We love celebrating the accomplishments of CDSC lab and community members! Here’s a less-than-complete, not-quite-brief summary of some of those accomplishments over the past academic year+ (since the last time we wrote a post like this). Congratulations to everyone involved—including those members of the CDSC community not named below. It truly takes a village to do all of these things and we appreciate the achievements and contributions of all.
Awards, degrees, and fellowships:
- Hazel Chiu received a Top Paper Award from the International Communication Association (ICA) Communication and Technology (CaT) Division for “User Acceptance of Multiple Accounts Management on SNS: A Technology Acceptance Model Perspective.”
- Nathan TeBlunthuis received a Top Paper Award from the ICA Computational Methods (CM) Division for “Misclassification in Automated Content Analysis Causes Bias in Regression. Can We Fix It? Yes We Can!.”
- Dyuti Jha and Ryan Funkhouser were named runners-up for the National Communication Association (NCA) Sam Keltner Top Student paper for “Freedom to flourish: A systematic review of the literature at the intersection of resilience, communication, and peacebuilding.”
- Floor Fiers completed their Ph.D. and will begin a new role as an Assistant Professor of Communication at the University of Amsterdam.
- Nathan TeBlunthuis will begin a new role as an Assistant Professor in the Information School at the University of Texas, Austin.
- Tommy Rousse completed his J.D. and MTS Ph.D. at Northwestern.
- Sohyeon Hwang will begin a Postdoctoral Fellowship at the Center for Information Technology & Policy (CITP) at Princeton University in the Fall.
- Yibin Fan completed a Master’s degree in Communication at the University of Washington.
- Benjamin Mako Hill was a fellow at CITP at Princeton University during 2023-2024.
- Emily Zou graduated with honors from Northwestern in American Studies with her thesis, “`Did Bro Just Grief the US Government?’: How online community identities create new genres of political communication.” Starting in the Fall, Emily will begin a Ph.D. in Communication at Stanford University.
- Carolyn Zou graduated with honors from Northwestern in Communication Studies with their thesis, “Sociotechnical Risks of Simulating Humans with Language Model Agents.” Starting in the Fall, Carolyn will begin a Ph.D. in Computer Science at Stanford University.
- Carolyn Zou was awarded an NSF Graduate Research Fellowship (GRFP).
Publications:
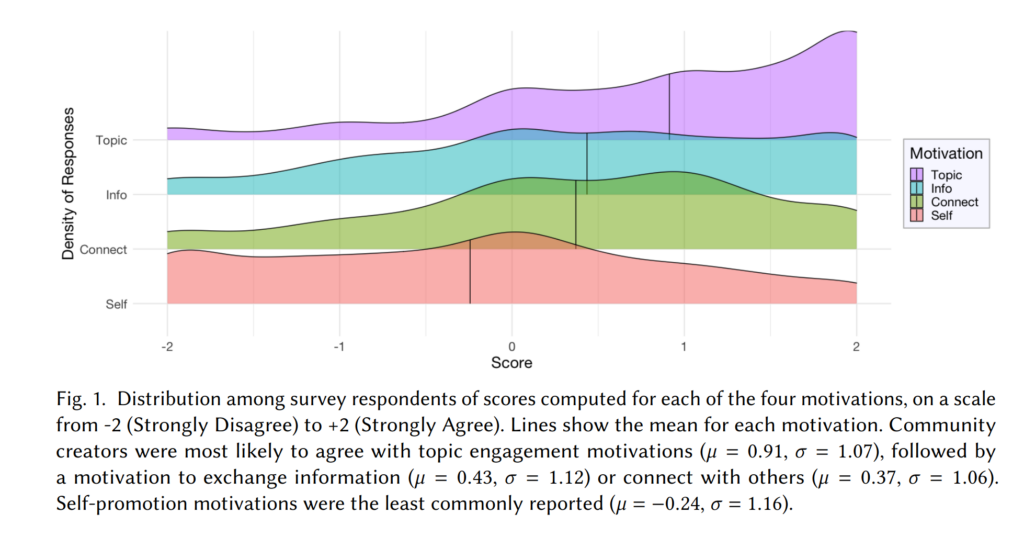
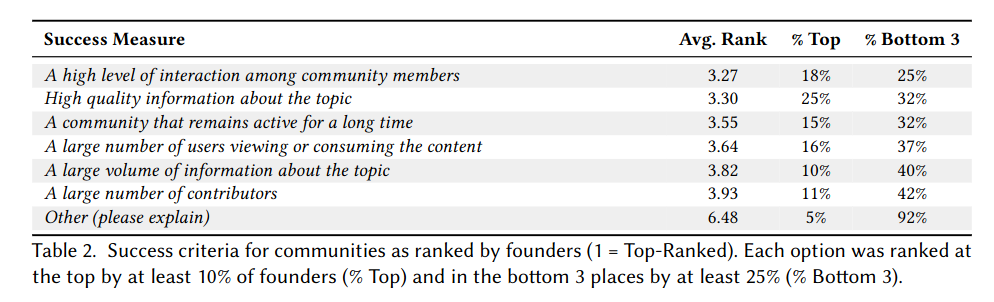
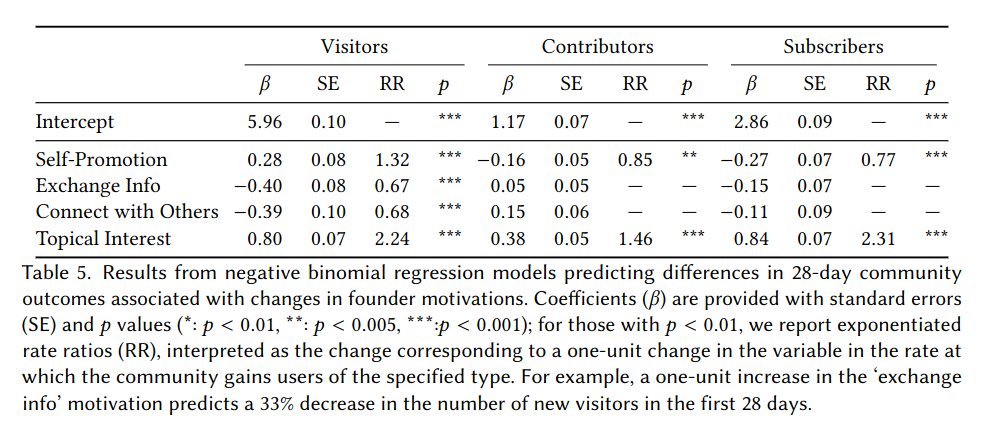
Members of the lab published more than 15 papers and articles. This is too many to list here, but you should check our publications page for more.
Talks and conference presentations:
Members of the group gave way too many presentations to list.
Select venues include: Seattle GNU/Linux Conference (SeaGL); Free and Open Source Software Yearly Conference (FOSSY); PyCon; Wikimania; the Annual Meeting of the International Communication Association (ICA); the Annual Meeting of the National Communication Association (NCA); the ACM Conferences CSCW and CHI; the Yale Internet & Society Project; the Berkman-Klein Center for Internet & Society at Harvard University; Stanford University HCI Speaker Series; University of Maryland, College Park; Rutgers University; Cornell Tech, Digital Life Institute; Learning Planet Institute, Paris; the University of Pennsylvania, Annenberg School for Communication; The Rockefeller Foundation’s Bellagio Center in Bellagio, Italy; and the Stanford Trust & Safety Research Conference, the IEEE International Conferences on Weblogs and Social Media (ICWSM) and Software Analysis, Evolution and Reengineering (SANER).
Teaching:
A selection of the courses taught or TA’ed by members of the group in the past year include:
- Introduction to Communication
- Introduction to Programming and Data Science
- Public speaking
- Online communities
- History & theories of information
- Social Network Analysis
- Communication technology & politics
Many of these are available via our workshops and classes page.
Events:
Members of the group planned, hosted, or otherwise played leadership roles in the following events:
- The CDSC Science of Community Dialogues Series
- The Northwestern Center for HCI+Design Thought-Leader Dialogue Series
- Free Open Source Software Yearly (FOSSY) Conference, Science of Community Track (2023 and 2024).
- The Decentralized Social Media Workshop, Princeton University
- Hongerige Wolf Festival (“Science” branch)
Other career and degree milestones:
- Madison Deyo joined the group as Program Coordinator!
- Molly de Blanc began a Ph.D. in Media, Technology, and Society at Northwestern.
- Haomin Lin and Matt Gaughan joined the CDSC at UW and Northwestern respectively.
- Carl Colglazier, Ryan Funkhouser, and Zarine Kharazian passed their general/preliminary/qualifying exams.
- Charlie Kiene completed an internship at Amazon.











{kind=link}