We will be running the Science of Community track on Friday August 2nd and Saturday August 3rd. Check out the full schedule here.
We’re excited to have a number of really amazing speakers presenting their work. Check out the list below:
Kaylea and Matt will be presenting again!
The Science of Community track is inspired by the CDSC Science of Community Dialogues, which aim to bring together practitioners and researchers to discuss scholarly work that is relevant to the efforts of practitioners. As researchers, we get so much from the communities we work with and study and we want them to also learn from the research they so generously take part in. While the Dialogues cover a broad range of topics and communities, FOSSY presentations focus on how that work related to free and open source software communities, projects, and practitioners.
We hope to see you at FOSSY. Even if you can’t make it to our sessions, we’ll be at the conference so stop by and say hello!
Worried you didn’t submit your FOSSY proposal on time? Well fear not, the deadline has been extended to Tuesday, June 18th. Submit your proposal today!
Does your work touch open source, communities, technology, or cooperation? Do you want to help bridge the gaps between research and practice? Join us at the Free and Open Source Software Yearly conference (FOSSY) this summer!
We’ll be running the Science of Community track, and are looking for presenters to speak to an audience of FOSS practitioners, developers, community organizers, contributors, and people just generally into and curious about FOSS.
FOSSY is a low-stress opportunity to talk to people who your work can benefit. For topics, consider presenting implications from past papers, synthesizing work from your field overall, or floating ideas and problems (lightning talks! long talks! short talks!). A full track description and answers to common questions is available on our wiki.
The (extraordinary!) panelists were Jaz-Michael King (IFTAS), Christine Lemmer-Webber (Spritely Institute), and Bryan Newbold (BlueSky). The discussion ranged far and wide over some key background on decentralized and federated social media as well as some urgent challenges and opportunities in the space.
The recording of the session is up and you can watch it here (or in the frame below).
Thanks to the panelists, Madison Deyo, and the HCI+D team for making this happen!
Does your work touch open source, communities, technology, or cooperation? Do you want to help bridge the gaps between research and practice? Join us at FOSSY! The Free and Open Source Software Yearly conference (FOSSY) is back this summer and the call for proposals is open!
We’ll be running the Science of Community track, and are looking for presenters to speak to an audience of FOSS practitioners, developers, community organizers, contributors, and people just generally into and curious about FOSS.
The Science of Community track is inspired by the CDSC Science of Community Dialogues, which bring together practitioners and researchers to discuss scholarly work that is relevant to the efforts of practitioners. As researchers, we benefit so much from the communities we work with and study and we want them to also learn from the research they so generously take part in. While the Dialogues cover a broad range of topics and communities, FOSSY presentations will focus on how that work relates to free and open source software communities, projects, and practitioners.
FOSSY is a low-stress opportunity to talk to people who your work can benefit. For topics, consider presenting implications from past papers, synthesizing work from your field overall, or floating ideas and problems (lightning talks! long talks! short talks!). A full track description and answers to common questions is available on our wiki.
How can we create more trustworthy and accountable social media that support diverse communities? Decentralized social media—systems that allow users to connect and communicate across independent services like Mastodon or BlueSky—offer promising alternatives to centralized commercial platforms like Instagram, TikTok, or X. However, decentralized social media also face urgent design challenges, especially when it comes to content integrity, protecting community trust and safety, and forging collective governance. What happens when there is no central authority to review posts or ban abusive users? How can networks of autonomous communities build and adopt systems to govern effectively? What critical infrastructure can prevent the pervaisve harms of existing social media and support the integrity of public discourse?
Join Northwestern’s Center for Human-Computer Interaction + Design (HCI+D) and the Community Data Science Collective (CDSC) for an engaging conversation about the challenges and opportunites of decentralized social media on May 23rd from 4 to 5:15 p.m. CST. This panel features designers, leaders, and researchers involved in federated social media and will address opportunities for effective design and governance in this space.
Panelists include Jaz-Michael King, Bryan Newbold, and Christine Lemmer-Webber. Short presentations will be followed by discussion and Q&A moderated by Aaron Shaw (Northwestern HCI+D, CDSC).
Moderator: Aaron Shaw, photograph by Nikki Ritcher Photography
Speaker: Christine Lemmer-Webber, Executive Director of Spritely Networked Communities Institute
Christine has devoted her life to advancing user freedom. Realizing that the federated social web was fractured by a variety of incompatible protocols, she co-authored and shepherded ActivityPub‘s standardization. She has also contributed to many other free and open source projects, including co-founding MediaGoblin.
Christine established the open source Spritely Project to solve known problems in existing centralized and decentralized social media platforms and to re-imagine the way we build networked applications – work that now continues here at the institute under her guidance as Executive Director.
Speaker: Jaz-Michael King, Executive Director of IFTAS (Federated Trust & Safety)
An accomplished professional with an extraordinary record of enabling data-driven decisions, developing innovative products, creating new business opportunities, driving strong operational performance, and building high-performing, agile teams. Highly versatile, with extensive experience in data and technology from a privacy, improvement, and reporting perspective, Jaz has a proven record in building solutions for non-profit programs. As Executive Director of IFTAS, Jaz is now focused on independent, open Social Web activities, with the aim of creating #BetterSocialMedia by supporting trust and safety at scale in federated social media networks.
Speaker: Bryan Newbold, Protocol Engineer at BlueSky
Bryan works at Bluesky, a startup company building a federated social media protocol called “atproto”. Until a few months ago he worked at the Internet Archive collecting scientific research datasets and publications, and created scholar.archive.org. And before that he worked on infrastructure at Stripe, attended the Recurse Center in New York City, and built Atomic Magnetometers for a small New Jersey company called Twinleaf.
Over that same time period, Bryan climbed up and down the ladder of abstraction, obtaining an undergraduate degree in physics (at MIT), operating under-ice robots in Antarctica, developing open hardware lab instrumentation for large-scale brain probing (at LeafLabs), cataloging hundreds of millions of electronics components (at Octopart), and improved production service reliability at Stripe (a financial infrastructure start-up).
Bryan is a transplant from the East Coast and enjoys the road biking, large trees, generous salads, used bookstores, and world-class tech non-profits. This will be his third year serving on the Code of Conduct team at DWeb Camp.
A screenshot of the configuration panel for Moderator functions of a popular end-user bot called Dyno, adopted by millions of communities on Discord.
Bots made by end users are crucial to the success of online communities, helping community leaders moderate content as well as manage membership and engagement. But most folks don’t have the resources to develop custom bots and turn to existing bots shared by their peers. For example, on Discord, some especially popular bots are adopted by millions of communities. However, because these bots are ultimately third-party tools — made by neither the platform nor the community leader in question — they still come with several challenges. In particular, community leaders need to develop the right understandings about a bot’s nature, value, and use in order to adopt it into their community’s existing processes and culture.
In organizational research, these “understandings” are sometimes described as technological frames, a concept developed by Orlikowski & Gash (1994) as they studied why technologies became used in unexpected ways in organizational settings. When your technological frames are well-aligned with a tool’s design, you can imagine that it is easier to assess whether that tool will be useful and can be smoothly incorporated into your organization as intended. In the context of online communities, well-aligned frames can not only reduce the labor and time of bot adoption, but also help community leaders anticipate issues that might cause harm to the community. Our new paper looks to communities on Discord and asks: How do community leaders shift their technology frames of third-party bots and leverage them to address community needs?
Emergent social ecosystems around bot adoption
Our study interviewed 16 community leaders on Discord, walking through their experiences adopting third-party bots for their communities. These interviews underscore how community leaders have developed social ecosystems around bots: organicuser-to-user networks of resources, aid, and knowledge about bots across communities.
Despite the decentralized arrangement of communities on Discord, users devised and took advantage of formal and informal opportunities to revise their understandings about bots, both supporting and constraining how bots became used. This was particularly important because third-party bots pose heightened uncertainties about their reliability and security, especially for bots used to protect the community from external threads (such as scammers). For example, interviewees laid out concerns about whether a bot developer could be trusted to keep their bot online, to respond to problems users had, and to manage sensitive information. The emergent social ecosystems helped users get recommendations from others, assess the reputation of bot developers, and consider whether the bot was a good fit for them along much more nuanced dimensions (in the case of one interviewee, the values of the bot developer mattered as well). They also created opportunities for people to directly get help in setting up bots and troubleshooting them, such as via engaged discussions with other users who had more experience.
Our findings underscore a couple of core reasons why we should care about these social ecosystems:
Closing gaps in bot-related skills and knowledge. Across interviews, we saw patterns of people leveraging the resources and aid in social ecosystems to move towards using more powerful but complex bots. Ultimately, people with diverse technical backgrounds (including those who stated they had no technical background) were able to adopt and use bots — even bots involving code-like configurations in markdown languages that might normally pose barriers. We suggest that the diffusion of end-user tools on social platforms be matched with efforts to provide bottom-up social scaffoldings that support exploration, learning, and user discussion of those tools.
Changing perceptions of the labor involved in bot adoption. The process of bot adoption as a deeply social one appeared to impact how people saw the labor they invested into it, shifting it into something fun and satisfying. Bot adoption was both collaborative, involving many individuals as a user discovered, evaluated, set up, and fine-tuned bots; and communal, with community members themselves taking part in some of these steps. We suggest that bot adoption can provide one avenue to deepen community engagement by creating new ways of participating and generating meta discussions about the community, as well as the platform.
Shaping the assumptions around third-party tools. Social ecosystems enabled people to cherry-pick functions across bots, enabling creative wiggle room in curating a set of preferred functions. At the same time, people were constrained by social signals about what bots are and can do, why certain bots are worth adopting, and how the bot is used. For example, people often talked about genres of bots even though no such formal categories existed. We suggest that spaces where leaders from different communities interact with one another to discuss strategies and experiences can be impactful settings for further research, intervention, and design ideas.
Ultimately, the social nature of adopting third-party bots in our interviews offers insight into how we can better support the adoption of valuable user-facing tools across online communities. As online harms become more and more technically sophisticated (e.g., the recent rise of AI-generated disinformation), user-made bots that quickly respond to emerging issues will play an important role in managing communities — and will be even more valuable if they can be shared across communities. Further attention to the dynamics that enable tools to be used across communities with diverse norms and goals will be important as the risks that communities face, and the tools available to them, evolve.
Engage with us!
If you have thoughts, ideas, questions, we are always happy to talk – especially if you think there are community-facing resources we can develop from this work. There are a few ways to engage with us:
We’re going to be at CHI! The Community Date Science Collective will be presenting work from group members and affiliates. CHI is taking place in Honolulu, Hawaiʻi from May 11th – 16th.
By Robert Linsdell from St. Andrews, Canada – Flight from Honolulu to Hilo. Over Sand Island and Honolulu (503729), CC BY 2.0
Carolyn Zou (Northwestern University) will be presenting with coauthor Helena Vasconcelos on their work “Validation Without Ground Truth? Methods for Trusts in Generative Simulations” at the CHI workshops HEAL (Human-Centered Evaluation and Auditing of Language Models) and TREW (Trust and Reliance in Evolving Human-AI Workflows). They will be presenting posters at both sessions and have been selected as a highlighted paper for HEAL and will be giving a presentation on Sunday, May 12th.
Madison Deyo has recently joined the CDSC as a Program Coordinator and we couldn’t be more thrilled to welcome her to the team!
Madison is based at Northwestern. With the CDSC, Madison’s role includes a mix of event planning and coordination; outreach and communications; and supporting the operations of the group. She also works with the Northwestern Center for Human-Computer Interaction + Design. Madison brings experience working with community-based non-profits in several different capacities.
Madison currently lives in Chicago, and grew up in Wisconsin, where she attended the University of Wisconsin-Madison. There, she received my B.S. in Art (with a focus on illustration) and Communications: Radio-TV-Film. In addition to her position at Northwestern, Madison also works as a freelance artist designing mead labels, tattoos, and occasionally album/EP covers. You can check out her portfolio.
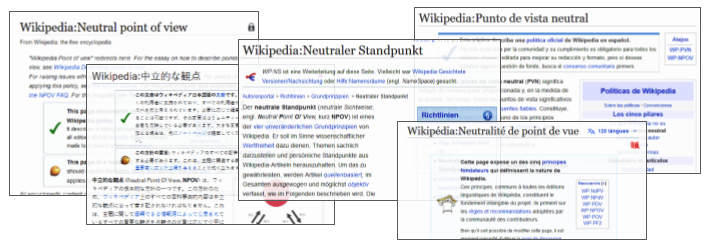
Screenshot of the same rule, Neutral Point of View, on five different language editions. Notably, the pages are different because they exist as connected but ultimately separate pages.
While Wikipedia is famous for its encyclopedic content, it may be surprising to realize that a whole other set of pages on Wikipedia help guide and govern the creation of the peer-produced encyclopedia. These pages extensively describe processes, rules, principles, and technical features of creating, coordinating, and organizing on Wikipedia. Because of the success of Wikipedia, these pages have provided valuable insights into how platforms might decentralize and facilitate participation in online governance. However, each language edition of Wikipedia has a unique set of such pages governing it respectively, even though they are part of the same overarching project: in other words, an under-explored opportunity to understand how governance operates across diverse groups.
In a manuscript published at ICWSM2022, we present descriptive analyses examining on rules and rule-making across language editions of Wikipedia motivated by questions like:
What happens when communities are both relatively autonomous but within a shared system? Given that they’re aligned in key ways, how do their rules and rule-making develop over time? What can patterns in governance work tell us about how communities are converging or diverging over time?
We’ve been very fortunate to share this work with the Wikimedia community since publishing the paper, such as the Wikipedia Signpost and Wikimedia Research Showcase. At the end of last year, we published the replication data and files on Dataverse after addressing a data processing issue we caught earlier in the year (fortunately, it didn’t affect the results – but yet another reminder to quadruple-check one’s data pipeline!). In the spirit of sharing the work more broadly since the Dataverse release, we summarize some of the key aspects of the work here.
Study design
In the project, we examined the five largest language editions of Wikipedia as distinct editing communities: English, German, Spanish, French and Japanese. After manually constructing lists of rules per wiki (resulting in 780 pages), we took advantage of two features on Wikipedia: the revision histories, which log every edit to every page; and the interlanguage links, which connect conceptually equivalent pages across language editions. We then conducted a series of analyses examining comparisons across and relationships between language editions.
Shared patterns across communities
Across communities, we observed that trends suggested that rule-making often became less open over time:
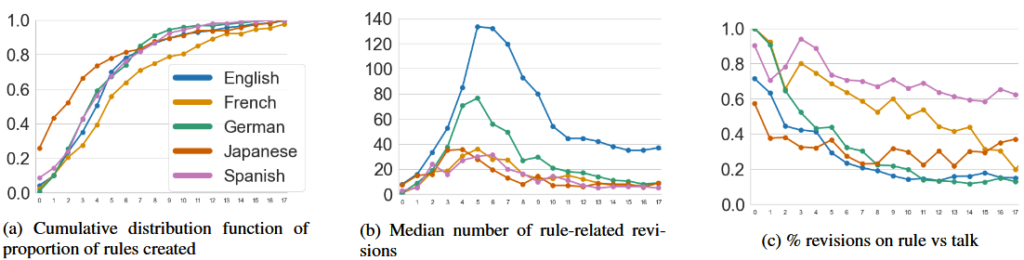
Figure 2 from the ICWSM paper
Most rules are created early in the life of the language edition community’s life. Over a nearly 20 year period, roughly 50-80% of the rules (depending on the language edition) were created within the first five years!
The median edit count to rule pages peaked in early years (between years 3 and 5) before tapering down. The percent of revisions dedicated to editing the actual rule text versus discussing it shifts towards discussion of rule across communities. These both suggest that rules across communities have calcified over time.
Said simply, these communities have very similar trends in rule-making towards formalization.
Divergence vs convergence in rules
Wikipedia’s interlanguage link (ILL) feature, as mentioned above, lets us explore how the rules being created and edited on communities relate to one another. While the trends above highlight similarities in rule-making, here, the picture about how the rule sets are similar or not is a bit more complicated.
On one hand, the top panel here shows that over time, all five communities see an increase in the proportion of rules in their rules sets that are unique to them individually. On the other hand, the bottom panel shows that editing efforts concentrate on rules that are more shared across communities.
Altogether, we see that communities sharing goals, technology, and a lot more develop substantial and sustained institutional variations; but it’s possible that broad, widely-shared rules created early may help keep them relatively aligned.
Key takeaways
Investigating governance across groups like Wikipedia is valuable for at least two reasons.
First, an enormous amount of effort has gone into studying governance on English Wikipedia, the largest and oldest language edition, to distill lessons about how we can meaningfully decentralize governance in online spaces. But, as prior work [e.g., 1] shows, language editions are often non-aligned in both the content they produce and how they organize that content. Some early stage work we did noted this held true for rule pages on the five language editions of Wikipedia explored here. In recent years, the Wikimedia Foundation itself has made several calls to understand dynamics and patterns beyond English Wikipedia. This work is in part in response to this movement.
Second, the questions explored in our work highlight a key tension in online governance today. While online communities are relatively autonomous entities, they often exist within social and technical systems that put them in relation with one another – whether directly or not. Effectively addressing concerns about online governance means understanding how distinct spaces online govern in ways that are similar or dissimilar, overlap or conflict, diverge and converge. Wikipedia can offer many lessons to this end because it has an especially decentralized and participatory vision of how to govern itself online, such as how patterns of formalization impact success and engagement. Future work we are working on continues in this vein – stay tuned!
Do you care about community, design, computing, and research? We are looking for a person to grow the public impact of the Community Data Science Collective (CDSC) and Northwestern University Center for Human Computer Interaction +Design (HCI+D). We are hiring a full time Program Coordinator to work in both groups. This person will focus on outreach, communications, research community development, strategic event planning, and administration for both the CDSC and HCI+D.
Although a portion of the work may be done remotely, attendance for in-person meetings and workshops is required and the position is located in Evanston on the Northwestern University campus. The average salary for similar positions at Northwestern is around $55,000 per year and includes excellent benefits (compensation details for this position can only be determined by Northwestern HR in the hiring process). We’re looking for a minimum 2 year commitment.
Duties
These fall into four categories, with specific examples in each listed below:
Outreach & communications
Manage social media posting (LinkedIn, Mastodon, X, WordPress etc.)
Post events to listservs and websites
Advertise events such as the Collective’s “Science of Community” series and the Center’s “Thought Leader Dialogues”
Build contact-lists around specific events and topics
Share messages with internal and external audiences
Research community development
Recruit participants to community events
Organize group retreats (3-4 year total)
Engage with community members of both the Collective and Center
Strategic event planning
Develop and execute a strategic event plan for in-person/virtual events
Collaborate with Collective and Center members to plan and recruit speakers for events
Administration:
Schedule and plan research meetings
Track and report on collective and center achievements
Draft annual research and donor reports
Document processes and initiatives
Core competencies:
Ability to use and learn web content management tools, such as wordpress, and wikis.
General organization
Communication (be clear, be concise)
Meeting facilitation
Managing upwards
Small/medium scale (20-50 people) event planning
Creative thinking and problem solving
Qualifications
Candidates must hold at least a bachelor’s degree. Familiarity with event planning, community management, project management, and/or scientific research is a plus, as is prior experience in the social or computer sciences, research organizations, online communities, and/or public interest technology and advocacy projects of any kind.
About Northwestern’s Center for HCI+Design and the Community Data Science Collective
The Community Data Science Collective is an interdisciplinary research group made up of faculty, students, and affiliates mainly at the University of Washington Department of Communication, the Northwestern University Department of Communication Studies, the Carleton College Computer Science Department, and the Purdue University School of Communication. To learn more about the Community Data Science Collective, you should check out our wiki, blog, and recent publications.
Northwestern’s Center for Human Computer Interaction + Design is an interdisciplinary research center that brings together researchers and practitioners from across the University to study, design, and develop the future of human and computer interaction at home, work, and play in the pursuit of new interaction paradigms to support a collaborative, sustainable, and equitable society.
Contact
Please contact Aaron Shaw with questions. Both the CDSC and the Center for HCI+D are committed to creating diverse, inclusive, equitable, and accessible environments and we look forward to working with someone who shares these values.
Ready to apply?
Please apply via the Northwestern University job posting (and note that the job ID is 49284). We will begin reviewing applications immediately (continuing on a rolling basis until the position is filled).












{kind=link}