices.
You can watch the talk HERE, check out the dataset HERE and learn more about Matt HERE.
Welcome to part 1 of a 7-part series spotlighting the excellent talks we were fortunate enough to host during the Science of Community track at FOSSY 23!
Sophia Vargas presented ‘Can we combat maintainer burnout with proactive metrics?’ In this talk, Sophia takes us through her extensive investigations across multiple projects to weigh the value of different metrics to anticipate when people might be burning out, including some surprising instances where metrics we might think are helpful really don’t tell us what we think they do.
You can watch the talk HERE and learn more about Sophia’s work HERE.
The CDSC hosted the Science of Community Track on July 15th at FOSSY this year — it was an awesome day of learning and conversation with a fantastic group of senior scholars, industry partners, students, practitioners, community members, and more! We are so grateful and eager to build on the discussions we began.
If you missed the sessions, watch this space! Most sessions were recorded, and we’ll post links and materials as they’re released.
Special thanks to Molly de Blanc for all the long distance organizing work; Shauna Gordon McKeon for stepping in to help share some closing thoughts on the Science of Community track at the very last minute, and to the FOSSY organizing team for convening such a warm, welcoming inaugural event (indeed, the warmth was palpable as it nearly hit 100° F on Friday and Saturday in Portland).
One tangible result of a free software conference: new laptop stickers!
Women in Data Science Puget Sound is part of a 50+-country conference series founded and organized in cooperation with Stanford University’s Data Science coalition. Anyone may attend, regardless of gender: events feature a speaker lineup composed of women in data science. The Puget Sound event is Tuesday, April 25 at the Expedia HQ in Seattle, and numerous affiliated regional and online events are scheduled in the coming weeks.
If you’re in the Seattle area, you might like to catch CDSC member Kaylea presenting a workshop! Here’s the pitch for attending her beginner-friendly session:
Let’s Re-think Political Bias & Build Our Own Classifier
How can we think about political bias without falling into assumptions about who's on what side and what that means?
Data science and ML offer us an alternative: we can parse political speech about a topic and use NLP/ML techniques to classify articles we scrape from the web.
In this hands-on workshop, we'll parse the Congressional Record, build a classifier, scrape search results, and analyze texts. You'll walk away with your own example of how to use data science to analyze political framing.
The full lineup of speakers for the Puget Sound conference is posted here. Tickets for the single-day event are $80 (see this link to request a discount code for half off).
Topics on the schedule for this event look juicy if quant work is your jam: AI, BERT, hypergraphs, visualization, forecasting, quantum computing, causal inference, survival analysis, writing better code and career management, with examples ranging from search, sales, and supply chain to economic disparity, DNA sequencing and saving wildlife!
In The Wealth Of Networks, Yochai Benkler describes the opportunities and decisions presented by networked forms of production. Writing in the mid-2000s, Benkler describes a wide range of future policy battlegrounds: copyrights and patents, common carrier infrastructure, the accessibility of the public sphere, and the verification of information.
Benkler predicts: “How these battles turn out over the next decade or so will likely have a significant effect on how we come to know what is going on in the world we occupy, and to what extent and in what forms we will be able…to affect how we and others see the world as it is and as it might be.”
Benkler uses two simple search examples, reporting the results of searching for “Viking ship” and “Barbie”. He finds that enthusiastic individuals and independent voices dominate the content we see on the web and that various search engines construct meaning in varying ways. I repeat his examples (searches conducted 7/3/2018 and 12/1/2022, from my home near Seattle, WA and using my personal laptop).
So how do ‘we come to know what is going on in the world we occupy’? Who creates what we see online? And what implications does that have for our own freedom to shape the world? The short version of the answer to this question seems to be: if there was a battle, it’s over now and the wreckage has disappeared; individuals and independent voices are marginalized and commercial content is dominant — and this picture does not vary among search engines.
Viking Ships
I used the same search engine (Google) and the same term (Viking Ship): what I see is that the individual hobbyists Benkler saw in 2006 are eclipsed by institutions. The materials on the current sites sound similar to those Benkler saw – photos, replicas, and scholarly information, as well as links and learning materials – but the production is generally institutional and formal in contrast to the individual and informal sources Benkler reports.
One other shift: in 2022, simply listing links in order is not sufficient to report what searchers see. Search results are interspersed with many other features: a widget with “sources from across the web”, an images display with associated keywords, a “People also ask” widget, and a related searches widget; to reach the 9th “result” in the classic sense, I have to browse to the second page of results.
Searching for ‘Viking Ship’ in 2006, 2018, and 2022
Barbie
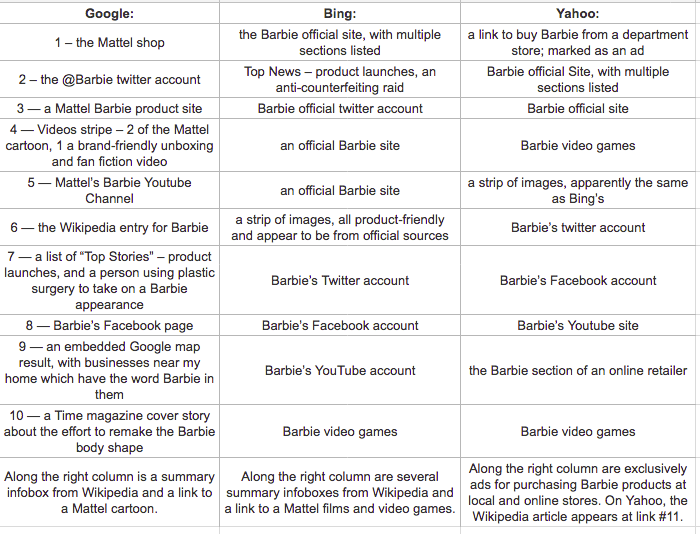
When I follow Benkler’s lead and search for ‘Barbie’ using three different search engines, the results are even more different from 2006. Benkler describes differences in search engine results as revealing different possibilities – via Google, Barbie was portrayed as “a culturally contested figure”, whereas on Overture (a now-defunct shopping-oriented search engine), the searcher encountered “a commodity toy.”
By contrast, my 2018 search via the then-current top 3 search engines, inclusive of widgets and other features, revealed:
Searching for ‘Barbie’ via the top 3 search engines in 2018.
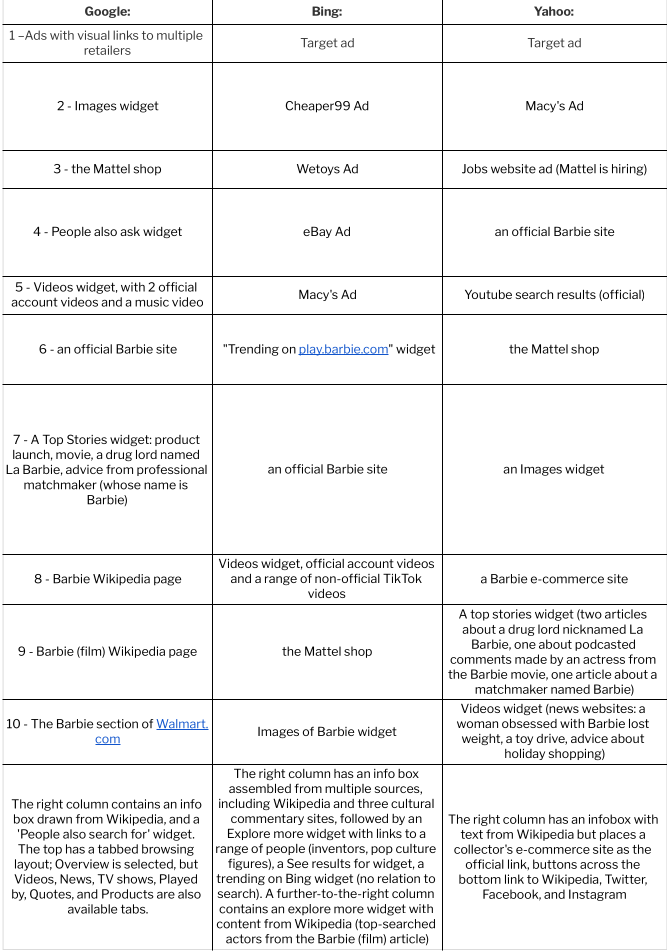
The top search engines in 2022 are the same three firms, although I observe that some sources suggest DuckDuckGo, Baidu (Chinese language only) and Yandex (Russian) belong in a top 5; other sources treat YouTube and Amazon as “top search engines” although they are not actually search engines. My 2022 search, inclusive of widgets and other features, revealed:
Searching for ‘Barbie’ via the top 3 search engines in 2022.
The modern Barbie searcher encounters primarily a multiplatform brand, with some hints of cultural constructions. In 2018 this took the form of extreme plastic surgery and brand-friendly fan fiction, in 2022 weight loss and fan TikTok. To whatever degree search engine algorithms continue to give weight to alternate voices in this case, they are largely drowned out by the volume of the commercial voice: the meaning of a search query for the single term “Barbie” has been substantially narrowed since Benkler’s time, and perhaps has narrowed even further in the last four and a half years.
The web in 2006 was indeed a different place, and I have commented on additional dimensions of analysis not present in Wealth: embedding of visual and social media content, and the widgetizing of content. In 2018, these visual components were less dominant: a stripe of Viking Ship images and a stripe of Barbie videos. In 2022 search, the page can scarcely be described without them.
We can now answer Benkler’s challenge: how did “these battles” over the last decade and a half “turn out”?
How do we “come to know what is going on in the world we occupy”?
How are we able “to affect how we and others see the world as it is and as it might be”?
The answer seems to be, it’s unclear to what degree there was a battle at all: collectives have triumphed over individuals on the Web insofar as search engines represent it. These collectives are generally firms, although some formal institutions are also present: news media, Wikipedia, and (in the case of Viking Ship) museums.
The implications of our search environment are significant, and underscore the necessity of efforts to archive and capture the search landscape as it appeared. The role of platforms and institutions in constructing our understanding of the world should be of key concern in information and communication sciences.
For civil society groups, these results suggest alienation: the commercializing of the web has been accompanied by a narrowing of outlets for individual expression and critique, with Wikipedia and its community co-construction of knowledge a vital bright spot. For journalists, these results suggest the vital role of cultural reporting. For firms, the challenge is one of authenticity and connection: to the extent that the web has become a broadcast medium focused on official paid messaging, the opportunity to engage with consumers is lost, and along with it a spark for innovation. Search platforms benefit in the mean time, as jockeying for ad positioning between manufacturers and retailers drives revenue, at least until commercialism turns consumer attention elsewhere.
CDSC members Molly deBlanc and Kaylea Champion will be presenting at this year’s Aaron Swartz Day and International Hackathon. Molly will speak at 2:50 p.m. Pacific (talk title: My (Extended) Body, My Choice). Kaylea will speak at 3:15 p.m. Pacific (talk title: The Value of Anonymity: Evidence from Wikipedia). Registration and live stream details are available here: https://www.aaronswartzday.org/
If you’re attending ACM-CSCW this year, you are warmly invited to join CDSC members during our talks and other scheduled events. CSCW is not only virtual but spread across multiple weeks and offering sessions multiple times to accommodate timezones. We hope to see you there — we are eager to discuss our work with you!
Tuesday, November 8
6pm-7pm Pacific, “No Community Can Do Everything: Why People Participate in Similar Online Communities” Details at: https://programs.sigchi.org/cscw/2022/index/content/87413 By: Nathan Te Blunthuis, Charles Kiene, Isabella Brown, Nicole McGinnis, Laura Levi, Benjamin Mako Hill
3am-4am Pacific “The Risks, Benefits, and Consequences of Prepublication Moderation: Evidence from 17 Wikipedia Language Editions” Details at: https://programs.sigchi.org/cscw/2022/index/content/87945 By:Chau Tran, Kaylea Champion, Benjamin Mako Hill, Rachel Greenstadt
Friday, November 11
8am-9am Pacific. Many Destinations, Many Pathways: A Quantitative Analysis of Legitimate Peripheral Participation in Scratch. Details at: https://programs.sigchi.org/cscw/2022/index/content/87487 By: Ruijia Cheng, Benjamin Mako Hill
3pm-4pm Pacific “The Risks, Benefits, and Consequences of Prepublication Moderation: Evidence from 17 Wikipedia Language Editions” Details at: https://programs.sigchi.org/cscw/2022/index/content/87945 By: Chau Tran, Kaylea Champion, Benjamin Mako Hill, Rachel Greenstadt
8pm-9pm Pacific. Many Destinations, Many Pathways: A Quantitative Analysis of Legitimate Peripheral Participation in Scratch. Details at: https://programs.sigchi.org/cscw/2022/index/content/87487 By: Ruijia Cheng, Benjamin Mako Hill
Friday, November 18
6am-7am Pacific, “No Community Can Do Everything: Why People Participate in Similar Online Communities” Details at: https://programs.sigchi.org/cscw/2022/index/content/87413 By: Nathan Te Blunthuis, Charles Kiene, Isabella Brown, Nicole McGinnis, Laura Levi, Benjamin Mako Hill
And there’s more…
CDSC members and affiliates are involved in CSCW beyond these public presentations. Nicholas Vincent, Sohyeon Hwang, and Sneha Narayan are part of the organizing team for the “Ethical Tensions, Norms, and Directions in the Extraction of Online Volunteer Work” workshop, where Molly de Blanc is scheduled to present and Kaylea Champion will be giving a lightning talk. Katherina Kloppenborg and Kaylea Champion are presenting in the Doctoral Consortium.
Although we might not notice it, much of the technology we rely on, from cell phones to cloud servers, is fueled by decades of effort by volunteers who create innovative software as well as the organizations necessary to sustain it. Despite this powerful legacy, we now are facing a crisis: not all of these critical components have been sufficiently maintained. Can we detect that an important software component is becoming neglected before major failures occur? Are these neglected packages just a matter of resources — old code and too few contributors — or can we see broader patterns that play a role, such as collaboration and organizational structures? Kaylea Champion has been working to answer these questions in her dissertation. As part of this work, she joined the software community metrics enthusiasts gathered at this year’s CHAOSSCon EU on September 12, 2022 as part of the Open Source Summit.
Kaylea’s presentation shares work in progress about the sources of underproduction, or when highly important packages see low quality development, in open software development. This presentation marks her second time at CHAOSSCon and builds on her work shared at last year’s conference in a lightning talk about detecting underproduction in Debian (see coverage of this work as presented to Debian folks here). Engaging with communities is a key part of this work: when we understand practitioner perspectives on underproduction and its causes, we can do science that supports taking immediate action. If you are interested in measuring the health of your collaborative community, let’s talk!
How should search engines be regulated? What are the implications of the EU Digital Services Act? If you are interested in technology policy, mark your calendar for an upcoming pre-conference virtual event: “Harms and Standards in Content Platform Governance” (October 13, 2022 at 5:00 a.m. PST, 8:00 a.m EST, 2:00 p.m. CEST). As part of the upcoming European Communication Research and Education conference, the Communication Law and Policy section has invited Kaylea Champion to present work she did with Benjamin Mako Hill and University of Washington students Jacinta Harshe, Isabella Brown, and Lucy Bao.
We examine the information landscape as manifested in search results during the Covid-19 pandemic using data we collected as part of the Covid-19 Digital Observatory Project. Our results provide evidence for the powerful ways that search engines shape our information environment–in terms of what information gets seen, the sources of that information, the market sectors that those sources operate within, and the partisan bias of those results.
This free event is oriented to connecting technology researchers and policymakers, and will include presentations of research from legal, communication, and critical perspectives.
SANER is primarily focused on software engineering practices, and several of the projects presented this year were of interest for social computing scholars. Here’s a quick rundown of presentations I particularly enjoyed:
Newcomers: Does marking a bug as a ‘Good First Issue’ help retain newcomers? These results from Hyuga Horiguchi, Itsuki Omori and Masao Ohira suggest the answer is “yes.” However, marking documentation tasks as a ‘Good First Issue’ doesn’t seem to help with the onboarding process. Read more or watch the talk at: Onboarding to Open Source Projects with Good First Issues: A Preliminary Analysis[VIDEO]
Comparison of online help communities: This article by Mahshid Naghashzadeh, Amir Haghshenas, Ashkan Sami and David Lo compares two question/answer environments that we might imagine as competitors—the Matlab community of Stack Overflow versus the Matlab community hosted by Matlab. These sites have similar affordances and topics, however, the two sites seem to draw distinctly different types of questions. This article features an extensive hand-coded dataset by subject matter experts: How Do Users Answer MATLAB Questions on Q&A Sites? A Case Study on Stack Overflow and MathWorks[VIDEO]
Feedback: What goes wrong when software developers give one another feedback on their code? This study by a large team (Moataz Chouchen, Ali Ouni, Raula Gaikovina Kula, Dong Wang, Patanamon Thongtanunam, Mohamed Wiem Mkaouer and Kenichi Matsumoto) offers an ontology of the pitfalls and negative interactions that can occur during the popular code feedback practice known as code review: confused reviewers, divergent reviewers, low review participation, shallow review, and toxic review: Anti-patterns in Modern Code Review: Symptoms and Prevalence [VIDEO]
Critical Infrastructure: This study by Mahmoud Alfadel, Diego Elias Costa and Emad Shihab was focused on traits of security problems in Python and made some comparisons to npm. This got me thinking about different community-level factors (like bug release/security alert policies) that may influence underproduction. I also found myself wondering about inter-rater reliability for bug triage in communities like Python. The paper showed a very similar survival curve for bugs of varying severities, whereas my work in Debian showed distinct per-severity curves. One explanation for uniform resolution rate across severities could be high variability in how severity ratings are applied. Another factor worth considering may be the role of library abandonment: Empirical analysis of security vulnerabilities in python packages[VIDEO]