Madison Deyo has recently joined the CDSC as a Program Coordinator and we couldn’t be more thrilled to welcome her to the team!
Madison is based at Northwestern. With the CDSC, Madison’s role includes a mix of event planning and coordination; outreach and communications; and supporting the operations of the group. She also works with the Northwestern Center for Human-Computer Interaction + Design. Madison brings experience working with community-based non-profits in several different capacities.
Madison currently lives in Chicago, and grew up in Wisconsin, where she attended the University of Wisconsin-Madison. There, she received my B.S. in Art (with a focus on illustration) and Communications: Radio-TV-Film. In addition to her position at Northwestern, Madison also works as a freelance artist designing mead labels, tattoos, and occasionally album/EP covers. You can check out her portfolio.
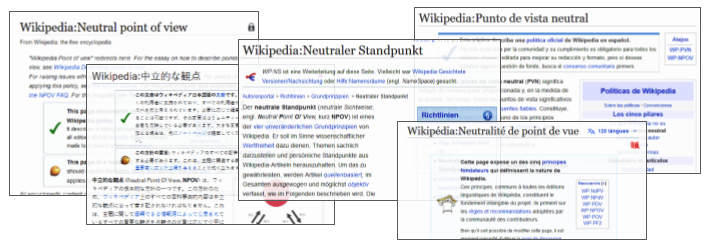
Screenshot of the same rule, Neutral Point of View, on five different language editions. Notably, the pages are different because they exist as connected but ultimately separate pages.
While Wikipedia is famous for its encyclopedic content, it may be surprising to realize that a whole other set of pages on Wikipedia help guide and govern the creation of the peer-produced encyclopedia. These pages extensively describe processes, rules, principles, and technical features of creating, coordinating, and organizing on Wikipedia. Because of the success of Wikipedia, these pages have provided valuable insights into how platforms might decentralize and facilitate participation in online governance. However, each language edition of Wikipedia has a unique set of such pages governing it respectively, even though they are part of the same overarching project: in other words, an under-explored opportunity to understand how governance operates across diverse groups.
In a manuscript published at ICWSM2022, we present descriptive analyses examining on rules and rule-making across language editions of Wikipedia motivated by questions like:
What happens when communities are both relatively autonomous but within a shared system? Given that they’re aligned in key ways, how do their rules and rule-making develop over time? What can patterns in governance work tell us about how communities are converging or diverging over time?
We’ve been very fortunate to share this work with the Wikimedia community since publishing the paper, such as the Wikipedia Signpost and Wikimedia Research Showcase. At the end of last year, we published the replication data and files on Dataverse after addressing a data processing issue we caught earlier in the year (fortunately, it didn’t affect the results – but yet another reminder to quadruple-check one’s data pipeline!). In the spirit of sharing the work more broadly since the Dataverse release, we summarize some of the key aspects of the work here.
Study design
In the project, we examined the five largest language editions of Wikipedia as distinct editing communities: English, German, Spanish, French and Japanese. After manually constructing lists of rules per wiki (resulting in 780 pages), we took advantage of two features on Wikipedia: the revision histories, which log every edit to every page; and the interlanguage links, which connect conceptually equivalent pages across language editions. We then conducted a series of analyses examining comparisons across and relationships between language editions.
Shared patterns across communities
Across communities, we observed that trends suggested that rule-making often became less open over time:
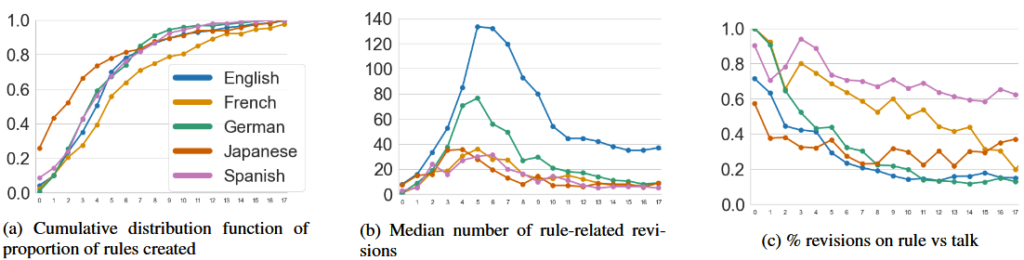
Figure 2 from the ICWSM paper
Most rules are created early in the life of the language edition community’s life. Over a nearly 20 year period, roughly 50-80% of the rules (depending on the language edition) were created within the first five years!
The median edit count to rule pages peaked in early years (between years 3 and 5) before tapering down. The percent of revisions dedicated to editing the actual rule text versus discussing it shifts towards discussion of rule across communities. These both suggest that rules across communities have calcified over time.
Said simply, these communities have very similar trends in rule-making towards formalization.
Divergence vs convergence in rules
Wikipedia’s interlanguage link (ILL) feature, as mentioned above, lets us explore how the rules being created and edited on communities relate to one another. While the trends above highlight similarities in rule-making, here, the picture about how the rule sets are similar or not is a bit more complicated.
On one hand, the top panel here shows that over time, all five communities see an increase in the proportion of rules in their rules sets that are unique to them individually. On the other hand, the bottom panel shows that editing efforts concentrate on rules that are more shared across communities.
Altogether, we see that communities sharing goals, technology, and a lot more develop substantial and sustained institutional variations; but it’s possible that broad, widely-shared rules created early may help keep them relatively aligned.
Key takeaways
Investigating governance across groups like Wikipedia is valuable for at least two reasons.
First, an enormous amount of effort has gone into studying governance on English Wikipedia, the largest and oldest language edition, to distill lessons about how we can meaningfully decentralize governance in online spaces. But, as prior work [e.g., 1] shows, language editions are often non-aligned in both the content they produce and how they organize that content. Some early stage work we did noted this held true for rule pages on the five language editions of Wikipedia explored here. In recent years, the Wikimedia Foundation itself has made several calls to understand dynamics and patterns beyond English Wikipedia. This work is in part in response to this movement.
Second, the questions explored in our work highlight a key tension in online governance today. While online communities are relatively autonomous entities, they often exist within social and technical systems that put them in relation with one another – whether directly or not. Effectively addressing concerns about online governance means understanding how distinct spaces online govern in ways that are similar or dissimilar, overlap or conflict, diverge and converge. Wikipedia can offer many lessons to this end because it has an especially decentralized and participatory vision of how to govern itself online, such as how patterns of formalization impact success and engagement. Future work we are working on continues in this vein – stay tuned!
Although the world relies on free/libre open source software (FLOSS) for essential digital infrastructure such as the web and cloud, the software that supports that infrastructure are not always as high quality as we might hope, given our level of reliance on them. How can we find this misalignment of quality and importance (or underproduction) before it causes major failures?
How can we find misalignment of quality and importance (underproduction) before it causes major failures?
In previous work, we found that underproduction is widespread in packages maintained by the Debian community, and when we shared this work in the Debian and FLOSS community, developers suggested that the age and language of the packages might be a factor, and tech managers suggested looking at the teams doing the maintenance work. Software engineering literature had found some support for these suspicions as well, and we embarked on a study to dig deeper into some of the factors associated with underproduction.
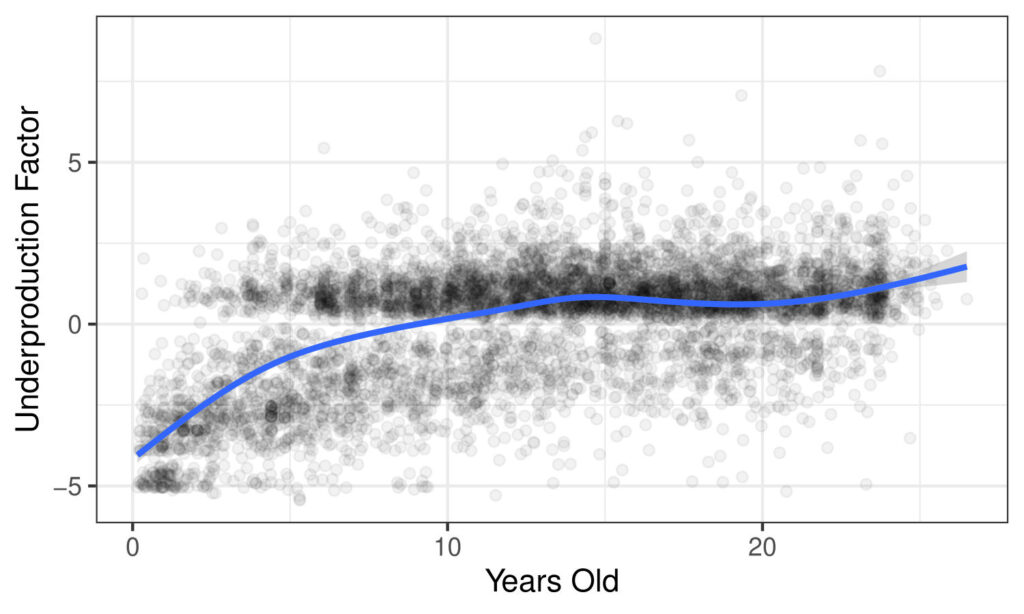
Our study was able to partially confirm this perspective using the underproduction analysis dataset from our previous study: software risk due to underproduction increases with age of both the package and its language, although many older packages and those written in older languages are and continue to be very well-maintained.
In this plot, dots represent software packages and their age, with higher underproduction factor indicating higher risk. The blue line is a smoothed average: note that we see an increase over time initially, but the trend flattens out for older packages.
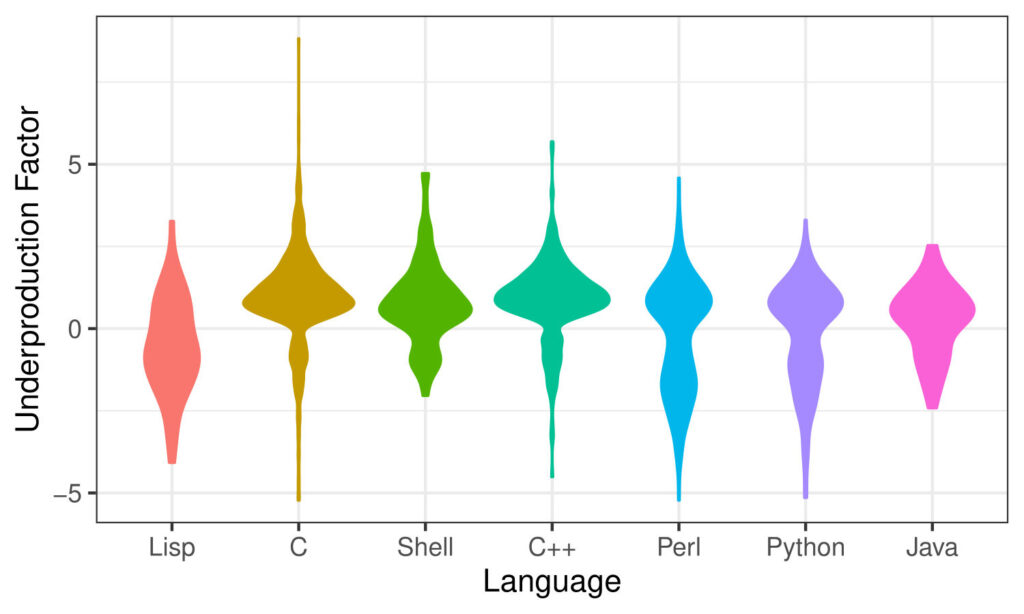
This plot shows the spread of the data across the range of underproduction factor, grouped by language, where higher values are indications of higher risk. Languages are sorted from oldest on the left (Lisp) to youngest on the right (Java). Although newer languages overall are associated with lower risk, we see a great deal of variation.
However, we found the resource question more complex: additional contributors were associated with higher risk instead of decreasing it as we hypothesized. We also found that underproduction is associated with higher eigenvector centrality in the network formed if we take packages as nodes and edges by having shared maintainers; that is, underproduced packages were likely to be maintained by the same people maintaining other parts of Debian, and not isolated efforts. This suggests that these high-risk packages are drawing from the same resource pool as those which are performing well. A lack of turnover in maintainership and being maintained by a team were not statistically significant once we included maintainer network structure and age in our model.
How should software communities respond? Underproduction appears in part to be associated with age, meaning that all communities sooner or later may need to confront it, and new projects should be thoughtful about using older languages. Distributions and upstream project developers are all part of the supply chain and have a role to play in the work of preventing and countering underproduction. Our findings about resources and organizational structure suggest that “more eyeballs” alone are not the answer: supporting key resources may be of particular value as a means to counter underproduction.
This work would not have been possible without the generosity of the Debian community. We are indebted to thesevolunteers who, in addition to producing Free/Libre Open Source Software software, have also made their records available to the public. We also gratefully acknowledge support from the Sloan Foundation through the Ford/Sloan DigitalInfrastructure Initiative, Sloan Award 2018-11356 as well as the National Science Foundation (Grant IIS-2045055). This work was conducted using the Hyak supercomputer at the UniversityofWashingtonaswellasresearchcomputing resources at Northwestern University.
What structure and rules are best for communities producing high-quality free/libre and open source software (FLOSS)? The stakes are high: cybersecurity researchers are raising the alarm about cybersecurity risk due to undermaintained components in the global software supply chain—much of which is FLOSS. In work that’s just been accepted to the IEEE International Conference on Software Analysis, Evolution and Reengineering (‘SANER’), we studied 182 Python-language packages in the GNU/Linux Debian distribution, examining the relationship between their levels of engineering formality and software risk. We found that more formal developer organization is associated with higher levels of software risk, and more widely spread developer responsibility is associated with lower levels of software risk.
We studied software risk through the underproduction metric initially developed by Champion and Hill (2021). Underproduction is a measurement of misalignment between the usage demands of a software project and the contributions of the project’s developer community. As such, underproduction measures the risk that software will be undermaintained, possibly including a security bug.
Our work examines the relationship between risk due to underproduction and governance formality. We employed measures initially developed by Tamburri et al. (2013) and later re-implemented in Tamburri et al. (2019). These metrics use multiple measures of software project formality — such as the average contributor type, usage of GitHub milestones, and age — to evaluate how formally structured a given project is.
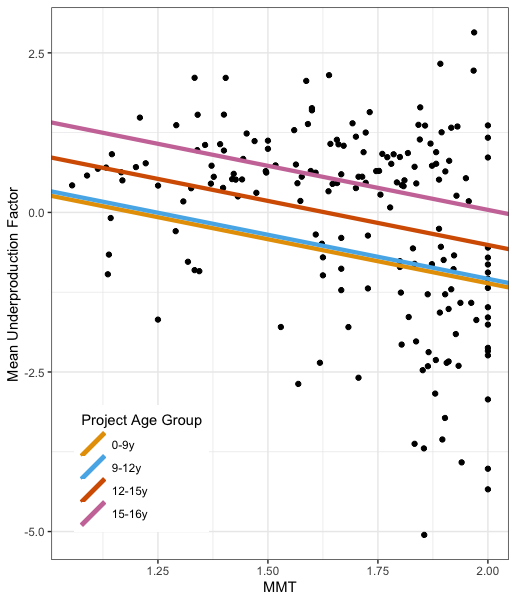
Plot of the relationship between mean underproduction factor and mean membership type (MMT), a metric encapsulating the diffusion of merge responsibility across a project’s developer community.
We used linear regression to conclude that more formal project structures are associated with higher levels of underproduction and thus, increased project risk. We also found that the share of community-members who have merged code into the main development branch is also related to underproduction, with lower levels of underproduction correlated with larger shares of community mergers.
Evaluated together, these two conclusions suggest that operating less formally and sharing power more equally is associated with lower underproduction risk. The development of FLOSS project engineering is a process laden with tradeoffs, we hope that our conclusions can help better inform community decision making and organization.
For more details, visualizations, statistics, and more, we hope you’ll take a look at our paper. If you are attending SANER in March 2024, we hope you’ll talk to us in Rovaniemi, Finland!
—————
The full citation for the paper is:
Gaughan, Matthew, Champion, Kaylea, and & Hwang, Sohyeon. (2024) “Engineering Formality and Software Risk in Debian Python Packages.” In 31st IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER2024) (Short Paper and Posters Track). Rovaniemi, Finland.
We have also released replication materials for the paper, including all the data and code used to conduct the analyses.
Wikipedia is one of the most visited websites in the world and the largest online repository of human knowledge. It is also both a target of and a defense against misinformation, disinformation, and other forms of online information manipulation. Importantly, its 300 language editions are self-governed—i.e., they set most of their rules and policies. Our new paper asks: What types of governance arrangements make some self-governed online groups more vulnerable to disinformation campaigns? We answer this question by comparing two Wikipedia language editions—Croatian and Serbian Wikipedia. Despite relying on common software and being situated in a common sociolinguistic environment, these communities differed in how successfully they responded to disinformation-related threats.
For nearly a decade, the Croatian language version of Wikipedia was run by a cabal of far-right nationalists who edited articles in ways that promoted fringe political ideas and involved cases of historical revisionism related to the Ustaše regime, a fascist movement that ruled the Nazi puppet state called the Independent State of Croatia during World War II. This cabal seized complete control of the governance of the encyclopedia, banned and blocked those who disagreed with them, and operated a network of fake accounts to give the appearance of grassroots support for their policies.
Thankfully, Croatian Wikipedia appears to be an outlier. Though both the Croatian and Serbian language editions have been documented to contain nationalist bias and historical revisionism, Croatian Wikipedia alone seems to have succumbed to governance capture: a takeover of the project’s mechanisms and institutions of governance by a small group of users.
The situation in Croatian Wikipedia was well-documented and is now largely fixed, but still know very little about why Croatian Wikipedia was taken over, while other language editions seem to have rebuffed similar capture attempts. In a new paper that is accepted for publication in the Proceedings of the ACM: Human-Computer Interaction (CSCW), we present an interview-based study that tries to explain why Croatian was captured while several other editions facing similar contexts and threats fared better.
Short video presentation of the work given at Wikimania in August 2023.
We interviewed 15 participants from both the Croatian and Serbian Wikipedia projects, as well as the broader Wikimedia movement. Based on insights from these interviews, we arrived at three propositions that, together, help explain why Croatian Wikipedia succumbed to capture while Serbian Wikipedia did not:
Perceived Value as a Target. Is the project worth expending the effort to capture?
Bureaucratic Openness. How easy is it for contributors outside the core founding team to ascend to local governance positions?
Institutional Formalization. To what degree does the project prefer personalistic, informal forms of organization over formal ones?
The conceptual model from our paper, visualizing possible institutional configurations among Wikipedia projects that affect the risk of governance capture.
We found that both Croatian Wikipedia and Serbian Wikipedia were attractive targets for far-right nationalist capture due to their sizable readership and resonance with a national identity. However, we also found that the two projects diverged early on in their trajectories in terms of how open they remained to new contributors ascending to local governance positions and the degree to which they privileged informal relationships over formal rules and processes as organizing principles of the project. Ultimately, Croatian’s relative lack of bureaucratic openness and rules constraining administrator behavior created a window of opportunity for a motivated contingent of editors to seize control of the governance mechanisms of the project.
Though our empirical setting was Wikipedia, our theoretical model may offer insight into the challenges faced by self-governed online communities more broadly. As interest in decentralized alternatives to Facebook and X (formerly Twitter) grows, communities on these sites will likely face similar threats from motivated actors. Understanding the vulnerabilities inherent in these self-governing systems is crucial to building resilient defenses against threats like disinformation.
For more details on our findings, take a look at the preprint of our paper.
Preprint on arxiv.org: https://arxiv.org/abs/2311.03616. The paper has been accepted for publication in Proceedings of the ACM on Human-Computer Interaction (CSCW) and will be presented at CSCW in 2024. This blog post and the paper it describes are collaborative work by Zarine Kharazian, Benjamin Mako Hill, and Kate Starbird.
Do you care about community, design, computing, and research? We are looking for a person to grow the public impact of the Community Data Science Collective (CDSC) and Northwestern University Center for Human Computer Interaction +Design (HCI+D). We are hiring a full time Program Coordinator to work in both groups. This person will focus on outreach, communications, research community development, strategic event planning, and administration for both the CDSC and HCI+D.
Although a portion of the work may be done remotely, attendance for in-person meetings and workshops is required and the position is located in Evanston on the Northwestern University campus. The average salary for similar positions at Northwestern is around $55,000 per year and includes excellent benefits (compensation details for this position can only be determined by Northwestern HR in the hiring process). We’re looking for a minimum 2 year commitment.
Duties
These fall into four categories, with specific examples in each listed below:
Outreach & communications
Manage social media posting (LinkedIn, Mastodon, X, WordPress etc.)
Post events to listservs and websites
Advertise events such as the Collective’s “Science of Community” series and the Center’s “Thought Leader Dialogues”
Build contact-lists around specific events and topics
Share messages with internal and external audiences
Research community development
Recruit participants to community events
Organize group retreats (3-4 year total)
Engage with community members of both the Collective and Center
Strategic event planning
Develop and execute a strategic event plan for in-person/virtual events
Collaborate with Collective and Center members to plan and recruit speakers for events
Administration:
Schedule and plan research meetings
Track and report on collective and center achievements
Draft annual research and donor reports
Document processes and initiatives
Core competencies:
Ability to use and learn web content management tools, such as wordpress, and wikis.
General organization
Communication (be clear, be concise)
Meeting facilitation
Managing upwards
Small/medium scale (20-50 people) event planning
Creative thinking and problem solving
Qualifications
Candidates must hold at least a bachelor’s degree. Familiarity with event planning, community management, project management, and/or scientific research is a plus, as is prior experience in the social or computer sciences, research organizations, online communities, and/or public interest technology and advocacy projects of any kind.
About Northwestern’s Center for HCI+Design and the Community Data Science Collective
The Community Data Science Collective is an interdisciplinary research group made up of faculty, students, and affiliates mainly at the University of Washington Department of Communication, the Northwestern University Department of Communication Studies, the Carleton College Computer Science Department, and the Purdue University School of Communication. To learn more about the Community Data Science Collective, you should check out our wiki, blog, and recent publications.
Northwestern’s Center for Human Computer Interaction + Design is an interdisciplinary research center that brings together researchers and practitioners from across the University to study, design, and develop the future of human and computer interaction at home, work, and play in the pursuit of new interaction paradigms to support a collaborative, sustainable, and equitable society.
Contact
Please contact Aaron Shaw with questions. Both the CDSC and the Center for HCI+D are committed to creating diverse, inclusive, equitable, and accessible environments and we look forward to working with someone who shares these values.
Ready to apply?
Please apply via the Northwestern University job posting (and note that the job ID is 49284). We will begin reviewing applications immediately (continuing on a rolling basis until the position is filled).
Taboo subjects—such as sexuality and mental health—are as important to discuss as they are difficult to raise in conversation. Although many people turn to online resources for information on taboo subjects, censorship and low quality information are common in search results. In work that has just been published at CSCW this week, we present a series of analyses that describe how taboo shapes the process of collaborative knowledge building on English Wikipedia. Our work shows that articles on taboo subjects are much more popular and the subject of more vandalism than articles on non-taboo topics. In surprising news, we also found that they were edited more often and were of higher quality! We also found that contributors to taboo articles did less to hide their identity than we expected.
Short video of a our presentation of the work given at Wikimania in August 2023.
The first challenge we faced in conducting our study was building a list of Wikipedia articles on taboo topics. This was challenging because while taboo is deeply cultural and can seem natural, our individual perspectives of what is and isn’t taboo is privileged and limited. In building our list, we wanted to avoid relying on our own intuition about what qualifies as taboo. Our approach was to make use of an insight from linguistics: people develop euphemisms as ways to talk about taboos. Think about all the euphemisms we’ve devised for death, or sex, or menstruation, or mental health. Using figurative languages lets us distance ourselves from the pollution of a taboo.
We used this insight to build a new machine learning classifier based on dictionary definitions in English Wiktionary. If a ‘sense’ of a word was tagged as a euphemism, we treated the words in the definition as indicators of taboo. The end result of this analysis is a series of words and phrases that most powerfully differentiate taboo from non-taboo. We then did a simple match between those words and phrases and Wikipedia article titles. We built a comparison sample of articles whose titles are words that, like our taboo articles, appear in Wiktionary definitions.
We used this new dataset to test a series of hypotheses about how taboo shapes collaborative production in Wikipedia. Our initial hypotheses were based on the idea that taboo information is often in high demand but that Wikipedians might be reluctant to associate their names (or usernames) with taboo topics. The result, we argued, would be articles that were in high demand but of low quality. What we found was that taboo articles are thriving on Wikipedia! In summary, we found in comparison to non-taboo articles:
Taboo articles are more popular (as expected).
Taboo articles receive more contributions (contrary to expectations).
Taboo articles receive more low-quality contributions (as expected).
Taboo articles are higher quality (contrary to expectations).
Taboo article contributors are more likely to contribute without an account (as expected), and have less experience (as expected), but that accountholders are more likely to make themselves more identifiable by having a user page, disclosing their gender, and making themselves emailable (all three of these are contrary to expectation!).
For more details, visualizations, statistics, and more, we hope you’ll take a look at our paper. If you are attending CSCW in October 2023, we also hope and come to our CSCW presentation in Minneapolis!
The full citation for the paper is: Champion, Kaylea, and Benjamin Mako Hill. 2023. “Taboo and Collaborative Knowledge Production: Evidence from Wikipedia.” Proceedings of the ACM on Human-Computer Interaction 7 (CSCW2): 299:1-299:25. https://doi.org/10.1145/3610090.
It’s Ph.D. application season and the Community Data Science Collective is recruiting! As always, we are looking for talented people to join our research group. Applying to one of the Ph.D. programs that the CDSC faculty members are affiliated with is a great way to get involved in research on communities, collaboration, and peer production.
Because we know that you may have questions for us that are not answered in this webpage, we will be hosting an open house and Q&A about the CDSC and Ph.D. opportunities on Friday, October 20 at 18:00 UTC (2:00pm US Eastern, 1:00pm US Central, 11:00am US Pacific). You can register online.
This post provides a very brief run-down on the CDSC, the different universities and Ph.D. programs our faculty members are affiliated with, and some general ideas about what we’re looking for when we review Ph.D. applications.
Group photo of the collective at a recent retreat.
What are these different Ph.D. programs? Why would I choose one over the other?
This year the group includes three faculty principal investigators (PIs) who are actively recruiting PhD students: Aaron Shaw (Northwestern University), Benjamin Mako Hill (University of Washington in Seattle), and Jeremy Foote (Purdue University). Each of these PIs advise Ph.D. students in Ph.D. programs at their respective universities. Our programs are each described below.
Although we often work together on research and serve as co-advisors to students in each others’ projects, each faculty person has specific areas of expertise and interests. The reasons you might choose to apply to one Ph.D. program or to work with a specific faculty member could include factors like your previous training, career goals, and the alignment of your specific research interests with our respective skills.
At the same time, a great thing about the CDSC is that we all collaborate and regularly co-advise students across our respective campuses, so the choice to apply to or attend one program does not prevent you from accessing the expertise of our whole group. But please keep in mind that our different Ph.D. programs have different application deadlines, requirements, and procedures!
Faculty who are actively recruiting this year
If you are interested in applying to any of the programs, we strongly encourage you to reach out the specific faculty in that program before submitting an application.
Ph.D. Advisors
Jeremy Foote
Jeremy Foote is an Assistant Professor at the Brian Lamb School of Communication at Purdue University. He is affiliated with the Organizational Communication and Media, Technology, and Society programs. Jeremy’s research focuses on how individuals decide when and in what ways to contribute to online communities, how communities change the people who participate in them, and how both of those processes can help us to understand which things become popular and influential. Most of his research is done using data science methods and agent-based simulations.
Benjamin Mako Hill
Benjamin Mako Hill is an Associate Professor of Communication at the University of Washington. He is also adjunct faculty at UW’s Department of Human-Centered Design and Engineering (HCDE), Computer Science and Engineering (CSE) and Information School. Although many of Mako’s students are in the Department of Communication, he has also advised students in all three other departments—although he typically has more limited ability to admit students into those programs on his own and usually does so with a co-advisor in those departments. Mako’s research focuses on population-level studies of peer production projects, computational social science, efforts to democratize data science, and informal learning. Mako has also put together a webpage for prospective graduate students with some useful links and information..
AaronShaw is an Associate Professor in the Department of Communication Studies at Northwestern. In terms of Ph.D. programs, Aaron’s primary affiliations are with the Media, Technology and Society (MTS) and the Technology and Social Behavior (TSB) Ph.D. programs (please note: the TSB program is a joint degree between Communication and Computer Science). Aaron also has a courtesy appointment in the Sociology Department at Northwestern, but he has not directly supervised any Ph.D. advisees in that department (yet). Aaron’s current projects focus on comparative analysis of the organization of peer production communities and social computing projects, participation inequalities in online communities, and collaborative organizing in pursuit of public goods.
What do you look for in Ph.D. applicants?
There’s no easy or singular answer to this. In general, we look for curious, intelligent people driven to develop original research projects that advance scientific and practical understanding of topics that intersect with any of our collective research interests.
To get an idea of the interests and experiences present in the group, read our respective bios and CVs (follow the links above to our personal websites). Specific skills that we and our students tend to use on a regular basis include consuming and producing social science and/or social computing (human-computer interaction) research; applied statistics and statistical computing, various empirical research methods, social theory and cultural studies, and more.
Formal qualifications that speak to similar skills and show up in your resume, transcripts, or work history are great, but we are much more interested in your capacity to learn, think, write, analyze, and/or code effectively than in your credentials, test scores, grades, or previous affiliations. It’s graduate school and we do not expect you to show up knowing how to do all the things already.
Intellectual creativity, persistence, and a willingness to acquire new skills and problem-solve matter a lot. We think doctoral education is less about executing tasks that someone else hands you and more about learning how to identify a new, important problem; develop an appropriate approach to solving it; and explain all of the above and why it matters so that other people can learn from you in the future. Evidence that you can or at least want to do these things is critical. Indications that you can also play well with others and would make a generous, friendly colleague are really important too.
All of this is to say, we do not have any one trait or skill set we look for in prospective students. We strive to be inclusive along every possible dimension. Each person who has joined our group has contributed unique skills and experiences as well as their own personal interests. We want our future students and colleagues to do the same.
Now what?
Still not sure whether or how your interests might fit with the group? Still have questions? Still reading and just don’t want to stop? Follow the links above for more information. Feel free to send at least one of us an email. We are happy to try to answer your questions and always eager to chat. You can also join our open house on October 20 at 2:00pm ET (UTC-4).
Welcome to a bonus round of our series spotlighting the excellent talks we were fortunate enough to host during the Science of Community track at FOSSY 23!
Eriol Fox presented their talk, “Community lead user research and usability in Science and Research OSS: What we learned,” (due to scheduling issues, this landed in the Wildcard track, but it was definitely on-topic for Science of Community! Eriol introduced us to their work exploring how scientists and researchers think about open source software, including differences in norms and motivations as well as challenges around the structure of labor. They also brought along copies of their 4 super cool zines from this project!
You can watch the talk HERE and learn more about Eriol’s work HERE.
Welcome to part 7 of a 7-part series spotlighting presentations from the Science of Community track at FOSSY 23!
In this interactive session, Dr. Benjamin Mako Hill, Dr. Aaron Shaw, and Kaylea Champion hosted a series of conversations with FOSS community members about finding research, putting it to use, and building partnerships between researchers and communities!
This talk was (intentionally!) not recorded, but we’ve synthesized the resources we shared into this wiki page.