The conference marks the official publication of four papers by collective students and faculty. All four papers were published in the journal Proceedings of the ACM on Human-Computer Interaction: CSCW.
Information on the talks as well as links to the papers are available here (CSCW members are listed in italics):
Mon, Nov 11 14:30 – 16:00: A Forensic Qualitative Analysis of Contributions to Wikipedia from Anonymity-Seeking Users by Kaylea Champion (UW), Nora McDonald (Drexel), Stephanie E Bankes (Drexel), Joseph Zhang (Drexel), Rachel Greenstadt (NYU), Andrea Forte (Drexel), Benjamin Mako Hill (UW). Kaylea will present! [Paper]
Mon, Nov 11 14:30 – 16:00: Wikipedia and Wiki Research
Salt, Kaylea, Charlie, Regina, and Kaylea will all be at the conference as will affiliate Andrés Monroy-Hernández and tons of our social computing friends. Please come and say “Hello” to any of us, introduce yourself if you don’t already know us, and pick up a CDSC sticker!
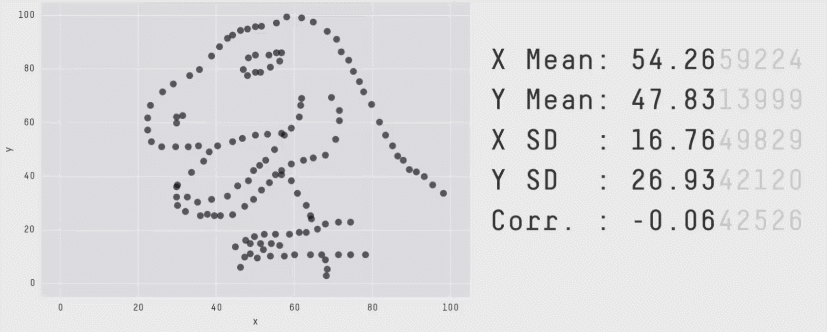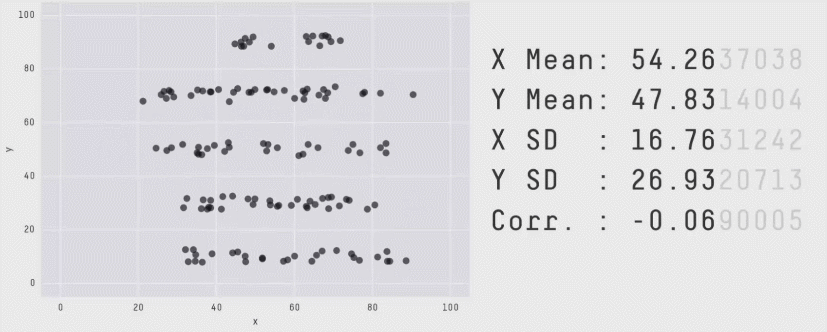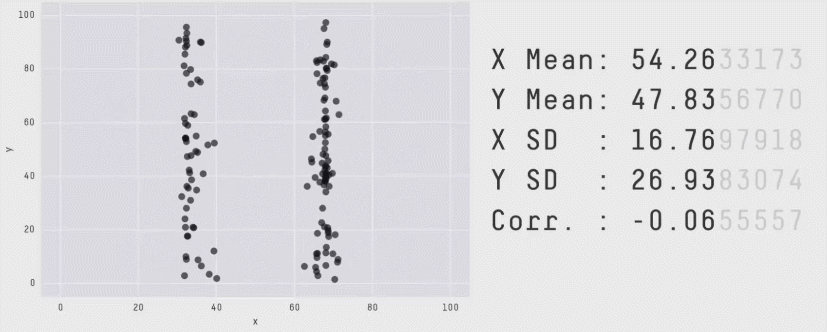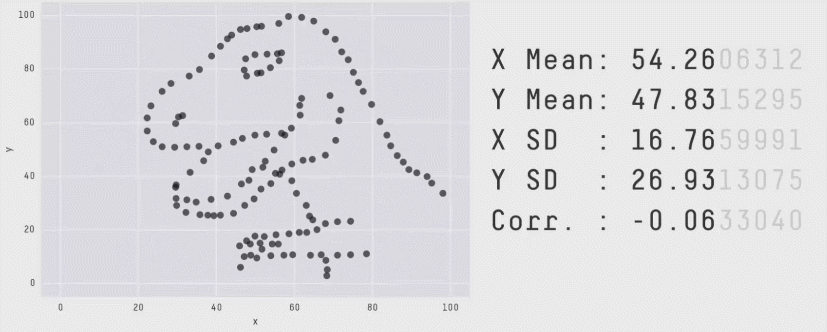
Why learning some statistics and some data visualization matters. (Gif from Matejka and Fitzmaurice, “Same stats, different graphs”, CHI 2017: https://dl.acm.org/citation.cfm?id=3025912)
I taught a graduate-level introduction to applied statistics and statistical computing this past Spring. The course design iterated on a class Mako developed in 2017. Very nearly all of the course materials are available open access through the Community Data Science Collective wiki and I wanted to make sure to share them more widely with this post. I’ve also been reflecting a bit on how the course went and thought I’d share those thoughts here in case anyone wants to adopt the course in the future.
First off, the course uses the OpenIntro Statistics (3rd edition) textbook as the core of the course readings and assignments. If you’re not familiar with OpenIntro and you want to learn or teach applied statistics from a general, social scientific perspective, you should check it out! All of the data, code, and LaTeX used to produce the textbook is licensed freely for reuse and the site also hosts video lectures, lecture notes, homework assignments, a discussion forum and more.
Alongside the OpenIntro materials, I worked together with Jeremy Foote (who was the TA for the course before he left to be new faculty at Purdue) to develop a bunch of tutorials in RMarkdown to help students complete the problem set assignments. We also posted worked solutions to the problem sets (also in RMarkdown). These replicated and expanded on screencasts Mako had recorded for his course.
The classroom sessions focused on discussion and problem solving. Basically, students came to each session knowing that I expected them to have completed the problem sets. I then did my best to answer any questions people had and assigned individuals (in some cases using a randomization script in R to pick names!) to summarize their solutions and approaches to specific problems that seemed important to cover.
It was my first time teaching a course like this and I had a few reflections after completing the quarter and reading through the feedback from students.
A major challenge for a course like this is pitching the material to an appropriate level given that students (in the MTS and TSB programs here at Northwestern at least) arrive with such varied knowledge of the subject matter. I think I did okay on this front in some ways and not in others. It was especially challenging given the semi-flipped classroom approach.
In some weeks, there was just too much material to cover in adequate depth. In some others, I was insufficiently organized and concise to cover everything. Whatever the case, I would cut back a bit next time. (I’ve noticed that this is a common issue for me the first time I teach any class, but I still struggle to correct it.)
Whatever challenges and failures I may have introduced in the design or instruction of the course, the students produced a bunch of highly original and engaging final projects. I’m optimistic that some of these projects will wind up as published work soon. Nothing like brilliant, motivated students to help the professor feel better about his own shortcomings!
Nearly all of the course materials are available on the CDSC wiki. The exceptions are a few of the readings and supplementary materials that I didn’t have the rights or desire to post on the public web. If you’re looking for any of that, feel free to send me an email and I can see if it’s appropriate to share.
Also, OpenIntro just came out with the fourth edition of their statistics textbook! I haven’t had a chance to check it out yet, but I’m eager to see what kinds of changes they introduced.
Introducing new technology into a work place is often disruptive, but what if your work was also completely mediated by technology? This is exactly the case for the teams of volunteer moderatorswho work to regulate content and protect online communities from harm. What happens when the social media platforms these communities rely on change completely? How do moderation teams overcome the challenges caused by new technological environments? How do they do so while managing a “brand new” community with tens of thousands of users?
For a new study that will be published in CSCW in November, we interviewed 14 moderators of 8 “subreddit” communities from the social media aggregation and discussion platform Reddit to answer these questions. We chose these communities because each community had recently adopted the real-time chat platform Discord to support real-time chat in their community. This expansion into Discord introduced a range of challenges—especially for the moderation teams of large communities.
We found that moderation teams of large communities improvised their own creative solutions to challenges they faced by building bots on top of Discord’s API. This was not too shocking given that APIs and bots are frequently cited as tools that allow innovation and experimentation when scaling up digital work. What did surprise us, however, was how important moderators’ past experiences were in guiding the way they used bots. In the largest communities that faced the biggest challenges, moderators relied on bots to reproduce the tools they had used on Reddit. The moderators would often go so far as to give their bots the names of moderator tools available on Reddit. Our findings suggest that support for user-driven innovation is important not only in that it allows users to explore new technological possibilities but also in that it allows users to mine their past experiences to introduce old systems into new environments.
What Challenges Emerged in Discord?
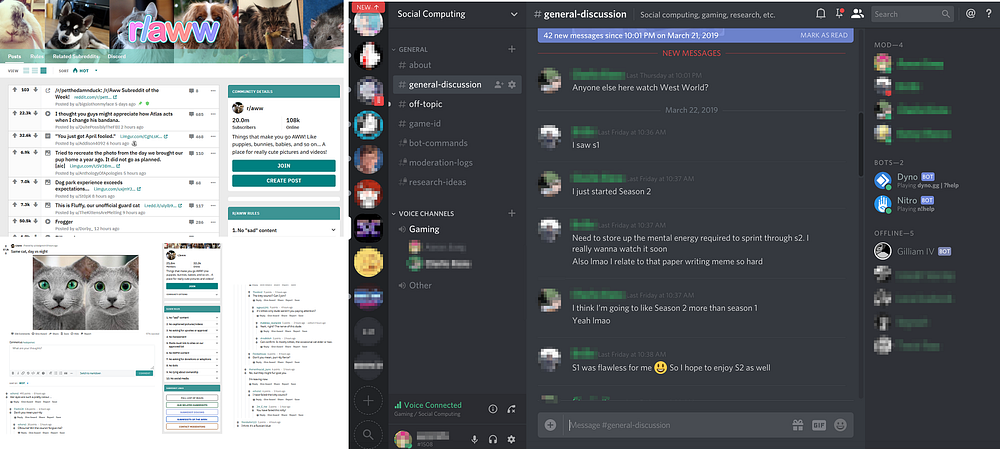
Left: A screenshot of the subreddit /r/aww. Right: A screenshot of a Discord server named “Social Computing”.
Discord’s text channels allow for more natural, in the moment conversations compared to Reddit. In Discord, this social aspect also made moderation work much more difficult. One moderator explained:
“It’s kind of rough because if you miss it, it’s really hard to go back to something that happened eight hours ago and the conversation moved on and be like ‘hey, don’t do that.’ ”
Moderators we spoke to found that the work of managing their communities was made even more difficult by their community’s size:
On the day to day of running 65,000 people, it’s literally like running a small city…We have people that are actively online and chatting that are larger than a city…So it’s like, that’s a lot to actually keep track of and run and manage.”
The moderators of large communities repeatedly told us that the tools provided to moderators on Discord were insufficient. For example, they pointed out tools like Discord’s Audit Log was inadequate for keeping track of the tens of thousands of members of their communities. Discord also lacks automated moderation tools like the Reddit’s Automoderator and Modmail leaving moderators on Discord with few tools to scale their work and manage communications with community members.
How Did Moderation Teams Overcome These Challenges?
The moderation teams we talked with adapted to these challenges through innovative uses of Discord’s API toolkit. Like many social media platforms, Discord offers a public API where users can develop apps that interact with the platform through a Discord “bot.” We found that these bots play a critical role in helping moderation teams manage Discord communities with large populations.
Guided by their experience with using tools like Automoderator on Reddit, moderators working on Discord built bots with similar functionality to solve the problems associated with scaled content and Discord’s fast-paced chat affordances. This bots would search for regular expressions and URLs that go against the community’s rules:
“It makes it so that rather than having to watch every single channel all of the time for this sort of thing or rely on users to tell us when someone is basically running amuck, posting derogatory terms and terrible things that Discord wouldn’t catch itself…so it makes it that we don’t have to watch every channel.”
Bots were also used to replace Discord’s Audit Log feature with what moderators referred to often as “Mod logs”—another term borrowed from Reddit. Moderators will send commands to a bot like “!warn username” to store information such as when a member of their community has been warned for breaking a rule and automatically store this information in a private text channel in Discord. This information helps organize information about community members, and it can be instantly recalled with another command to the bot to help inform future moderation actions against other community members.
Finally, moderators also used Discord’s API to develop bots that functioned virtually identically to Reddit’s Modmail tool. Moderators are limited in their availability to answer questions from members of their community, but tools like the “Modmail” helps moderation teams manage this problem by mediating communication to community members with a bot:
“So instead of having somebody DM a moderator specifically and then having to talk…indirectly with the team, a [text] channel is made for that specific question and everybody can see that and comment on that. And then whoever’s online responds to the community member through the bot, but everybody else is able to see what is being responded.”
The tools created with Discord’s API — customizable automated content moderation, Mod logs, and a Modmail system — all resembled moderation tools on Reddit. They even bear their names! Over and over, we found that moderation teams essentially created and used bots to transform aspects of Discord, like text channels into Mod logs and Mod Mail, to resemble the same tools they were using to moderate their communities on Reddit.
What Does This Mean for Online Communities?
We think that the experience of moderators we interviewed points to a potentially important underlooked source of value for groups navigating technological change: the potent combination of users’ past experience combined with their ability to redesign and reconfigure their technological environments. Our work suggests the value of innovation platforms like APIs and bots is not only that they allow the discovery of “new” things. Our work suggests that these systems value also flows from the fact that they allow the re-creation of the the things that communities already know can solve their problems and that they already know how to use.
Our work has several more specific takeaways as well. For moderators and community leaders:
Leaders of online communities planning to add an additional platform to host more discussion and social interactions for their community members should consider platforms with public APIs like Discord. You may run into challenges that the platform’s default tools are ineffective at solving, but public APIs allow for users to write software to solve their own problems.
For designers of online communities:
Designers of social media applications and platforms that host online communities should consider the effects of community growth and large population sizes on the work of moderation teams, who are often unpaid volunteers with limited time and resources to manage their communities.
Designers should also support a robust, public API for these applications and platforms. As our findings show, not every feature may be imagined in the creation of these platforms, but with a public API, users can drive the creation of custom solutions to unforeseen design problems. Our work suggests that these may be drawn from users unique knowledge of their problems as well as from their knowledge of existing solutions.
Paper Citation: Kiene, Charles, Jialun “Aaron” Jiang, and Benjamin Mako Hill. 2019. “Technological Frames and User Innovation: Exploring Technological Change in Community Moderation Teams.” Proceedings of the ACM: Human-Computer Interaction 3 (CSCW): 44:1-44:23.
Earlier this year, a team led by Kaylea Champion were announced as recipients of a generous grant from the Ford and Sloan Foundations to support research into into peer produced software infrastructure. Now that the project is moving forward in earnest, we’re thrilled to tell you about it.
Rapid Transit. Photo by Anthony Doudt, via flickr. CC BY-NC-ND 2.0
The project is motivated by the fact that peer production communities have produced awesome free (both as in freedom and beer) resources—sites like Wikipedia that gather the world’s knowledge, and software like Linux that enables innovation, connection, commerce, and discovery. Over the last two decades, these resources have become key elements of public digital infrastructure that many of us rely on every day. However, some pieces of digital infrastructure we rely on most remain relatively under-resourced—as security vulnerabilities like Heartbleed in OpenSSL reveal. The grant from Ford and Sloan aims will support a research effort to understand how and why some software packages that are heavily used receive relatively little community support and maintenance.
We’re tackling this challenge by seeking to measure and model patterns of usage, contribution, and quality in a population of free software projects. We’ll then try to identify causes and potential solutions to the challenges of relative underproduction. Throughout, we’ll draw on both insight from the research community and on-the-ground observations from developers and community managers. We aim to create practical guidance that communities and software developers can actually use as well as novel research contributions. Underproduction is, appropriately enough, a challenge that has not gotten much attention from researchers previously, so we’re excited to work on it.
Although Kaylea Champion is leading the project, the team working on the project includes Benjamin Mako Hill, Aaron Shaw, and collective affiliate Morten Warncke-Wang who did pioneering work on underproduction in Wikipedia.
In particular, we be presenting a new paper from the group led by Sneha Narayan titled “All Talk: How Increasing Interpersonal Communication on Wikis May Not Enhance Productivity.” The talk will be on Monday, May 27 in a session from 9:30 to 10:45 in Washington Hilton LL, Holmead as part of a session organized by the ICA Computational Methods section on “Computational Approaches to Health Communication.”
Additionally, Nate is co-organizing a pre-conference at ICA on “Expanding Computational Communication: Towards a Pipeline for Graduate Students and Early Career Scholars” along with Josephine Lukito (UW Madison) and Frederic Hopp (UC Santa Barbara). The pre-conference will be held at American University on Friday May 24th. As part of that workshop, Nate and Jeremy will be giving a presentation on approaches to the study organizational communication that use computational methods.
We look forward to sharing our research and socializing with you at ICA! Please be in touch if you’re around and want to meet up!
Informal online learning communities are one of the most exciting and successful ways to engage young people in technology. As the most successful example of the approach, over 40 million children from around the world have created accounts on the Scratch online community where they learn to code by creating interactive art, games, and stories. However, despite its enormous reach and its focus on inclusiveness, participation in Scratch is not as broad as one would hope. For example, reflecting a trend in the broader computing community, more boys have signed up on the Scratch website than girls.
In a recently published paper, I worked with several colleagues from the Community Data Science Collective to unpack the dynamics of unequal participation by gender in Scratch by looking at whether Scratch users choose to share the projects they create. Our analysis took advantage of the fact that less than a third of projects created in Scratch are ever shared publicly. By never sharing, creators never open themselves to the benefits associated with interaction, feedback, socialization, and learning—all things that research has shown participation in Scratch can support.
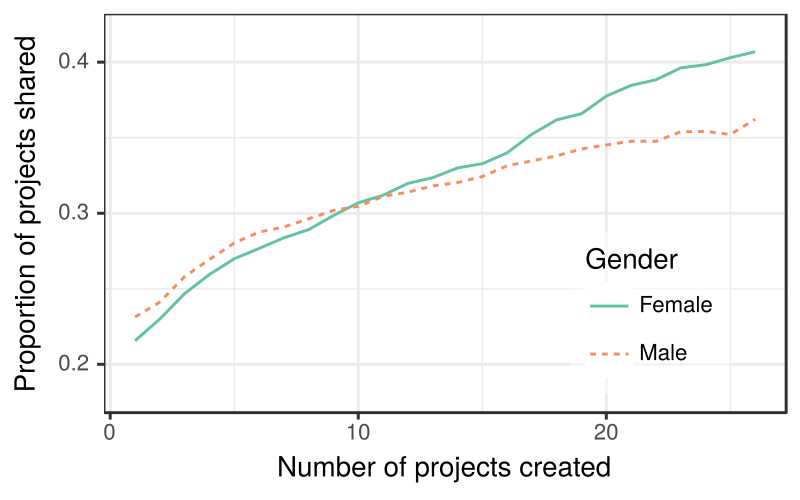
Overall, we found that boys on Scratch share their projects at a slightly higher rate than girls. Digging deeper, we found that this overall average hid an important dynamic that emerged over time. The graph below shows the proportion of Scratch projects shared for male and female Scratch users’ 1st created projects, 2nd created projects, 3rd created projects, and so on. It reflects the fact that although girls share less often initially, this trend flips over time. Experienced girls share much more than often than boys!
Proportion of projects shared by gender across experience levels, measured as the number of projects created, for 1.1 million Scratch users. Projects created by girls are less likely to be shared than those by boys until about the 9th project is created. The relationship is subsequently reversed.
We unpacked this dynamic using a series of statistical models estimated using data from over 5 million projects by over a million Scratch users. This set of analyses echoed our earlier preliminary finding—while girls were less likely to share initially, more experienced girls shared projects at consistently higher rates than boys. We further found that initial differences in sharing between boys and girls could be explained by controlling for differences in project complexity and in the social connectedness of the project creator.
Another surprising finding is that users who had received more positive peer feedback, at least as measured by receipt of “love its” (similar to “likes” on Facebook), were less likely to share their subsequent projects than users who had received less. This relation was especially strong for boys and for more experienced Scratch users. We speculate that this could be due to a phenomenon known in the music industry as “sophomore album syndrome” or “second album syndrome”—a term used to describe a musician who has had a successful first album but struggles to produce a second because of increased pressure and expectations caused by their previous success
Online anonymity often gets a bad rap and complaints about antisocial behavior from anonymous Internet users are as old as the Internet itself. On the other hand, research has shown that many Internet users seek out anonymity to protect their privacy while contributing things of value. Should people seeking to contribute to open collaboration projects like open source software and citizen science projects be required to give up identifying information in order to participate?
We conducted a two-part study to better understand how open collaboration projects balance the threats of bad behavior with the goal of respecting contributors’ expectations of privacy. First, we interviewed eleven people from five different open collaboration “service providers” to understand what threats they perceive to their projects’ mission and how these threats shape privacy and security decisions when it comes to anonymous contributions. Second, we analyzed discussions about anonymous contributors on publicly available logs of the English language Wikipedia mailing list from 2010 to 2017.
In the interview study, we identified three themes that pervaded discussions of perceived threats. These included threats to:
community norms, such as harrassment;
sustaining participation, such as loss of or failure to attract volunteers; and
contribution quality, low-quality contributions drain community resources.
We found that open collaboration providers were most concerned with lowering barriers to participation to attract new contributors. This makes sense given that newbies are the lifeblood of open collaboration communities. We also found that service providers thought of anonymous contributions as a way of offering low barriers to participation, not as a way of helping contributors manage their privacy. They imagined that anonymous contributors who wanted to remain in the community would eventually become full participants by registering for an account and creating an identity on the site. This assumption was evident in policies and technical features of collaboration platforms that barred anonymous contributors from participating in discussions, receiving customized suggestions, or from contributing at all in some circumstances. In our second study of the English language Wikipedia public email listserv, we discovered that the perspectives we encountered in interviews also dominated discussions of anonymity on Wikipedia. In both studies, we found that anonymous contributors were seen as “second-class citizens.”
This is not the way anonymous contributors see themselves. In a study we published two years ago, we interviewed people who sought out privacy when contributing to open collaboration projects. Our subjects expressed fears like being doxed, shot at, losing their job, or harassed. Some were worried about doing or viewing things online that violated censorship laws in their home country. The difference between the way that anonymity seekers see themselves and the way they are seen by service providers was striking.
One cause of this divergence in perceptions around anonymous contributors uncovered by our new paper is that people who seek out anonymity are not able to participate fully in the process of discussing and articulating norms and policies around anonymous contribution. People whose anonymity needs means they cannot participate in general cannot participate in the discussions that determine who can participate.
We conclude our paper with the observation that, although social norms have played an important role in HCI research, relying on them as a yardstick for measuring privacy expectations may leave out important minority experiences whose privacy concerns keep them from participating in the first place. In online communities like open collaboration projects, social norms may best reflect the most privileged and central users of a system while ignoring the most vulnerable
Both this blog post and the paper, Privacy, Anonymity, and Perceived Risk in Open Collaboration: A Study of Service Providers, was written by Nora McDonald, Benjamin Mako Hill, Rachel Greenstadt, and Andrea Forte and will be published in the Proceedings of the 2019 ACM CHI Conference on Human Factors in Computing Systems next week. The paper will be presented at the CHI conference in Glasgow, UK on Wednesday May 8, 2019. The work was supported by the National Science Foundation (awards CNS-1703736 and CNS-1703049).
The reproducibility movement in science has sought to increase our confidence in scientific knowledge by having research teams disseminate their data, instruments, and code so that other researchers can reproduce their work. Unfortunately, all approaches to reproducible research to date suffer from the same fundamental flaw: they seek to reproduce the results of previous research while making no effort to reproduce the research process that led to those results. We propose a new method of Exceedingly Reproducible Research (ERR) to close this gap. This blog post will introduce scientists to the error of their ways, and to the ERR of ours.
Even if a replication appears to have succeeded in producing tables and figures that appear identical to those in the original, they differ in that they are providing answers to different questions. An example from our own work illustrates the point.
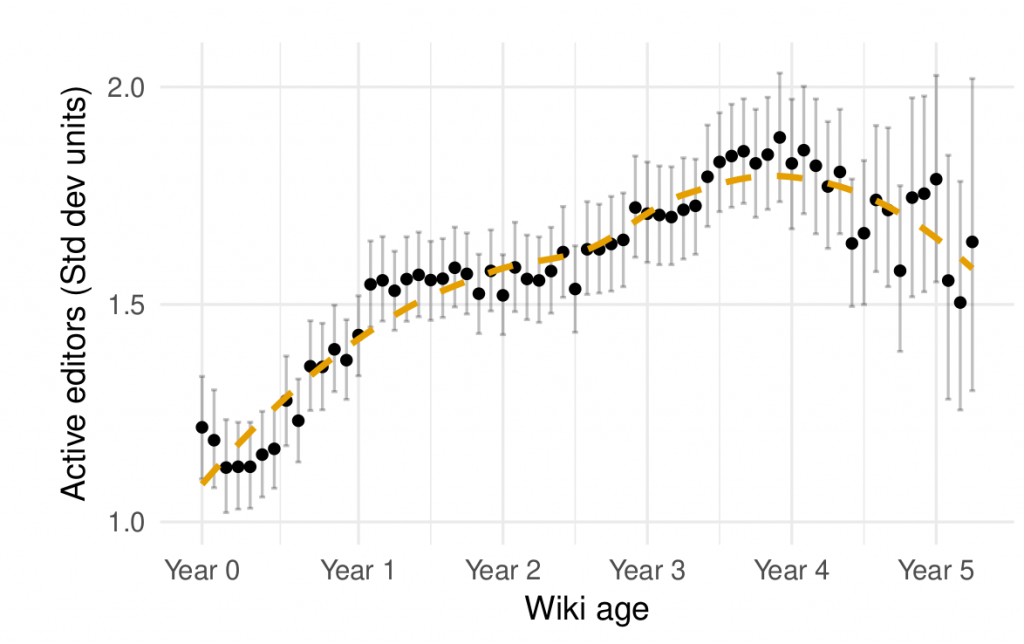
Figure 1: Active editors on Wikia wikis over time (taken from TeBlunthuis, Shaw, and Hill 2018)
Figure 1 above shows the average number of contributors (in standardized units) to a series of large wikis drawn from Wikia. It was created to show the life-cycles of large online communities and published in a paper last year.
Figure 2: Replication of Figure 1 from TeBlunthuis, Shaw, and Hill (2018)
Results from a replication are shown in Figure 2. As you can see, the plots have much in common. However, deeper inspection reveals that the similarity is entirely superficial. Although the dots and lines fall in the same places on the graphs, they fall there for entirely different reasons.
Tilting at windmills in Don Quixote.
Figure 1 reflects a lengthy exploration and refinement of a (mostly) original idea and told us something we did not know. Figure 2 merely tells us that the replication was “successful.” They look similar and may confuse a reader into thinking that they reflect the same thing. But they are as different as night as day. We are like Pierre Menard who reproduced two chapters of Don Quixote word-for-word through his own experiences: the image appears similar but the meaning is completely changed. In that we made no attempt to reproduce the research process, our attempt at replication was doomed before it began.
How Can We Do Better?
Scientific research is not made by code and data, it is made by people. In order to replicate a piece of work, one should reproduce all parts of the research. One must retrace another’s steps, as it were, through the garden of forking paths.
In ERR, researchers must conceive of the idea, design the research project, collect the data, write the code, and interpret the results. ERR involves carrying out every relevant aspect of the research process again, from start to finish. What counts as relevant? Because nobody has attempted ERR before, we cannot know for sure. However, we are reasonably confident that successful ERR will involve taking the same courses as the original scientists, reading the same books and articles, having the same conversations at conferences, conducting the same lab meetings, recruiting the same research subjects, and making the same mistakes.
There are many things that might affect a study indirectly and that, as a result, must also be carried out again. For example, it seems likely that a researcher attempting to ERR must read the same novels, eat the same food, fall prey to the same illnesses, live in the same homes, date and marry the same people, and so on. To ERR, one must have enough information to become the researchers as they engage in the research process from start to finish.
It seems likely that anyone attempting to ERR will be at a major disadvantage when they know that previous research exists. It seems possible that ERR can only be conducted by researchers who never realize that they are engaged in the process of replication at all. By reading this proposal and learning about ERR, it may be difficult to ever carry it out successfully.
Despite these many challenges, ERR has important advantages over traditional approaches to reproducibility. Because they will all be reproduced along the way, ERR requires no replication datasets or code. Of course, to verify that one is “in ERR” will require access to extensive intermediary products. Researchers wanting to support ERR in their own work should provide extensive intermediary products from every stage of the process. Toward that end, the Community Data Science Collective has started creating videos of our lab meetings in the form of PDF flipbooks well suited to deposition in our university’s institutional archives. A single frame is shown in Figure 3. We have released our video_to_pdf tool under a free license which you can use to convert your own MP4 videos to PDF.
Figure 3: PDF representation of one frame of a lab meeting between three members of the lab, produced using video_to_pdf. The full lab meeting is 25,470 pages (an excerpt is available).
With ERR, reproduction results in work that is as original as the original work. Only by reproducing the original so fully, so totally, and in such rigorous detail will true scientific validation become possible. We do not so much seek stand on the shoulders of giants, but rather to inhabit the body of the giant. If to reproduce is human; to ERR is divine.
In exciting news, Benjamin Mako Hill was just announced as a winner of a 2019 Research Symbiont Award. Mako received the second annual General Symbiosis Award which “is given to a scientist working in any field who has shared data beyond the expectations of their field.” The award was announced at a ceremony in Hawaii at the Pacific Symposium in Biocomputing.
A photo of the award itself: a plush fish complete with a parasitic lamprey.
The Research Symbionts Awards are given annually to recognize “symbiosis” in the form of data sharing. They are a companion award to the Research Parasite Awards which recognize superb examples of secondary data reuse. The award includes money to travel to the Pacific Symposium Computing (unfortunately, Mako wasn’t able to take advantage of this!) as well the plush fish with parasitic lamprey shown here.
In addition to the award given to Mako, Dr. Leonardo Collado-Torres was announced as the recipient of the health-specific Early Career Symobiont award for his work on Recount2.
I’ve heard a surprising “fact” repeated in the CHI and CSCW communities that receiving a best paper award at a conference is uncorrelated with future citations.
Although it’s surprising and counterintuitive, it’s a nice thing to
think about when you don’t get an award and its a nice thing to say to
others when you do. I’ve thought it and said it myself.
It also seems to be untrue. When I tried to check the “fact”
recently, I found a body of evidence that suggests that computing papers
that receive best paper awards are, in fact, cited more often than
papers that do not.
The source of the original “fact” seems to be a CHI 2009 study by Christoph Bartneck and Jun Hu titled “Scientometric Analysis of the CHI Proceedings.”
Among many other things, the paper presents a null result for a test of
a difference in the distribution of citations across best papers
awardees, nominees, and a random sample of non-nominees.
Although the award analysis is only a small part of Bartneck and Hu’s
paper, there have been at least two papers have have subsequently
brought more attention, more data, and more sophisticated analyses to
the question. In 2015, the question was asked by Jaques Wainer, Michael
Eckmann, and Anderson Rocha in their paper “Peer-Selected ‘Best Papers’—Are They Really That ‘Good’?“
Wainer et al. build two datasets: one of papers from 12 computer
science conferences with citation data from Scopus and another papers
from 17 different conferences with citation data from Google Scholar.
Because of parametric concerns, Wainer et al. used a non-parametric
rank-based technique to compare awardees to non-awardees. Wainer et al.
summarize their results as follows:
The probability that a best paper
will receive more citations than a non best paper is 0.72 (95% CI =
0.66, 0.77) for the Scopus data, and 0.78 (95% CI = 0.74, 0.81) for the
Scholar data. There are no significant changes in the probabilities for
different years. Also, 51% of the best papers are among the top 10% most
cited papers in each conference/year, and 64% of them are among the top
20% most cited.
Lee looked at 43,000 papers from 81 conferences and built a
regression model to predict citations. Taking into an account a number
of controls not considered in previous analyses, Lee finds that the
marginal effect of receiving a best paper award on citations is
positive, well-estimated, and large.
Why did Bartneck and Hu come to such a different conclusions than later work?
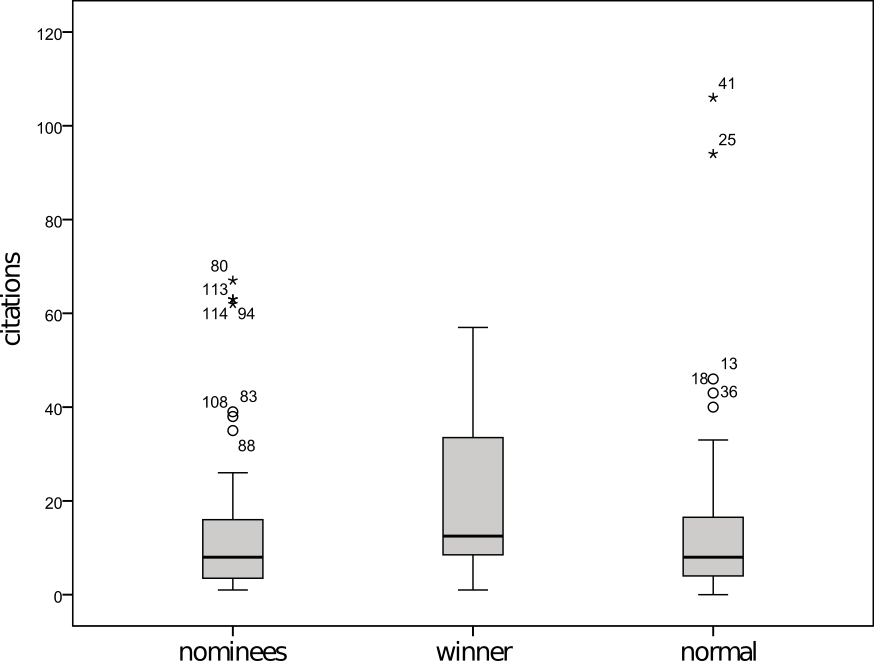
Distribution of citations (received by 2009) of CHI papers published between 2004-2007 that were nominated for a best paper award (n=64), received one (n=12), or were part of a random sample of papers that did not (n=76).
My first thought was that perhaps CHI is different than the rest of
computing. However, when I looked at the data from Bartneck and Hu’s
2009 study—conveniently included as a figure in their original study—you
can see that they did find a higher mean among the award
recipients compared to both nominees and non-nominees. The entire
distribution of citations among award winners appears to be pushed
upwards. Although Bartneck and Hu found an effect, they did not find a statistically significant effect.
Given the more recent work by Wainer et al. and Lee, I’d be willing
to venture that the original null finding was a function of the fact
that citations is a very noisy measure—especially over a 2-5
post-publication period—and that the Bartneck and Hu dataset was small
with only 12 awardees out of 152 papers total. This might have caused
problems because the statistical test the authors used was an omnibus
test for differences in a three-group sample that was imbalanced heavily
toward the two groups (nominees and non-nominees) in which their
appears to be little difference. My bet is that the paper’s conclusions
on awards is simply an example of how a null effect is not evidence of a
non-effect—especially in an underpowered dataset.
Of course, none of this means that award winning papers are better.
Despite Wainer et al.’s claim that they are showing that award winning
papers are “good,” none of the analyses presented can disentangle the
signalling value of an award from differences in underlying paper
quality. The packed rooms one routinely finds at best paper sessions at
conferences suggest that at least some additional citations received by
award winners might be caused by extra exposure caused by the awards
themselves. In the future, perhaps people can say something along these
lines instead of repeating the “fact” of the non-relationship.
This post was originally posted on Benjamin Mako Hill’s blog Copyrighteous.