The Northwestern University branch of the Community Data Science Collective (CDSC) is hiring research assistants. CDSC is an interdisciplinary research group made of up of faculty and students at multiple institutions, including Northwestern University, Purdue University, and the University of Washington. We’re social and computer scientists studying online communities such as Wikipedia, Reddit, Scratch, and more.
A screenshot from a recent remote meeting of the CDSC…
Recent work by the group includes studies of participation inequalities in online communities and the gig economy, comparisons of different online community rules and norms, and evaluations of design changes deployed across thousands of sites. More examples and information can be found on our list of publications and our research blog (you’re probably reading our blog right now).
This posting is specifically to work on some projects through the Northwestern University part of the CDSC. Northwestern Research Assistants will contribute to data collection, analysis, documentation, and administration on one (or more) of the group’s ongoing projects. Some research projects you might help with include:
A study of rules across the five largest language editions of Wikipedia.
A systematic literature review on the gig economy.
Interviews with contributors to small, niche subreddit communities.
A large-scale analysis of the relationships between communities.
Successful applicants will have an interest in online communities, social science or social computing research, and the ability to balance collaborative and independent work. No specialized skills are required and we will adapt work assignments and training to the skills and interests of the person(s) hired. Relevant skills might include: coursework, research, and/or familiarity with digital media, online communities, human computer interaction, social science research methods such as interviewing, applied statistics, and/or data science. Relevant software experience might include: R, Python, Git, Zotero, or LaTeX. Again, no prior experience or specialized skills are required.
Expected minimum time commitment is 10 hours per week through the remainder of the Winter quarter (late March) with the possibility of working additional hours and/or continuing into the Spring quarter (April-June). All work will be performed remotely.
Interested applicants should submit a resume (or CV) along with a short cover letter explaining your interest in the position and any relevant experience or skills. Applicants should indicate whether you would prefer to pursue this through Federal work-study, for course credit (most likely available only to current students at one of the institutions where CDSC affiliates work), or as a paid position (not Federal work-study). For paid positions, compensation will be $15 per hour. Some funding may be restricted to current undergraduate students (at any institution), which may impact hiring decisions.
Questions and/or applications should be sent to Professor Aaron Shaw. Work-study eligible Northwestern University students should indicate this in their cover letter. Applications will be reviewed by Professor Shaw and current CDSC-NU team members on a rolling basis and finalists will be contacted for an interview.
The CDSC strives to be an inclusive and accessible research community. We particularly welcome applications from members of groups historically underrepresented in computing and/or data sciences. Some of these positions funded through a U.S. National Science Foundation Research Experience for Undergraduates (REU) supplement to awards numbers: IIS-1910202 and IIS-1617468.
Protocol Labs works to improve internet technologies through open source protocols, systems, and tools. The organization initially grew out of efforts to apply blockchain tools to support distributed file sharing infrastructure. Their research group, Protocol Labs Research, created the COVID-19 Open Innovation Grants program “to surface and support open-source projects working on tools to help humanity through present and future pandemics.”
In the case of the COVID-19 Digital Observatory, we plan to use the funds provided by the award to build out the resources we have already started to aggregate and release. In particular, we will build additional infrastructure to process and archive data from Reddit and other social media sources as well as search engine results pages (SERPs) for COVID-related queries.
In addition to folks in the collective, the proposal was successful through the efforts of Jason Baumgartner from Pushshift, who is co-leading the observatory work, as well as Marysia Galent, Research Administrator at Northwestern University, whose expert guidance helped make the grant application possible.
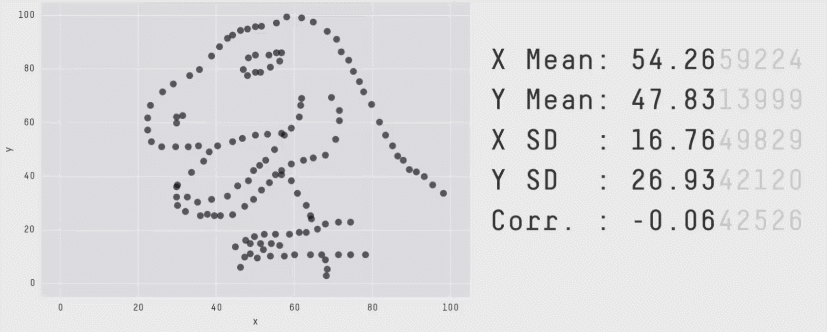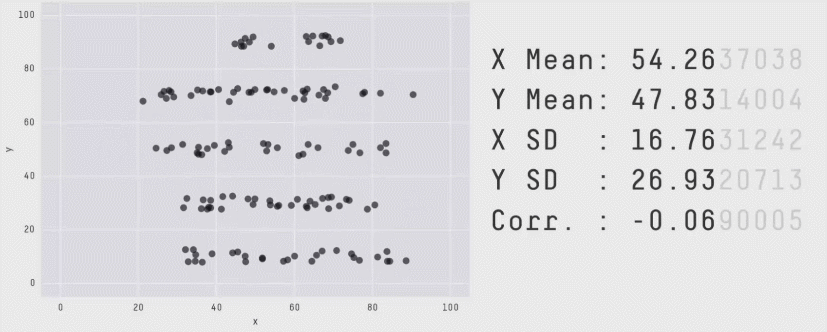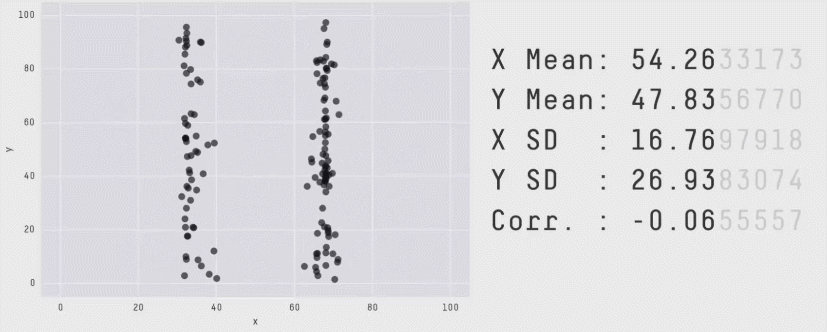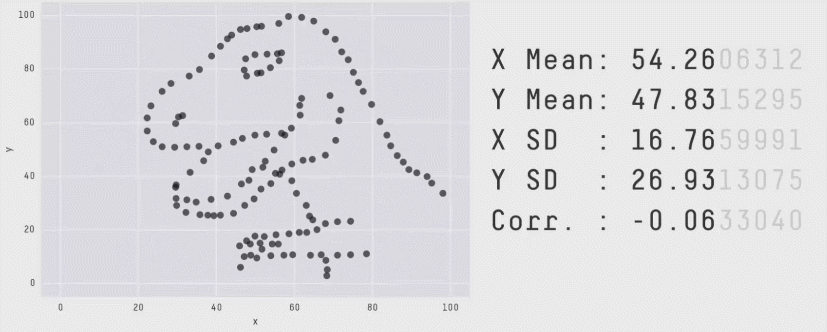
Why learning some statistics and some data visualization matters. (Gif from Matejka and Fitzmaurice, “Same stats, different graphs”, CHI 2017: https://dl.acm.org/citation.cfm?id=3025912)
I taught a graduate-level introduction to applied statistics and statistical computing this past Spring. The course design iterated on a class Mako developed in 2017. Very nearly all of the course materials are available open access through the Community Data Science Collective wiki and I wanted to make sure to share them more widely with this post. I’ve also been reflecting a bit on how the course went and thought I’d share those thoughts here in case anyone wants to adopt the course in the future.
First off, the course uses the OpenIntro Statistics (3rd edition) textbook as the core of the course readings and assignments. If you’re not familiar with OpenIntro and you want to learn or teach applied statistics from a general, social scientific perspective, you should check it out! All of the data, code, and LaTeX used to produce the textbook is licensed freely for reuse and the site also hosts video lectures, lecture notes, homework assignments, a discussion forum and more.
Alongside the OpenIntro materials, I worked together with Jeremy Foote (who was the TA for the course before he left to be new faculty at Purdue) to develop a bunch of tutorials in RMarkdown to help students complete the problem set assignments. We also posted worked solutions to the problem sets (also in RMarkdown). These replicated and expanded on screencasts Mako had recorded for his course.
The classroom sessions focused on discussion and problem solving. Basically, students came to each session knowing that I expected them to have completed the problem sets. I then did my best to answer any questions people had and assigned individuals (in some cases using a randomization script in R to pick names!) to summarize their solutions and approaches to specific problems that seemed important to cover.
It was my first time teaching a course like this and I had a few reflections after completing the quarter and reading through the feedback from students.
A major challenge for a course like this is pitching the material to an appropriate level given that students (in the MTS and TSB programs here at Northwestern at least) arrive with such varied knowledge of the subject matter. I think I did okay on this front in some ways and not in others. It was especially challenging given the semi-flipped classroom approach.
In some weeks, there was just too much material to cover in adequate depth. In some others, I was insufficiently organized and concise to cover everything. Whatever the case, I would cut back a bit next time. (I’ve noticed that this is a common issue for me the first time I teach any class, but I still struggle to correct it.)
Whatever challenges and failures I may have introduced in the design or instruction of the course, the students produced a bunch of highly original and engaging final projects. I’m optimistic that some of these projects will wind up as published work soon. Nothing like brilliant, motivated students to help the professor feel better about his own shortcomings!
Nearly all of the course materials are available on the CDSC wiki. The exceptions are a few of the readings and supplementary materials that I didn’t have the rights or desire to post on the public web. If you’re looking for any of that, feel free to send me an email and I can see if it’s appropriate to share.
Also, OpenIntro just came out with the fourth edition of their statistics textbook! I haven’t had a chance to check it out yet, but I’m eager to see what kinds of changes they introduced.
Many organizations have unprecedented access to data, experiments, and statistical inference. The diffusion of these resources has created pressure to develop the skills and practices necessary to use them. However, the distribution of these skills and practices has an organizational component, leading some teams and organizations to harness social scientific insights far more effectively than others.
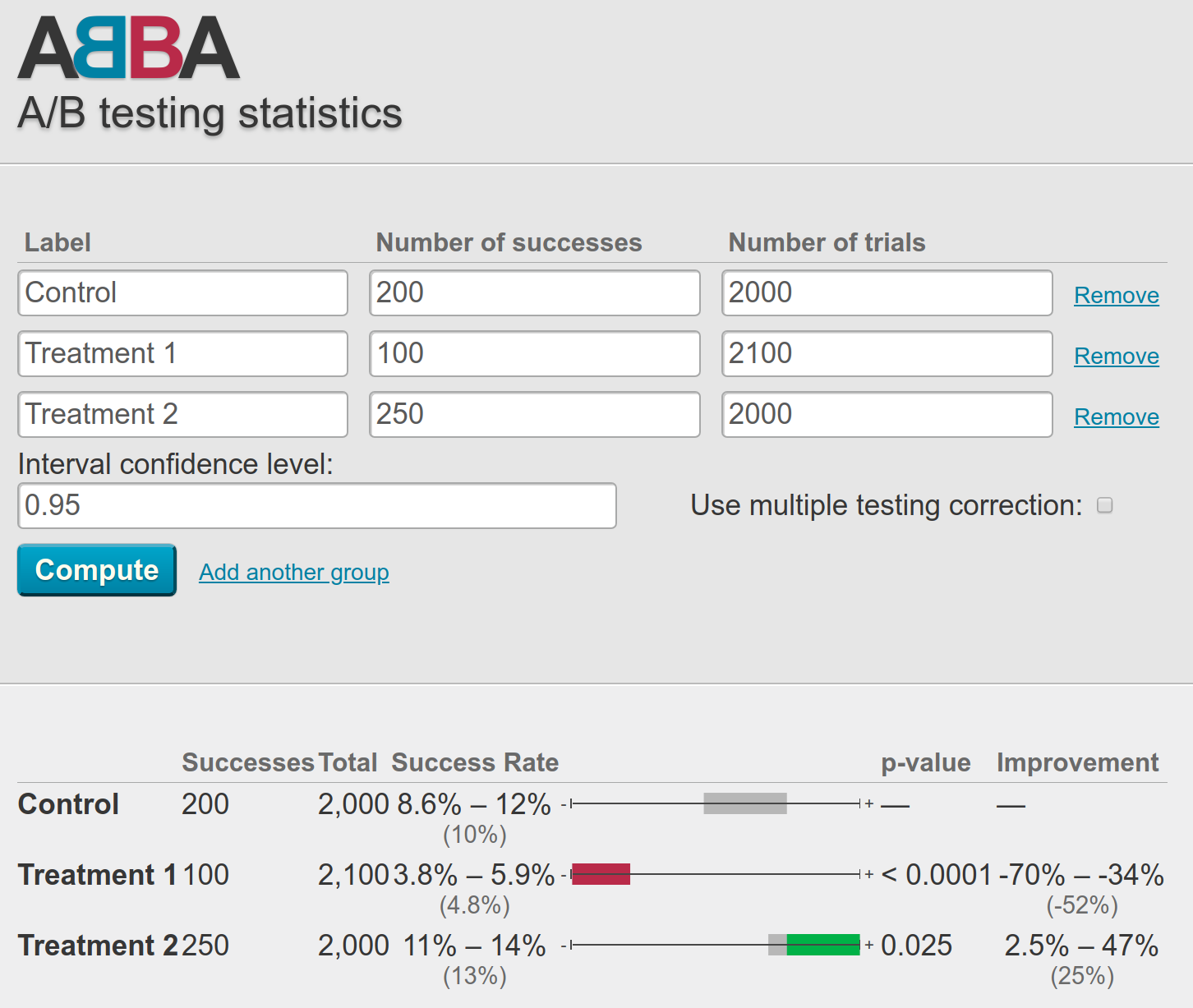
Handy web-based tools like ABBA can make a-b testing more accessible
We hear plenty about examples of “bad” statistics in the news. For example, Brian Wansink and the Cornell Food Lab have gotten a whole lot of attention for problems in their statistical analysis and interpretation. More than sheer ignorance or malfeasance (although there may be some evidence of that too), I think the reproducibility crisis illustrates how pervasive pressure to produce statistical evidence has combined with uneven professional standards can lead to dodgy research.
Our capacity to gather data and apply inferential statistics may have gotten ahead of our collective ability to manage these resources skillfully. In academia, this might lead to publications with spurious findings. In other kinds of environments, it might lead to decisions based on evidence of questionable quality. In both cases organizational resource constraints and communication challenges shape whether, where, and how well data science and statistics get done.
A slightly long story illustrates how this can play out in a non-academic environment, specifically a fairly small technology company. I share the story as a cautionary tale that can hopefully provoke some useful reflection about how we (people who care about evidence-based decision making, data science, statistics, and applied social science) can improve our work. I have de-identified the organization and the individuals involved because this is really not about them per se. The challenges they face are common. I think the story can tell us something interesting about those challenges.
Within the organization, several teams conduct experiments, user tests, and other sorts of data-intensive, social scientific research. One of these teams had reached out because they had some questions about methods of analysis. Within the organization, this particular team had gotten positive feedback for their adoption of a data-driven pipeline of A/B testing, but there were concerns about whether the testing was being done well. I went to visit them planning to do a little bit of informal statistical consulting and to learn more about that part of the organization.
A few team members walked me through a typical field experiment with multiple (about 10) treatment conditions. Everything runs on a small stack of custom scripts that pulled summary data from the platform’s databases. The team uses spreadsheets to record the number of individuals assigned to each condition along with the number of “successful” trials (e.g., cases where an end-user has the desired response to a given design change).
The team then enters the raw summary information into an open source web-based tool called ABBA that runs some calculations and reports a “success rate” (a smoothed percentage) for each trial, a raw and percentage-based confidence interval for the success rate, and a p-value (based on a binomial cumulative distribution function or a normal approximation for large samples). ABBA also presents a handy little visualization plotting the interval estimated for each experimental condition along a bar colored either gray (not different from control), red (lower success rate than control), or green (higher success rate than control) depending on the results of the corresponding hypothesis test. I’ve included a screenshot of what this looks like at the top of the post and you can try it yourself.
Those of you with a statistical background following me into the weeds here might be nodding and thinking “okay, sounds maybe not ideal, but reasonable enough.” While the system puts too much faith in p-values, it follows a pretty standard approach. It’s also a great example of the kind of statistics-as-a-service approach to A/B testing that many organizations have adopted in response to various pressures to be more data driven.
That’s when things started to get weird. As we spoke more, it turned out that the ways members of the team conduct the tests, enter the data, and interpret the results raise major red flags.
For example, they regularly update the number of experimental conditions on-the-fly, dropping old conditions and adding new conditions when others already had thousands of observations (ABBA makes this super easy!).
When experimental conditions are dropped or added, the team routinely re-computes statistical tests and p-values with/without the new/old observations included. Mostly, conditions that do not seem to produce different outcomes from the control were silently removed from the analysis.
For some of the analysis itself, the team uses parametric tests that assume normal distributions on heavily skewed data.
Then, when it comes time to interpret the results, the analysts use the relative magnitude of p-values as an estimate of the magnitude of conditional effect sizes.
At this point, those of you with relevant training in applied statistics, experimental research methods, data science, etc. might be scratching your heads or experiencing full-on panic.
Separately, each of these steps are inferential howlers capable of invalidating results. Together, they render whatever results were coming out of this process untrustworthy in the extreme.
For the rest of the meeting, I did my best to identify a series of steps the team could take to avoid the problems above. But I still walked away disconcerted. This was a technically sophisticated organization with plenty of resources. The team was using a pretty well-designed tool for analyzing experimental data. They had gotten critical feedback on the work they were doing. How did a situation like this happen?
The individuals on the team were doing their best. Nobody is born with deep knowledge of applied statistics. Confronted with a challenging mandate from their supervisors, these people were all doing their absolute best to apply some tools they didn’t fully understand to solve a practical problem. They had generally been told that their work was good, knew they had some issues to fix, and reached out to someone with more knowledge (in this case me) for help.
What about the tools? Can we at least blame the tools? As I mentioned earlier, a bunch of companies are in the business of providing “statistics-as-a-service” or A/B testing platforms, but I’m not convinced that these are the root of the problem either. Sure, ABBA makes some mistakes a little too easy, but the tool was also built and shared by skilled data scientists who painstakingly documented everything before distributing it on GitHub. Their documentation is why I was able to sort out exactly what was happening in the first place and help the team members understand some of the issues involved. Indeed, nothing seems obviously or fundamentally wrong with the implementation of the underlying software or the statistical tests. Instead, the misuse of the system happened despite the software designers’ best efforts.
Here we get into one problem area: the incentives to produce specific kinds of outcomes. The team using the tool needed to run experiments and interpret them as decisive “wins” or “losses.” The reality was much less clear and, in this way, the p-values obscured some of that ambiguity. Imposing a dichotomous logic on experimental evidence is often impossible and will, even under the best conditions, lead to systematic abuses of statistical reasoning.
What about the organizational leadership then? Shouldn’t they be responsible for making sure that the company does high quality data science? On the one hand yes, and on the other hand, this is hard too and understandable problems arise. Executives and managers often lack the requisite statistical expertise to evaluate operations like this in a rigorous way. They have heard, through professional networks, industry publications, media, etc., that more data and more A/B tests are Good Things for their organization. At a certain point, they cannot do the auditing of experimental procedures and inference themselves.
Shouldn’t the managers just make sure someone else can audit the statistics then? This is probably where the most important breakdowns occurred. Turns out that other staff possess all the skills to diagnose and repair the issues I identified (and more). One of these people had even been assigned to work with the team in question for a while! However, that assignment had ended during a restructuring and statistical expertise had never returned to the team. In the meantime, managers continued to demand results without fully appreciating that the existing approach had deep problems.
So given this particular mix of data and organizational sciences gone awry, what lessons can we learn?
The future of data-intensive social science remains, as William Gibson might say, unevenly distributed. As the infrastructure for data collection and analysis has become more widely accessible, the choke-point in many organizations has become the dissemination of deeper knowledge of the techniques necessary to produce valid, reliable inference. These inequalities emerge both within and between organizations. Some companies and some teams have more expertise than others. Some have more effective systems for feedback and improvement than others.
In this sense, organizational (not just technical or statistical) obstacles stand in the way of more effective, accountable, and transparent uses of evidence to make decisions. Web-scale organizations can run 100,000 randomized trials and analyze the results very quickly. The results can look real and have p-values attached and the executives can believe that they have got the whole data science thing nailed down. However, the analysis might not mean much unless it is implemented skillfully.
The inundation of behavioral trace data does not guarantee that we will be similarly inundated by reliable findings, valid inference, or skilled implementation. High quality research design and interpretation may not scale so easily as the data or the analysis tools.
All of this has distributive implications. Organizations with access to the best social scientific knowledge as well as the organizational capacity to deploy and harness that knowledge will be the ones most likely to reap benefits from it. Others, such as many public administrations in the U.S. (especially those that deliver social services), smaller firms, non-profits, and community organizations will likely get inferior inference (to the extent they get any at all).
It takes time and effort to build organizational resources and cultures capable of supporting widespread, high quality, data-driven inference. Some recent work in HCI and related fields speaks to these issues. For example, some folks at CU Boulder have a 2017 CHI paper about how mission-driven organizations can struggle to do data-driven work. In a more interventionist vein, Catherine D’Ignazio and Rahul Barghava have launched the Data Culture Project in an effort to help smaller non-profits and community organizations use data more effectively.
Whatever the organizational context, high quality social scientific and statistical work requires more than just a clear understanding of p-values and massive A/B testing infrastructure. Statistical expertise also needs to be embedded and managed effectively within organizations and teams in order to produce reliable inference.
This is a cross-post from the CASBS Medium channel. Thanks to members of the CDSC, Margaret Levi, and some anonymous friends for feedback on earlier versions of the text.
Over at Crooked Timber, Henry Farrell and others recently held a book seminar to discuss Cory Doctorow’s Walkaway. The symposium led to an extended discussion between Henry, Cory, Henry again, and Yochai Benkler about Benkler’s early work on commons-based peer production, spaces of resistance in the contemporary information economy, and the state of peer production a little over fifteen years since Benkler introduced the term. This (far too long) post summarizes some of their key points as a way of starting to collect my own thoughts on these questions.
I haven’t read Walkaway yet (downloaded my DRM-free digital copy, but the fiction slot in my brain is currently occupied by Philip Pullman’s totally engrossing La Belle Sauvage), but I can’t wait to get to it. Cory says the book started as an exercise in projecting how the sociotechnical transformations Benkler laid out in Coase’s Penguin might facilitate the spread of utopian energies at the periphery of radically unequal societies not so different from our own:
It’s been 15 years since Benkler made the connection between “commons-based peer-production” and Coase…
Down and Out in the Magic Kingdom projected Slashdot karma and Napster superdistribution across a whole society as a way of illuminating the strengths and weaknesses of both. Walkaway tries to do the same with commons-based peer-production: what would a skyscraper look like if it was a Wikipedia-style project? How about a space program?
As a Coasean tale, Walkaway is one the battleground between the technological, Promethean left—which has promised to lift peasants up to the material comfort of lords—and the de-growth green left, which promises to bring lords down to the level of the peasants in the name of saving the planet.
and later:
This is (in my view) a Utopian vision. It supposes that the Bohemian projects that even the most buttoned-down societies allow at their margins can breed real discontent and nurture and sustain it into something that genuinely challenges its host… They provided real-world lessons on which tactics worked and where the weaknesses were. They were battles, not the war. The only thing more extraordinary than a social justice prevailing at all is for it to prevail on its first outing, or second, or third.
In his contribution to the seminar, Henry points to Cory’s assumption that “exit” (in Hircshman’s sense) remains viable in a society pervaded by vast power inequalities, surveillance capabilities, and an (increasingly weaponized) disregard for privacy:
Again, Doctorow’s book isn’t an exercise in predictive science – he’s not saying that things will be so. But he is saying, I think, that things could and should be so, or sort-of so. Walkaway is quite unashamedly a didactic book in the way that earlier books such as Homeland were didactic – he has a very clear message to get across. In conversations with Steve Berlin Johnson years ago, I came up with the term BoingBoing Socialism to refer to a specific set of ideas associated with Doctorow and the people around him – that free exchange of ideas unimpeded by intellectual property law and the like, together with transformative technologies of manufacture, could open up a path towards a radically egalitarian future. Unless I’m seriously mistaken (in which case I’m sure that Doctorow will tell me), Walkaway wants to do two things – to argue for why such a future might be attractive, and to suggest that something like this future could be feasible.
For Henry, the implications boil down to questions of power and the role powerful entities play in shaping the lives of even the most peripheral, socially excluded groups within a society. He also (later on) expresses skepticism at the political prospects of the revolutionary vision of “BoingBoing Socialism” that adopts a rhetoric of contingency and self-marginalization as its platform for change.
Ronald Coase. 2003, U of Chicago Law School.
In a followup post, Henry elaborates a claim that Benkler engaged in a sort of naive Coasean disregard for power relations when he laid out the definitional statements on peer production. Henry says Benkler emphasized transaction cost and efficiency-centric explanations for the potential of peer production to substitute for firm or market-based modes of knowledge production and exchange:
Power relationships often explain who gets what, and which forms of organization are taken up, and which fall by the wayside. In general, forms of production that are (a) more efficient, but (b) inconvenient or unprofitable for powerful actors, are probably not going to be taken up, since those powerful actors will block them. Yet if one starts from an efficiency perspective, it is very hard to build power relations in, since one believes that change in practices and institutions is not driven by power relations but by efficiency.
and later:
What this means, if you take it seriously, is that Coaseian coordination is a special case of bargaining. Broadly speaking, Coaseian processes will lead to efficient outcomes only under very specific circumstances – when the actors have symmetrical breakdown values, as in the first game, so that neither of them is able to prevail over the other. More simply put, the Coase transaction cost account of how efficient institutions emerge will only work when all actors are more or less equally powerful. Under these conditions, it is perfectly alright to assume as Coase (and Benkler by extension) do, that efficiency considerations rather than power relations will drive change. In contrast, where there are significant differences of power, actors will converge on the institutions that reflect the preferences of powerful actors, even if those institutions are not the most efficient possible.
and finally:
In short – we need to distinguish between the rhetorical claims that technological change will bring openness along with it, and the (far more sustainable) claim that technology will probably only have openness enhancing benefits in a world where we are already dealing with the underlying power relations.
Benkler responds that Farrell is right to question his (Benkler’s) approach to power, but wrong in that the failure of his (Benkler’s) arguments in Coase’s Penguin and The Wealth of Networks is not driven by naive Coaseanism, but a different dimension of power entirely:
My primary mistake in my work fifteen years ago, and even ten, was not ignoring the role of power in shaping market patterns, but in understating the extent to which the new “market actors who will build the tools that make this population better able…” will themselves become the new incumbent market actors who will shape the environment to increase and lock-in their power. That is certainly a mistake in reading the landscape of power grabs, and I have tried to correct over the intervening years, most recently by offering a map of what has developed in the past decade…
In other words, today’s Benkler argues that yesterday’s Benkler underestimated the adaptive capacities of various incumbent powers as well as the way that a continuously shifting technical, regulatory, and political environment would alter the landscape along the way.
All of this speaks to an ongoing conversation Mako and I have been having about the past, present, and future of peer production. A pessimistic account might run like this: peer production thrived from ~1995-2008 in part because incumbent firms and private actors had not figured out how to capitalize on the possibilities for community-based provision of resources unlocked by the diffusion of digitally networked communications infrastructure. Now that increasing numbers of firms have done so, there is no going back. Large firms as well as their venture-funded spawn will continue to eat peer production communities’ lunch, undermining their viability as well as their autonomy. Peer production as we know it will eventually disappear, becoming a curious relic of a more naive era when the electronic frontier remained an unsettled, experimental space.
Another possibility, arguably more optimistic, can be seen in Benkler and Doctorow’s contributions to this exchange. Rather than consigning peer production to the dustbin of history, they both suggest that room for maneuver (or “degrees of freedom” in Benkler’s terms) will remain at the margins of the networked information economy and that communities of “walkaways” may persist in experimenting with “real utopian” autonomous alternatives to the more extractive, winner-take-all models of “supercapitalist” knowledge production and exchange. Doctorow’s fiction seems to explore the (hopeful) potential of these walkaway communities to generate radical, systematic transformation. Benkler, in his more recent writings, holds out some hope, but of a highly contingent, tenuous, and circumscribed sort.
I recently read Deborah M. Gordon’s Ant Encounters and thought I’d summarize some thoughts about it. Gordon is a Professor of Biology at Stanford. The book pulls together several decades of research (hers and others’) on the behavior and ecology of ants. In it, Gordon makes nuanced claims about the importance of communication and interaction for distributed collective behavior in clear, non-technical language. Many of the findings should inspire people (like me) interested in understanding the organization of collective behavior in humans.
Gordon argues that ant behavior and colony dynamics encompass a complex system driven by patterns of interactions, information exchange, and environmental influences. She contrasts this with more deterministic accounts of ants prevalent in earlier scientific literature and popular culture. Gordon emphasizes how ants operate by behavioral heuristics and information processing rather than a fixed set of rules or genetically encoded traits.
Argentine ant (cc-by-sa, Penarc, Wikimedia Commons)
Consider the division of labor within an ant colony. The prevailing (wrong) view depicts ants born into a pre-specified, genetically determined “caste” which has a clearly-defined task within a hierarchically structured colony. Following this story, the Queen of the colony births out larva who grow into task-specialized sterile adults. Individuals within each caste supposedly possess physical traits that support their specialization as foragers, trash removers, larva-tenders, patrollers, or whatever. Each individual supposedly pursues their specialized task tirelessly until death.
It turns out that this account reflects a mixture of reasonable misinterpretation and fantastical thinking. First off, Gordon notes, ants change tasks within their life course. Today’s larva-tender may be tomorrow’s forager. These changes do not entail biological changes within each ant (although there seems to be evidence that ants do tend to adopt specific tasks at specific stages of their lives within a colony), but instead reflect responses to interactions with other members of the colony and external forces shaping those interactions. In a younger, less populous colony, ants may change tasks in response to immediate needs and threats that arise suddenly. In larger, more mature colonies where things are less likely to change suddenly, many ants may have more stable activities. Some ants in large colonies even literally sit around doing nothing because the information they receive from their nest-mates indicates that the colonies needs are being met. None of this is fixed by genetic encoding or hierarchical commands.
Second, Gordon shows how ants respond probabilistically to local stimuli. Individual ants, it turns out, act a lot like heuristic distributed sensors or nodes in a communications network—each with some likelihood of changing its behavior depending on the feedback it receives from its environment. They are not automatons with deterministic programming to pursue a single-minded course of action.
Third, Gordon shows how colonies as a whole change in reaction to their environments and collective interactions. If one colony finds itself in proximity to another, the individuals within it may alter how much collective effort is dedicated to specific tasks depending on the species, size, and temperament of its neighbors. Individual ants respond to the number of nest-mates and neighbors they encounter. If their last ten encounters were with foragers from their home nest returning with food to feed the larval brood, they may continue to go about their business uninterrupted. As the portion of recent interactions includes outsiders or nest-mates responding frantically to an unwelcome intruder of some sort, the probability rises that the next ant will change its behavior in response (maybe to start running around in a panic or bite an intruder).
Harvester ants collecting seeds (cc-by-sa Donkey Shot, Wikimedia Commons)
Through many examples, Gordon conveys how patterns of collective ant behavior emerge and adapt to local circumstances without a centralized coordination mechanism or hierarchy of control. She describes this almost entirely without recourse to the jargon of complexity theory or complex systems research.
A concrete, measured, and example-driven account of how actually existing complex systems work is maybe the most impressive achievement of the book. Many texts discuss complexity in human and ecological systems, but none that I have read do so with the clarity of Ant Encounters. While I should read more books on these topics, more people in my little corner of the research world should read Gordon’s work too.
Ant Encounters ultimately left me excited to pursue some of the potential extensions and connections between Gordon’s work and research on human social systems and organizations. For example, I’d love to follow up on her comment that higher interaction frequency is associated with colony growth or survival (I currently forget which). Would such a finding hold up in the context of human organizations? If so, what would it look like and mean in the context of building effective peer production systems? Gordon has also written elsewhere about some of the potential connections between ant behavior, human organization, communication protocols. Recent findings from Gordon and her collaborators show how ants follow a set of behavior protocols very similar to those encoded in the TCP specification (apparently, she likes to refer to this idea as “the Anternet“). I’m eager to read more of the scientific publications from Gordon and her collaborators to understand these ideas more deeply and to see how well they travel when applied to a species I know a little bit more about.
When major league baseball held its opening day on April 15 in 1947, a 28 year-old infielder made his highly-anticipated debut at first base for the Brooklyn Dodgers. He would go on to record an extraordinary season and career worthy of induction into the Baseball Hall of Fame, winning Rookie of the Year honors in 1947, a batting title and Most Valuable Player award in 1949, and a World Series title in 1955. He also produced two seasons that rank among the top 100 ever (by the metric of Wins-Above-Replacement among position players).
Jackie Robinson (1954 public domain photo by Bob Sandberg for Look Magazine).
Looking at the box score, Jackie Robinson didn’t make an overwhelming impact on the outcome of his first game, but his presence on the field challenged the racist status quo of professional baseball and American society. What’s more, the intense public-ness of the challenge made Robinson’s presence a symbol and a spectacle: of the roughly 26,500 spectators in attendance at Ebbets field, an estimated 14,000 were black. I cannot imagine what it was like to be at that game — one of those rare places and moments where it becomes possible to see an historic social transformation as it unfolds. Just the thought gives me goosebumps.
Every major league player, coach, and umpire will don Robinson’s iconic number 42 in recognition today. Watching games and highlights from Jackie Robinson Days past, I’ve been troubled by how easily such observances drift into a hagiographic reverie that sometimes even take on a self-congratulatory tone. Stories of Robinson’s incredible athletic and personal accomplishments sometimes efface his struggle against horrible, violent, and aggressive responses. Worse yet, the stories usually play down the persistence of racism and its effects today. Baseball celebrates Jackie Robinson Day out of a strange combination of guilt and pride; knowledge and ignorance; resistance and complicity.
As I indicated earlier, Robinson’s performance and impact qualified him for the Hall of Fame along multiple dimensions. However, another way to think about his unique contribution to baseball is to consider how such virulent racism likely affected his play and how unbelievably, mind-blowingly great a player he might have been under less racist conditions.
There’s no obviously valid way to construct a counterfactual Jackie Robinson, but research on the phenomenon of stereotype threat suggests a very simple, naive statistical adjustment strategy. To paraphrase a bunch of scholarly studies and the (pretty extensive) Wikipedia article, stereotype threat reduces the performance of individuals who belong to negatively stereotyped groups, largely by inducing feelings of anxiety.
Stereotype threat affects various kinds of behaviors including athletic achievement. A 1999 study by Jeff Stone and colleagues (pdf) estimates the effects of some typical forms of stereotype threat on a sample of black men’s athletic performance, reporting that race-based priming resulted in a 23.5% worse outcome on a miniature golf (!) task than a control condition with no priming.
Consider that the priming in this Stone et al. study was done in a fairly polite, impersonal, non-hateful, non-threatening way in relation to a mini-golf task with absolutely nothing at stake. Consider just how personal, vitriolic, and violent the responses to Jackie Robinson were — many of them coming directly from opposing players and “fans” who went to great pains to heckle him in the middle of at-bats, physically target him with violent slides and more on the field, or issue death threats to him and his family. Consider how much Robinson had at stake and just how public his successes and his failures would have been.
Some people may like to imagine (and filmmakers may like to depict) that the hatred helped to motivate and focus Robinson, spurring him to even greater performance. Similarly, part of the mystique of the greatest athletes is that they seem to empty their heads of all the noise and distractions that would debilitate the rest of us at precisely those moments when the stakes and pressures are highest. It’s easy to say that Robinson didn’t respond to the pressure in the same way as most humans would, but the research on stereotype threat suggests that it probably affected him on the field anyway. Just being reminded — even in very subtle, socially-coded ways — that you belong to a socially excluded group reduced athletic performance by nearly a quarter. The sort of cognitive burden that comes along with being singled out and targeted by the kind of racial hatred that Robinson experienced must be orders of magnitude greater. What sort of impact would this burden have had on Robinson’s play?
Now, go look at the stat lines again from those two spectacular seasons (1949, WAR 9.6, and 1951, WAR 9.7) that Robinson had and imagine them without the stress, the pain, the distraction of all that hate. Be a little bit generous and inflate the WAR statistics by the same 23.5% that Stone et al.’s subjects performance dropped in a laboratory study in ridiculously low-key conditions. Under these assumptions, Robinson’s two greatest seasons might have yielded WAR of 11.9 and 12.0 respectively — easily placing them both among the top 10 seasons by a position player ever.
This quarter, I am teaching a graduate seminar called “The Practice of Scholarship” that is required for second-year students in the Northwestern MTS and TSB programs. Following Mako’s lead, I am using the Community Data Science Collective wiki to host the (editable) syllabus. In other words, I am eating to my heart’s content.
We had our first class session yesterday and it went really well. The goal for the quarter is for every student to prepare a manuscript for submission to a peer reviewed venue. I told the students that the course will serve as a hybrid writing boot camp and extended group therapy session. There will be much workshopping and iteration and sharing of feelings. There will also be polite, friendly, and unyielding pressure to produce scholarly work of exceptional quality.
In keeping with the wikified ethos, much of the course schedule remains tbd at this point, so please drop me a line with comments, suggestions, or pointers to great readings that brilliant, interdisciplinary, empirical social scientists and HCI researchers like my students would appreciate.
Hello world! It’s been a while since I’ve done any blogging, but I’ve been wanting to return for some time now, so here we are. My old blog was a hodge podge that hovered at the edges of my research. Current events featured prominently, especially those having to do with governance in online communities, knowledge production and access, and research ideas. I have a few different goals for this blog.
A new day dawns for blogging on the shores of Lake Michigan…
First, since it’s part of the Community Data Science Collective site, I plan to talk about our research, affiliates, community events, and related topics. Second, I want to use the blog as a space to sketch out research ideas more regularly. When I blogged previously, I was a graduate student. I had more unstructured time in which to brainstorm and reflect. The transition to faculty and the subsequent accumulation of responsibilities, projects, students, and commitments has left me seeking time to think broadly and with less structure. I need a semi-structured space and time to do so. As a result, I return to blogging.
This relates to a third goal: a minimum of one post per week. In the old days, Mako coordinated the Cambridge instance of Iron Blogger, a group blogging accountability project in which all the participants agreed to write one post per week or pay $5 into a common pot (that we then used to throw a party whenever it got big enough). The incentives sound misaligned, but the semi-public commitment, a deadline, and the nominal material cost of failure got a weekly post out of me roughly 90% of the time.
There is no iron blogger group in Chicago (yet?), but I’m going to recreate the structure with a little public accountability infrastructure with some friends. So far, Rachel and I have committed to posting weekly and tracking our posts. If others want to join, we can add further infrastructure as needed. No fines for now, but if I fail to post frequently between now and the end of the academic year, I’ll revisit.
Finally, since I do a lot more mentoring and teaching now than I used to, I imagine that these activities will occupy a fair amount of my attention as well. I feel more comfortable publishing material about my teaching now than when I first started at Northwestern. I am also realizing that my approach to teaching would lend itself really well to blogging as I am continually tinkering with the structure of my assignments, readings, evaluations, and lessons. A space to reflect on my experiences more actively and to solicit feedback from students and others seems like a helpful thing.
That’s it for this opening post. Thanks for reading.