As we do every year, members of the Community Data Science Collective will be presenting work at the International Communication Association (ICA)’s 71st Annual Conference which will take place virtually next week. Due to the asynchronous format of ICA this year, none of the talks will happen at specific times. Although the downside of the virtual conference is that we won’t be able to meet up with you all in person, the good news is that you’ll be able to watch our talks and engage with us on whatever timeline suits you best between May 27 and and 31st.
This year’s offerings from the collective include:
Nathan TeBlunthuis will be presenting work with Benjamin Mako Hill as part of the ICA Computational Methods section on “Time Series and Trends in Communication Research.” The name of their talk is “A Community Ecology Approach for Identifying Competitive and Mutualistic Relationships Between Online Communities.”
Aaron Shaw is presenting a paper on “Participation Inequality in the Gig Economy” on behalf of himself, Floor Fiers and Eszter Hargittai . The talk will be as part of a session organized by the ICA Communication and Technology section on “From Autism to Uber: The Digital Divide and Vulnerable Populations.”
Floor Fiers collaborated with Nathan Walter on a poster titled “Sharing Unfairly: Racial Bias on Airbnb and the Effect of Review Valence.” The poster is part of the interactive poster session of the ICA Ethnicity and Race section.
Nick Hager will be talking about his paper with Aaron Shaw titled “Randomly-Generated Inequality in Online News Communities,” which is part of a high density session on “Social Networks and Influence.”
Finally, Jeremy Foote will be chairing a session on “Cyber Communities: Conflicts and Collaborations” as part of the ICA Communication and Technology division.
We look forward to sharing our research and connecting with you at ICA!
SANER is primarily focused on software engineering practices, and several of the projects presented this year were of interest for social computing scholars. Here’s a quick rundown of presentations I particularly enjoyed:
Newcomers: Does marking a bug as a ‘Good First Issue’ help retain newcomers? These results from Hyuga Horiguchi, Itsuki Omori and Masao Ohira suggest the answer is “yes.” However, marking documentation tasks as a ‘Good First Issue’ doesn’t seem to help with the onboarding process. Read more or watch the talk at: Onboarding to Open Source Projects with Good First Issues: A Preliminary Analysis[VIDEO]
Comparison of online help communities: This article by Mahshid Naghashzadeh, Amir Haghshenas, Ashkan Sami and David Lo compares two question/answer environments that we might imagine as competitors—the Matlab community of Stack Overflow versus the Matlab community hosted by Matlab. These sites have similar affordances and topics, however, the two sites seem to draw distinctly different types of questions. This article features an extensive hand-coded dataset by subject matter experts: How Do Users Answer MATLAB Questions on Q&A Sites? A Case Study on Stack Overflow and MathWorks[VIDEO]
Feedback: What goes wrong when software developers give one another feedback on their code? This study by a large team (Moataz Chouchen, Ali Ouni, Raula Gaikovina Kula, Dong Wang, Patanamon Thongtanunam, Mohamed Wiem Mkaouer and Kenichi Matsumoto) offers an ontology of the pitfalls and negative interactions that can occur during the popular code feedback practice known as code review: confused reviewers, divergent reviewers, low review participation, shallow review, and toxic review: Anti-patterns in Modern Code Review: Symptoms and Prevalence [VIDEO]
Critical Infrastructure: This study by Mahmoud Alfadel, Diego Elias Costa and Emad Shihab was focused on traits of security problems in Python and made some comparisons to npm. This got me thinking about different community-level factors (like bug release/security alert policies) that may influence underproduction. I also found myself wondering about inter-rater reliability for bug triage in communities like Python. The paper showed a very similar survival curve for bugs of varying severities, whereas my work in Debian showed distinct per-severity curves. One explanation for uniform resolution rate across severities could be high variability in how severity ratings are applied. Another factor worth considering may be the role of library abandonment: Empirical analysis of security vulnerabilities in python packages[VIDEO]
In exciting collective news, the US National Science Foundation announced that Benjamin Mako Hill has received of one of this year’s CAREER awards. The CAREER is the most prestigious grant that the NSF gives to early career scientists in all fields.
Crumbling infrastructure. J.C. Burns (jcburns) via flickr, CC BY-NC-ND 2.0
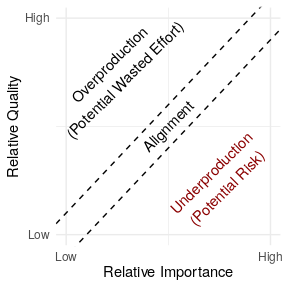
Critical software we all rely on can silently crumble away beneath us. Unfortunately, we often don’t find out software infrastructure is in poor condition until it is too late. Over the last year or so, I have been leading a project I announced earlier to measure software underproduction—a term I use to describe software that is low in quality but high in importance.
Underproduction reflects an important type of risk in widely used free/libre open source software (FLOSS) because participants often choose their own projects and tasks. Because FLOSS contributors work as volunteers and choose what they work on, important projects aren’t always the ones to which FLOSS developers devote the most attention. Even when developers want to work on important projects, relative neglect among important projects is often difficult for FLOSS contributors to see.
Conceptual diagram showing how our conception of underproduction relates to quality and importance of software.
In the paper—coauthored with Benjamin Mako Hill—we describe a general approach for detecting “underproduced” software infrastructure that consists of five steps: (1) identifying a body of digital infrastructure (like a code repository); (2) identifying a measure of quality (like the time to takes to fix bugs); (3) identifying a measure of importance (like install base); (4) specifying a hypothesized relationship linking quality and importance if quality and importance are in perfect alignment; and (5) quantifying deviation from this theoretical baseline to find relative underproduction.
To show how our method works in practice, we applied the technique to an important collection of FLOSS infrastructure: 21,902 packages in the Debian GNU/Linux distribution. Although there are many ways to measure quality, we used a measure of how quickly Debian maintainers have historically dealt with 461,656 bugs that have been filed over the last three decades. To measure importance, we used data from Debian’s Popularity Contest opt-in survey. After some statistical machinations that are documented in our paper, the result was an estimate of relative underproduction for the 21,902 packages in Debian we looked at.
One of our key findings is that underproduction is very common in Debian. By our estimates, at least 4,327 packages in Debian are underproduced. As you can see in the list of the “most underproduced” packages—again, as estimated using just one more measure—many of the most at risk packages are associated with the desktop and windowing environments where there are many users but also many extremely tricky integration-related bugs.
These 30 packages have the highest level of underproduction in Debian according to our analysis.
We hope these results are useful to folks at Debian and the Debian QA team. We also hope that the basic method we’ve laid out is something that others will build off in other contexts and apply to other software repositories.
Paper Citation: Kaylea Champion and Benjamin Mako Hill. 2021. “Underproduction: An Approach for Measuring Risk in Open Source Software.” In Proceedings of the IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER 2021). IEEE.
Contact Kaylea Champion (kaylea@uw.edu) with any questions or if you are interested in following up.
We try to keep this blog updated with new research and presentations from members of the group, but we often fall behind. With that in mind, this post is more of a listicle: 22 things you might not have seen from the CDSC in the past year! We’ve included links to (hopefully un-paywalled copies) of just about everything.
Champion, Kaylea. (2021) Underproduction: An approach for measuring risk in open source software. 28th IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER).
Dasgupta, Sayamindu, Benjamin Mako Hill, and Andrés Monroy-Hernández. 2020 (Forthcoming). Engaging Learners in Constructing Constructionist Environments. In Designing Constructionist Futures: The Art, Theory, and Practice of Learning Designs, edited by Nathan Holbert, Matthew Berland, and Yasmin Kafai. Cambridge, Massachusetts: MIT Press.
Hill, Benjamin Mako, and Aaron Shaw. 2020. Studying Populations of Online Communities. In The Oxford Handbook of Networked Communication, edited by Brooke Foucault Welles and Sandra González-Bailón, 174–93. Oxford, UK: Oxford University Press.
Ko, Amy J., Alannah Oleson, Neil Ryan, Yim Register, Benjamin Xie, Mina Tari, Matthew Davidson, Stefania Druga, and Dastyni Loksa. 2020. It is time for more critical CS education. Communications of the ACM 63, 11 (November 2020), 31–33.
Tran, Chau, Kaylea Champion, Andrea Forte, Benjamin Mako Hill, and Rachel Greenstadt. 2020. Are anonymity-seekers just like everybody else? An analysis of contributions to Wikipedia from Tor.” In 2020 IEEE Symposium on Security and Privacy (SP), 1:974–90. San Francisco, California: IEEE Computer Society.
TeBlunthuis Nathan E.,Benjamin Mako Hill. Aaron Halfaker. “Algorithmic flags and Identity-Based Signals in Online Community Moderation” Session on Social media 2, International Conference on Computational Social Science (IC2S2 2020), Cambridge, MA, July 19, 2020.
TeBlunthuis Nathan E.., Aaron Shaw, *Benjamin Mako Hill. “The Population Ecology of Online Collective Action.” Session on Culture and fairness, International Conference on Computational Social Science (IC2S2 2020), Cambridge, MA, July 19, 2020.
TeBlunthuis Nathan E., Aaron Shaw, Benjamin Mako Hill. “The Population Ecology of Online Collective Action.” Session on Collective Action, ACM Conference on Collective Intelligence (CI 2020), Boston, MA, June 18, 2020.
The Northwestern University branch of the Community Data Science Collective (CDSC) is hiring research assistants. CDSC is an interdisciplinary research group made of up of faculty and students at multiple institutions, including Northwestern University, Purdue University, and the University of Washington. We’re social and computer scientists studying online communities such as Wikipedia, Reddit, Scratch, and more.
A screenshot from a recent remote meeting of the CDSC…
Recent work by the group includes studies of participation inequalities in online communities and the gig economy, comparisons of different online community rules and norms, and evaluations of design changes deployed across thousands of sites. More examples and information can be found on our list of publications and our research blog (you’re probably reading our blog right now).
This posting is specifically to work on some projects through the Northwestern University part of the CDSC. Northwestern Research Assistants will contribute to data collection, analysis, documentation, and administration on one (or more) of the group’s ongoing projects. Some research projects you might help with include:
A study of rules across the five largest language editions of Wikipedia.
A systematic literature review on the gig economy.
Interviews with contributors to small, niche subreddit communities.
A large-scale analysis of the relationships between communities.
Successful applicants will have an interest in online communities, social science or social computing research, and the ability to balance collaborative and independent work. No specialized skills are required and we will adapt work assignments and training to the skills and interests of the person(s) hired. Relevant skills might include: coursework, research, and/or familiarity with digital media, online communities, human computer interaction, social science research methods such as interviewing, applied statistics, and/or data science. Relevant software experience might include: R, Python, Git, Zotero, or LaTeX. Again, no prior experience or specialized skills are required.
Expected minimum time commitment is 10 hours per week through the remainder of the Winter quarter (late March) with the possibility of working additional hours and/or continuing into the Spring quarter (April-June). All work will be performed remotely.
Interested applicants should submit a resume (or CV) along with a short cover letter explaining your interest in the position and any relevant experience or skills. Applicants should indicate whether you would prefer to pursue this through Federal work-study, for course credit (most likely available only to current students at one of the institutions where CDSC affiliates work), or as a paid position (not Federal work-study). For paid positions, compensation will be $15 per hour. Some funding may be restricted to current undergraduate students (at any institution), which may impact hiring decisions.
Questions and/or applications should be sent to Professor Aaron Shaw. Work-study eligible Northwestern University students should indicate this in their cover letter. Applications will be reviewed by Professor Shaw and current CDSC-NU team members on a rolling basis and finalists will be contacted for an interview.
The CDSC strives to be an inclusive and accessible research community. We particularly welcome applications from members of groups historically underrepresented in computing and/or data sciences. Some of these positions funded through a U.S. National Science Foundation Research Experience for Undergraduates (REU) supplement to awards numbers: IIS-1910202 and IIS-1617468.
It’s Ph.D. application season and the Community Data Science Collective is recruiting! As always, we are looking for talented people to join our research group. Applying to one of the Ph.D. programs that the CDSC faculty members are affiliated with is a great way to do that.
This post provides a very brief run-down on the CDSC, the different universities and Ph.D. programs we’re affiliated with, and what we’re looking for when we review Ph.D. applications. It’s close to the deadline for some of our programs, but we hope this post will still be useful to prospective applicants now and in the future.
CDSC members at the CDSC group retreat in August 2020 (pandemic virtual edition). Left to right by row, starting at top: Charlie, Mako, Aaron, Carl, Floor, Gabrielle, Stef, Kaylea, Tiwalade, Nate, Sayamindu, Regina, Jeremy, Salt, and Sejal.
What are these different Ph.D. programs? Why would I choose one over the other?
Although we have people at other places, this year the group includes four faculty principal investigators (PIs) who are actively recruiting PhD students: Aaron Shaw (Northwestern University), Benjamin Mako Hill (University of Washington in Seattle), Sayamindu Dasgupta (University of North Carolina at Chapel Hill), and Jeremy Foote (Purdue University). Each of these PIs advise Ph.D. students in Ph.D. programs at their respective universities. Our programs are each described below.
Although we often work together on research and serve as co-advisors to students in each others’ projects, each faculty person has specific areas of expertise and interests. The reasons you might choose to apply to one Ph.D. program or to work with a specific faculty member could include factors like your previous training, career goals, and the alignment of your specific research interests with our respective skills.
At the same time, a great thing about the CDSC is that we all collaborate and regularly co-advise students across our respective campuses, so the choice to apply to or attend one program does not prevent you from accessing the expertise of our whole group. But please keep in mind that our different Ph.D. programs have different application deadlines, requirements, and procedures!
Who is actively recruiting this year?
Given the disruptions and uncertainties associated with the COVID19 pandemic, the faculty PIs are more constrained in terms of whether and how they can accept new students this year. If you are interested in applying to any of the programs, we strongly encourage you to reach out the specific faculty in that program before submitting an application.
Benjamin Mako Hill is an Assistant Professor of Communication at the University of Washington. He is also an Adjunct Assistant Professor at UW’s Department of Human-Centered Design and Engineering (HCDE) and Computer Science and Engineering (CSE). Although many of Mako’s students are in the Department of Communication, he also advises students in the Department of Computer Science and Engineering, HCDE, and the Information School—although he typically has limited ability to admit students into those programs. Mako’s research focuses on population-level studies of peer production projects, computational social science, efforts to democratize data science, and informal learning.
Aaron Shaw is an Associate Professor in the Department of Communication Studies at Northwestern. In terms of Ph.D. programs, Aaron’s primary affiliations are with the Media, Technology and Society (MTS) and the Technology and Social Behavior (TSB) Ph.D. programs. Aaron also has a courtesy appointment in the Sociology Department at Northwestern, but he has not directly supervised any Ph.D. advisees in that department (yet). Aaron’s current research projects focus on comparative analysis of the organization of peer production communities and social computing projects, participation inequalities in online communities, and empirical research methods.
Jeremy Foote
Jeremy Foote is an Assistant Professor at the Brian Lamb School of Communication at Purdue University. He is affiliated with the Organizational Communication and Media, Technology, and Society programs. Jeremy’s current research focuses on how individuals decide when and in what ways to contribute to online communities, and how understanding those decision-making processes can help us to understand which things become popular and influential. Most of his research is done using data science methods and agent-based simulations.
What do you look for in Ph.D. applicants?
There’s no easy or singular answer to this. In general, we look for curious, intelligent people driven to develop original research projects that advance scientific and practical understanding of topics that intersect with any of our collective research interests.
To get an idea of the interests and experiences present in the group, read our respective bios and CVs (follow the links above to our personal websites). Specific skills that we and our students tend to use on a regular basis include experience consuming and producing social science and/or social computing (human-computer interaction) research; applied statistics and statistical computing, various empirical research methods, social theory and cultural studies, and more.
Formal qualifications that speak to similar skills and show up in your resume, transcripts, or work history are great, but we are much more interested in your capacity to learn, think, write, analyze, and/or code effectively than in your credentials, test scores, grades, or previous affiliations. It’s graduate school and we do not expect you to show up knowing how to do all the things already.
Intellectual creativity, persistence, and a willingness to acquire new skills and problem-solve matter a lot. We think doctoral education is less about executing a task that someone else hands you and more about learning how to identify a new, important problem; develop an appropriate approach to solving it; and explain all of the above and why it matters so that other people can learn from you in the future. Evidence that you can or at least want to do these things is critical. Indications that you can also play well with others and would make a generous, friendly colleague are really important too.
All of this is to say, we do not have any one trait or skill set we look for in prospective students. We strive to be inclusive along every possible dimension. Each person who has joined our group has contributed unique skills and experiences as well as their own personal interests. We want our future students and colleagues to do the same.
Now what?
Still not sure whether or how your interests might fit with the group? Still have questions? Still reading and just don’t want to stop? Follow the links above for more information. Feel free to send at least one of us an email. We are happy to try to answer your questions and always eager to chat.
A few months ago we announced the launch of a COVID-19 Digital Observatory in collaboration with Pushshift and with funding from Protocol Labs. As part of this effort over the last several months, we have aggregated and published public data from multiple online communities and platforms. We’ve also been hard at work adding a series of new data sources that we plan to release in the near future.
Transmission electron microscope image of SARS-CoV-2—also known as 2019-nCoV, the not-so-novel-anymore virus that causes COVID-19 (Source: NIH NIAID via Wikimedia Commons, cc-sa 2.0)
More specifically, we have been gathering Search Engine Response Page (SERP) data on a range of COVID-19 related terms on a daily basis. This SERP data is drawn from both Bing and Google and has grown to encompass nearly 300GB of compressed data from four months of daily search engine results, with both PC and mobile results from nearly 500 different queries each day.
We have also continued to gather and publish revision and pageview data for COVID-related pages on English Wikipedia which now includes approximately 22GB of highly compressed data (several dozen gigabytes of compressed revision data each day) from nearly 1,800 different articles—a list that has been growing over time.
In addition, we are preparing releases of COVID-related data from Reddit and Twitter. We are almost done with two datasets from Reddit: a first one that includes all posts and comments from COVID-related subreddits, and a second that includes all posts or comments which include any of a set of COVID-related terms.
For the Twitter data, we are working out details of what exactly we will be able to release, but we anticipate including Tweet IDs and metadata for tweets that include COVID-related terms as well as those associated with hashtags and terms we’ve identified in some of the other data collection. We’re also designing a set of random samples of COVID-related Twitter content that will be useful for a range of projects.
In conjunction with these dataset releases, we have published all of the code to create the datasets as well as a few example scripts to help people learn how to load and access the data we’ve collected. We aim to extend these example analysis scripts in the future as more of the data comes online.
We hope you will take a look at the material we have been releasing and find ways to use it, extend it, or suggest improvements! We are always looking for feedback, input, and help. If you have a COVID-related dataset that you’d like us to publish, or if you would like to write code or documentation, please get in touch!
Although Wikipedia is the encyclopedia that anybody can edit, not all edits are welcome. Wikipedia is subject to a constant deluge of vandalism. Random people on the Internet are constantly “blanking” Wikipedia articles by deleting their content, replacing the text of articles with random characters, inserting outlandish claims or insults, and so on. Although volunteer editors and bots do an excellent job of quickly reverting the damage, the cost in terms of volunteer time is real.
Why do people spend their time and energy vandalizing web pages? For readers of Wikipedia that encounter a page that has been marred or replaced with nonsense or a slur—and especially for all the Wikipedia contributors who spend their time fighting back the tide of vandalism by checking and reverting bad edits and maintaining the bots and systems that keep order—it’s easy to dismiss vandals as incomprehensible sociopaths.
In a paper I just published in the ACM International Conference on Social Media and Society, I systematically analyzed a dataset of Wikipedia vandalism in an effort to identify different types of Wikipedia vandalism and to explain how each can been seen as “rational” from the point of view of the vandal.
Leveraging a dataset we created in some of our other work, the study used a random sample of contributions drawn from four groups that vary in the degree to the editors in question can be identified by others in Wikipedia: established users with accounts, users with accounts making their first edits, users without accounts, and users of the Tor privacy tool. Tor users were of particular interest to me because the use of Tor offers concrete evidence that a contributor is deliberately seeking privacy. I compared the frequency of vandalism in each group, developed an ontology to categorize it, and tested the relationship between group membership and different types of vandalism.
Vandalism in an University bathroom. [“Whiteboard Revisited.” Quinn Dombrowski. via flickr, CC BY-SA 2.0]
I found that the group that had engaged in the least effort in order to edit—users without accounts—were the most likely to vandalize. Although privacy-seeking Tor contributors were not the most likely to vandalize, vandalism from Tor-based contributors was less likely to be sociable, was more likely to be large scale (i.e. large blocks of text, such as by pasting in the same lines over and over), and more likely to express frustration with the Wikipedia community.
Thinking systematically about why different groups of users might engage in vandalism can help counter vandalism. Potential interventions might change not just the amount, but also the type, of vandalism a community will receive. Tools to detect vandalism may find that the patterns in each category allow for more accurate targeting. Ultimately, viewing vandals as more than irrational sociopaths opens potential avenues for dialogue.
Paper Citation: Kaylea Champion. 2020. “Characterizing Online Vandalism: A Rational Choice Perspective.” In International Conference on Social Media and Society (SMSociety’20). Association for Computing Machinery, New York, NY, USA, 47–57. https://doi.org/10.1145/3400806.3400813
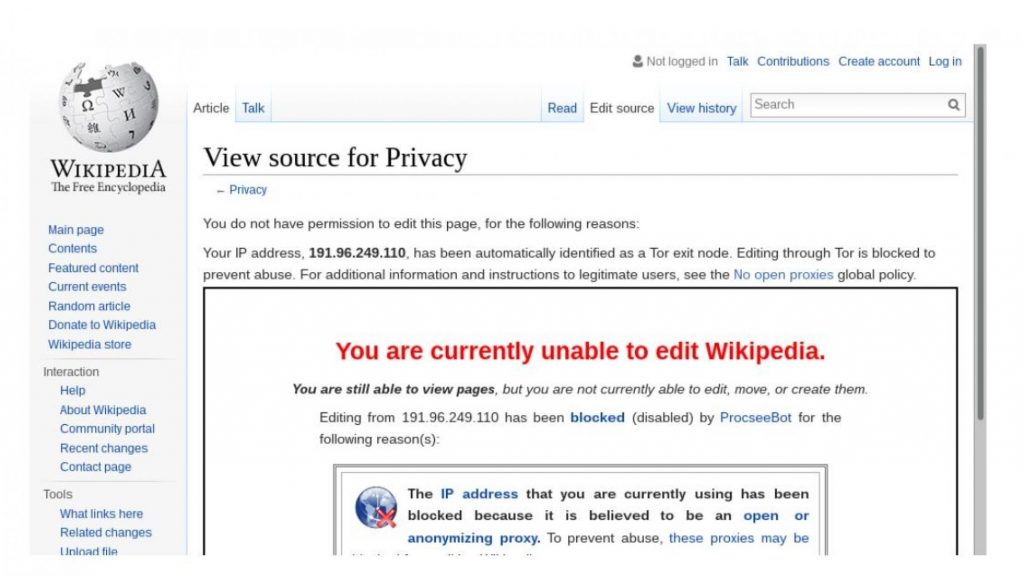
An image displaying the message that Tor users typically receive when trying to make edits on Wikipedia, stating that the user’s IP address has been identified as a Tor exit node, and that “editing through Tor is blocked to prevent abuse.”
Like everyone else, Internet users who protect their privacy by using the anonymous browsing software Tor are welcome to read Wikipedia. However, when Tor users try to contribute to the self-described “encyclopedia that anybody can edit,” they typically come face-to-face with a notice explaining that their participation is not welcome.
Our new paper—led by Chau Tran at NYU and authored by a group of researchers from the University of Washington, the Community Data Science Collective, Drexel, and New York University—was published and presented this week at the IEEE Symposium on Security & Privacy and provides insight into what Wikipedia might be missing out on by blocking Tor. By comparing contributions from Tor that slip past Wikipedia’s ban to edits made by other types of contributors, we find that Tor users make contributions to Wikipedia that are just as valuable as those made by new and unregistered Wikipedia editors. We also found that Tor users are more likely to engage with certain controversial topics.
One-minute “Trailer” for our paper and talk at the IEEE Symposium on Security & Privacy. Video was produced by Tommy Ferguson at the UW Department of Communication.
To conduct our study, we first identified more than 11,000 Wikipedia edits made by Tor users who were able to bypass Wikipedia’s ban on contributions from Tor between 2007 and 2018. We then used a series of quantitative techniques to evaluate the quality of these contributions. We found that Tor users made contributions that were similar in quality to, and in some senses even better than, contributions made by other users without accounts and newcomers making their first edits.
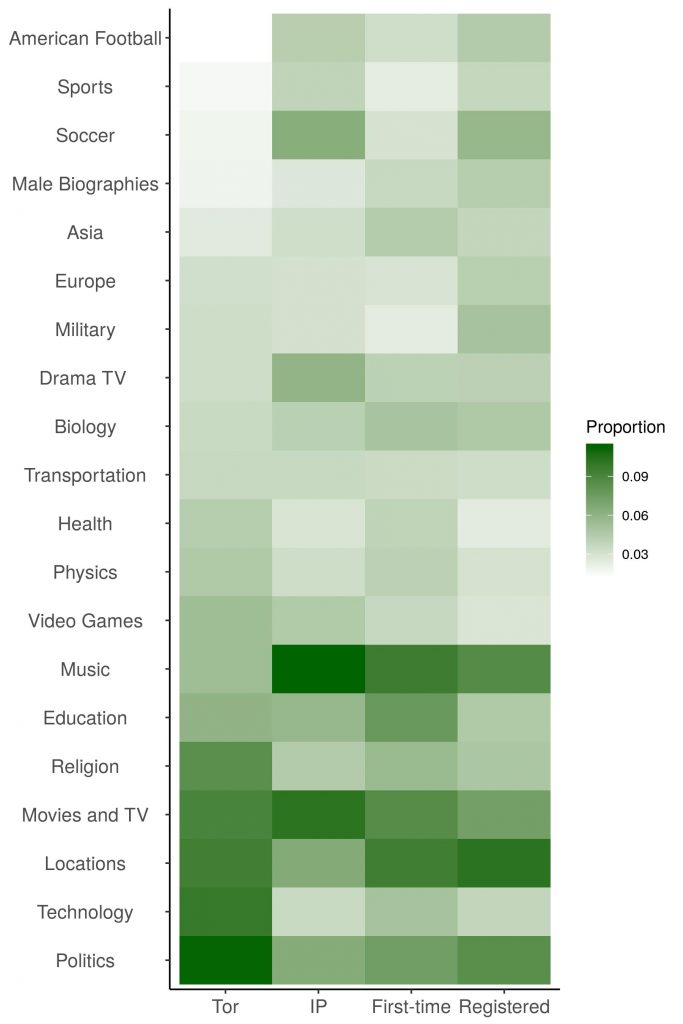
An image from the study showing the differences in topics edited by Tor users and other Wikipedia users. The image suggests that Tor users are more likely to edit pages discussing topics such as politics, religion, and technology. Other types of users, including IP, First-time, and Registered editors, are more likely to edit pages discussing topics such as music and sports.
We used a range of analytical techniques including direct parsing of article histories, manual inspections of article changes, and a machine learning platform called ORES to analyze contributions. We also used a machine learning technique called topic modeling to analyze Tor users’ areas of interest by checking their edits against clusters of keywords. We found that Tor-based editors are more likely than other users to focus on topics that may be considered controversial, such as politics, technology, and religion.
In a closely connected study led by Kaylea Champion and published several months ago in the Proceedings of the ACM on Human Computer Interaction (CSCW), we conducted a forensic qualitative analysis of contributions of the same dataset. Our results in that study are described in a separate blog post about that project and paint a complementary picture of Tor users engaged—in large part—in uncontroversial and quotidian types of editing behavior.
Across the two papers, our results are similar to other work that suggests that Tor users are very similar to other internet users. For example, one previous study has shown that Tor users frequently visit websites in the Alexa top one million.
Much of the discourse about anonymity online tends toward extreme claims backed up by very little in the way of empirical evidence or systematic study. Our work is a step toward remedying this gap and has implications for many websites that limit participation by users of anonymous browsing software like Tor. In the future, we hope to conduct similar systematic studies in contexts beyond Wikipedia.
Video of the conference presentation at the IEEE Symposium on Security & Privacy 2020 by Chau Tran.
In terms of Wikipedia’s own policy decisions about anonymous participation, we believe that our paper suggests that the benefits of a “pathway to legitimacy” for Tor contributors to Wikipedia might exceed the potential harm due to the value of their contributions. We are particularly excited about exploring ways to allow contributors from anonymity-seeking users under certain conditions: for example, requiring review prior to changes going live. Of course, these are questions for the Wikipedia community to decide but it’s a conversation that we hope our research can inform and that we look forward to participating in.
Paper Citation: Tran, Chau, Kaylea Champion, Andrea Forte, Benjamin Mako Hill, and Rachel Greenstadt. “Are Anonymity-Seekers Just like Everybody Else? An Analysis of Contributions to Wikipedia from Tor.” In 2020 IEEE Symposium on Security and Privacy (SP), 1:974–90. San Francisco, California: IEEE Computer Society, 2020. https://doi.org/10.1109/SP40000.2020.00053.








{kind=link}