Online communities are frequently described as promising sites for computing education. Advocates of online communities as contexts for learning argue that they can help novices learn concrete programming skills through self-directed and interest-driven work. Of course, it is not always clear how well this plays out in practice—especially when it comes to learning challenging programming concepts. We sought to understand this process through a mixed-method case study of the Scratch online community that will be published and presented at the ACM Conference on Human Factors in Computing (CHI 2022) in several weeks.
Scratch is the largest online interest-driven programming community for novices. In Scratch, users can create programming projects using the visual-block based Scratch programming language. Scratch users can choose to share their projects—and many do—so that they can be seen, interacted with, and remixed by other Scratch community members. Our study focused on understanding how Scratch users learn to program with data structures (i.e., variables and lists)—a challenging programming concept for novices—by using community-produced learning resources such as discussion threads and curated project examples. Through a qualitative analysis on Scratch forum discussion threads, we identified a social feedback loop where participation in the community raises the visibility of some particular ways of using variables and lists in ways that shaped the nature and diversity of community-produced learning resources. In a follow-up quantitative analysis on a large collection of Scratch projects, we find statistical support for this social process.
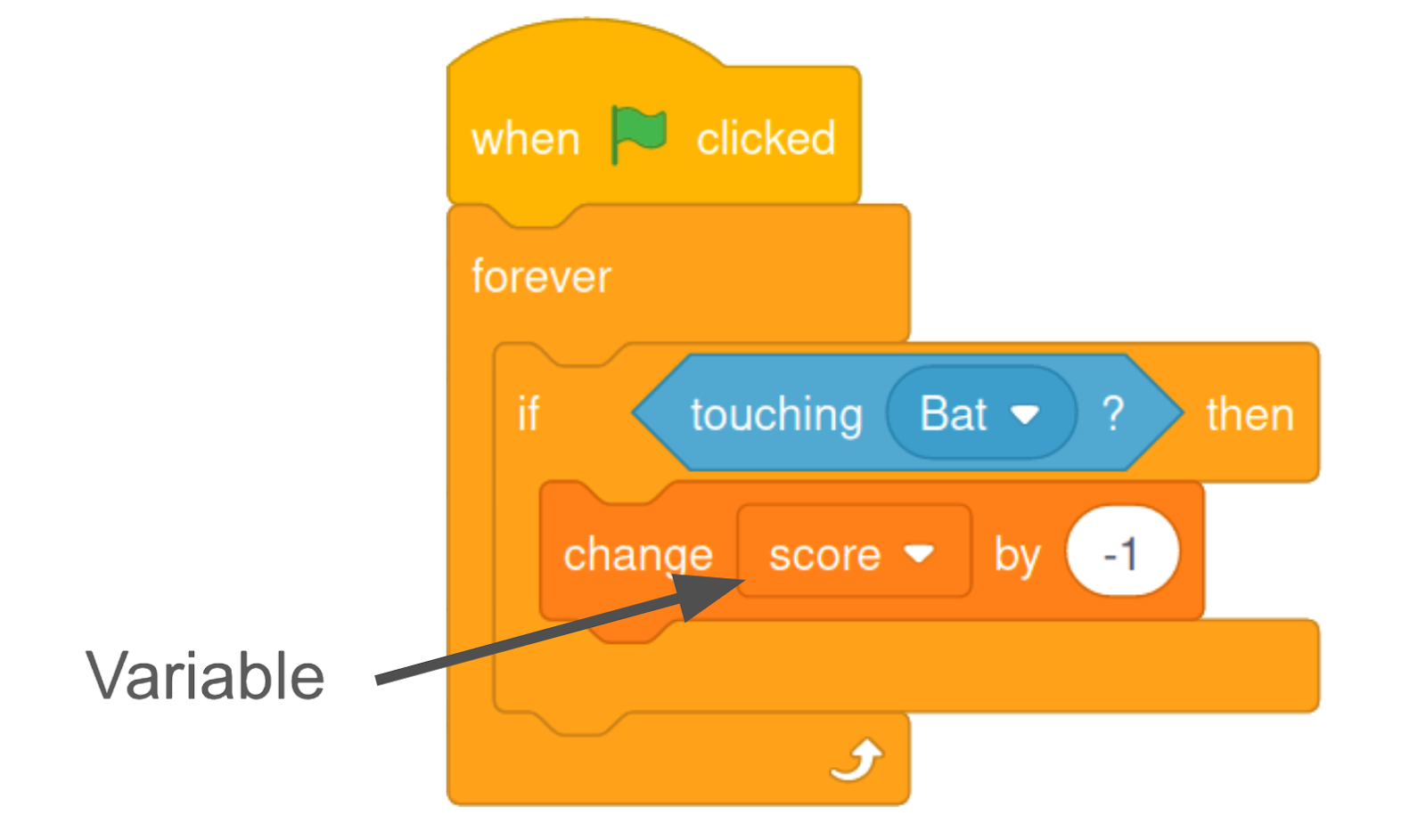
As the first step of our study, we collected and qualitatively analyzed 400 discussion threads about variables and lists in the Scratch Q&A forums. Our key finding was that Scratch users use specific, concrete examples to teach each other about variables and lists. These examples are commonly framed in terms of elements in the projects that they are making, often specific to games.
For instance, we observed users teach each other how to make a score counter in a game using variables. In another example, we saw users sharing tips on creating an item inventory in a game using lists. As a result of this focus on specific game elements, user-generated examples and tutorials are often framed in the specifics of these game-making scenarios. For example, a lot of sample Scratch code on variables and lists were from games with popular elements like scores and inventories. While these community-produced learning resources offers valuable concrete examples, not everybody is interested in making games. We some some evidence that users who are not interested in making games involving scores and inventories were less likely to get effective support when they sought to learn about variables. We argue that repeated over time, this dynamic can lead to a social feedback loop where reliance on community-generated resources can place innovative forms of creative coding at a disadvantage compared to historically common forms.
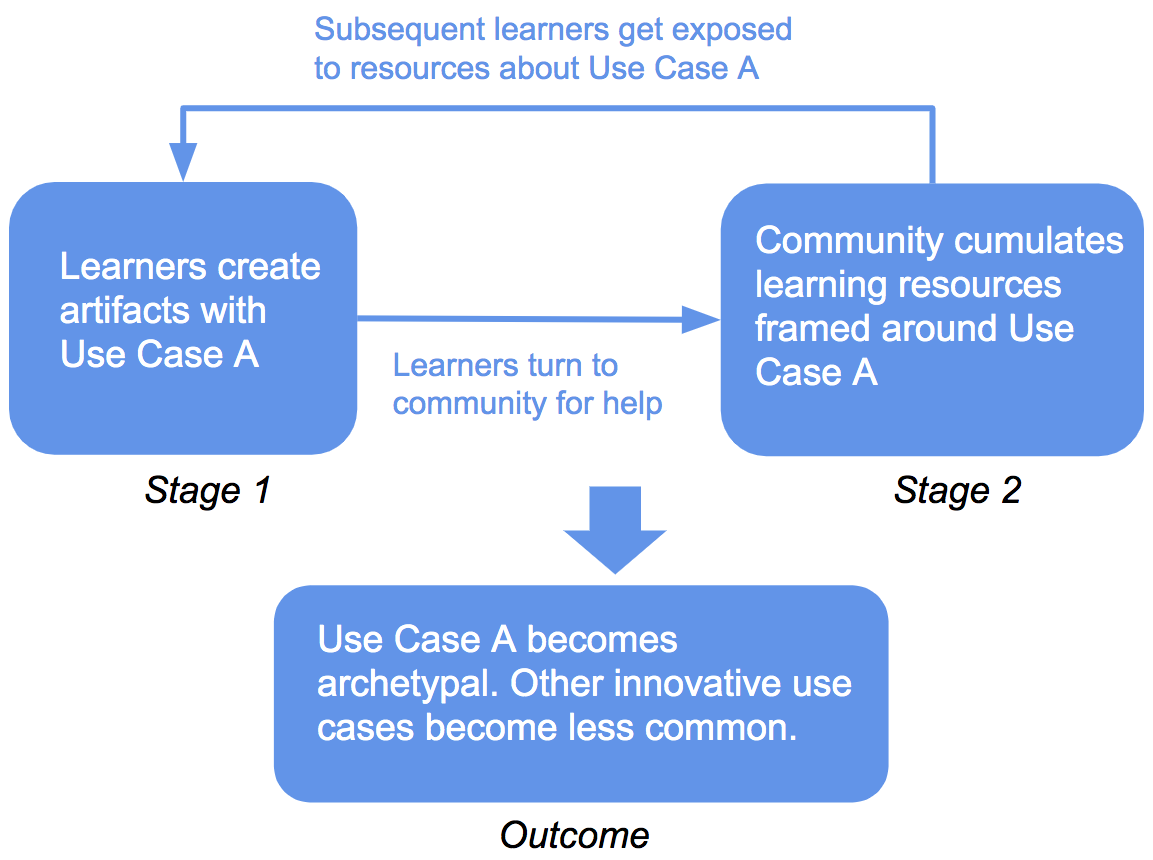
The graph here is a visualization of the social feedback loop theory that we proposed. Stage 1 suggests that, in an online interest-driven learning community, some specific applications of a concept (“Use Case A”) will be more popular than others. This might be due to random chance or any number of reasons. When seeking community support, learners will tend to ask questions framed specifically around Use Case A and use community resources framed in terms of the same use case. Stage 2 shows the results of this process. As learners receive support, they produce new artifacts with Use Case A that can serve as learning resources for others. Then, learners in the future can use these learning resources, becoming even more likely to create the same specific application. The outcome of the feedback loop is that, as certain applications of a concept become more popular over time, the community’s learning resources are increasingly focused on the same applications.
We tested our social feedback loop theory using 5 years of Scratch data including 241,634 projects created by 75,911 users. We tested both the mechanism and the outcome of the loop from multiple angles in terms of three hypotheses that we believe will be true if our the feedback loop we describe is shaping behavior:
- More projects involving variables and lists will be games over time.
- The type of project elements that users make with variables and lists (we defined it as the names that they gave to variables and lists) will be more homogenous.
- Users who have been exposed to popular variable and list names will be more likely to use those names in their own projects. We found at least some support for all of our hypotheses.
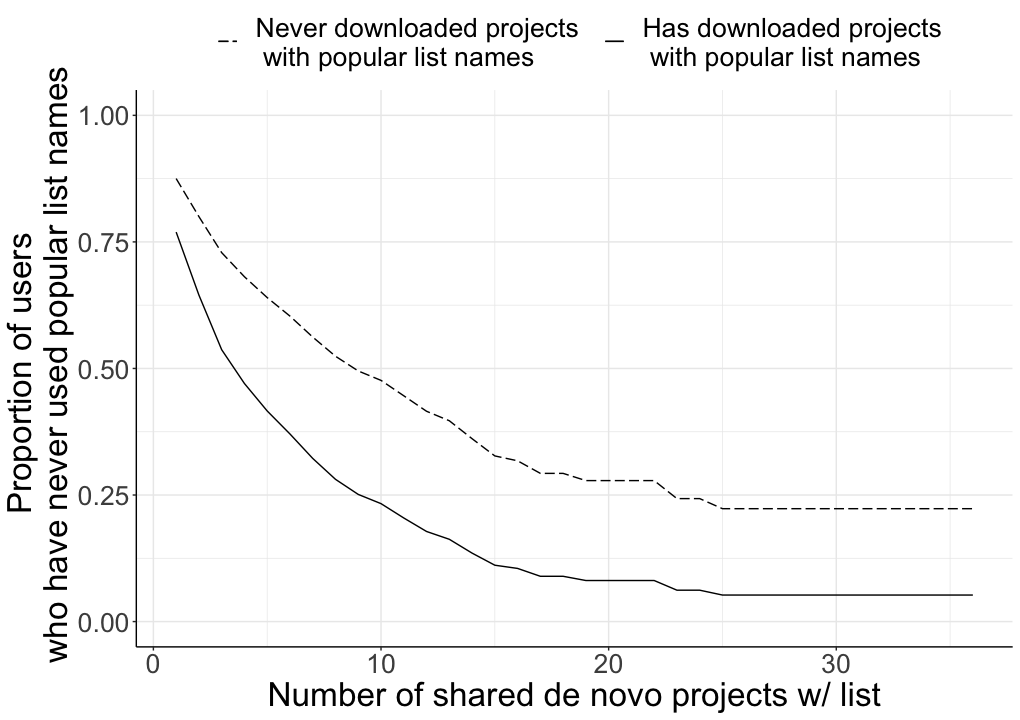
Our results provide broad (if imperfect) support for our social feedback loop theory. For example, the graph below illustrates one of our findings: users who have been exposed to popular list names (solid line) will be more likely to use (in other words, less likely to never use) popular names in their projects, compared to users who have never downloaded projects with popular list names (dashed line).
The results from our study describe an important trade-off that designers of online communities in computational learning need to be aware of. On the one hand, learners can learn advanced computational concepts by building their own explanation and understanding on specific use cases that are popular in the community. On the other, such learning can be superficial and not conceptual or generalizable: learners’ preference for peer-generated learning resources around specific interests can restrict the exploration of broader and more innovative uses, which can potentially limit sources of inspiration, pose barriers to broadening participation, and confine learners’ understanding of general concepts. We conclude our paper suggesting several design strategies that might be effective in countering this effect.
Please refer to the preprint of the paper for more details on the study and our design suggestions for future online interest-driven learning communities. We’re excited that this paper has been accepted to CHI 2022 and received the Best Paper Honorable Mention Award! It will be published in the Proceedings of the ACM on Human-Computer Interaction and presented at the conference in May. The full citation for this paper is:
Ruijia Cheng, Sayamindu Dasgupta, and Benjamin Mako Hill. 2022. How Interest-Driven Content Creation Shapes Opportunities for Informal Learning in Scratch: A Case Study on Novices’ Use of Data Structures. In CHI Conference on Human Factors in Computing Systems (CHI ’22), April 29-May 5, 2022, New Orleans, LA, USA. ACM, New York, NY, USA, 16 pages. https://doi.org/10.1145/3491102.3502124
If you have any questions about this research, please feel free to reach out to one of the authors: Ruijia “Regina” Cheng, Sayamindu Dasgupta, and Benjamin Mako Hill.
Discover more from Community Data Science Collective
Subscribe to get the latest posts sent to your email.
2 Replies to “How does Interest-driven Participation Shape Computational Learning in Online Communities?”