Many organizations have unprecedented access to data, experiments, and statistical inference. The diffusion of these resources has created pressure to develop the skills and practices necessary to use them. However, the distribution of these skills and practices has an organizational component, leading some teams and organizations to harness social scientific insights far more effectively than others.
We hear plenty about examples of “bad” statistics in the news. For example, Brian Wansink and the Cornell Food Lab have gotten a whole lot of attention for problems in their statistical analysis and interpretation. More than sheer ignorance or malfeasance (although there may be some evidence of that too), I think the reproducibility crisis illustrates how pervasive pressure to produce statistical evidence has combined with uneven professional standards can lead to dodgy research.
Our capacity to gather data and apply inferential statistics may have gotten ahead of our collective ability to manage these resources skillfully. In academia, this might lead to publications with spurious findings. In other kinds of environments, it might lead to decisions based on evidence of questionable quality. In both cases organizational resource constraints and communication challenges shape whether, where, and how well data science and statistics get done.
A slightly long story illustrates how this can play out in a non-academic environment, specifically a fairly small technology company. I share the story as a cautionary tale that can hopefully provoke some useful reflection about how we (people who care about evidence-based decision making, data science, statistics, and applied social science) can improve our work. I have de-identified the organization and the individuals involved because this is really not about them per se. The challenges they face are common. I think the story can tell us something interesting about those challenges.
Within the organization, several teams conduct experiments, user tests, and other sorts of data-intensive, social scientific research. One of these teams had reached out because they had some questions about methods of analysis. Within the organization, this particular team had gotten positive feedback for their adoption of a data-driven pipeline of A/B testing, but there were concerns about whether the testing was being done well. I went to visit them planning to do a little bit of informal statistical consulting and to learn more about that part of the organization.
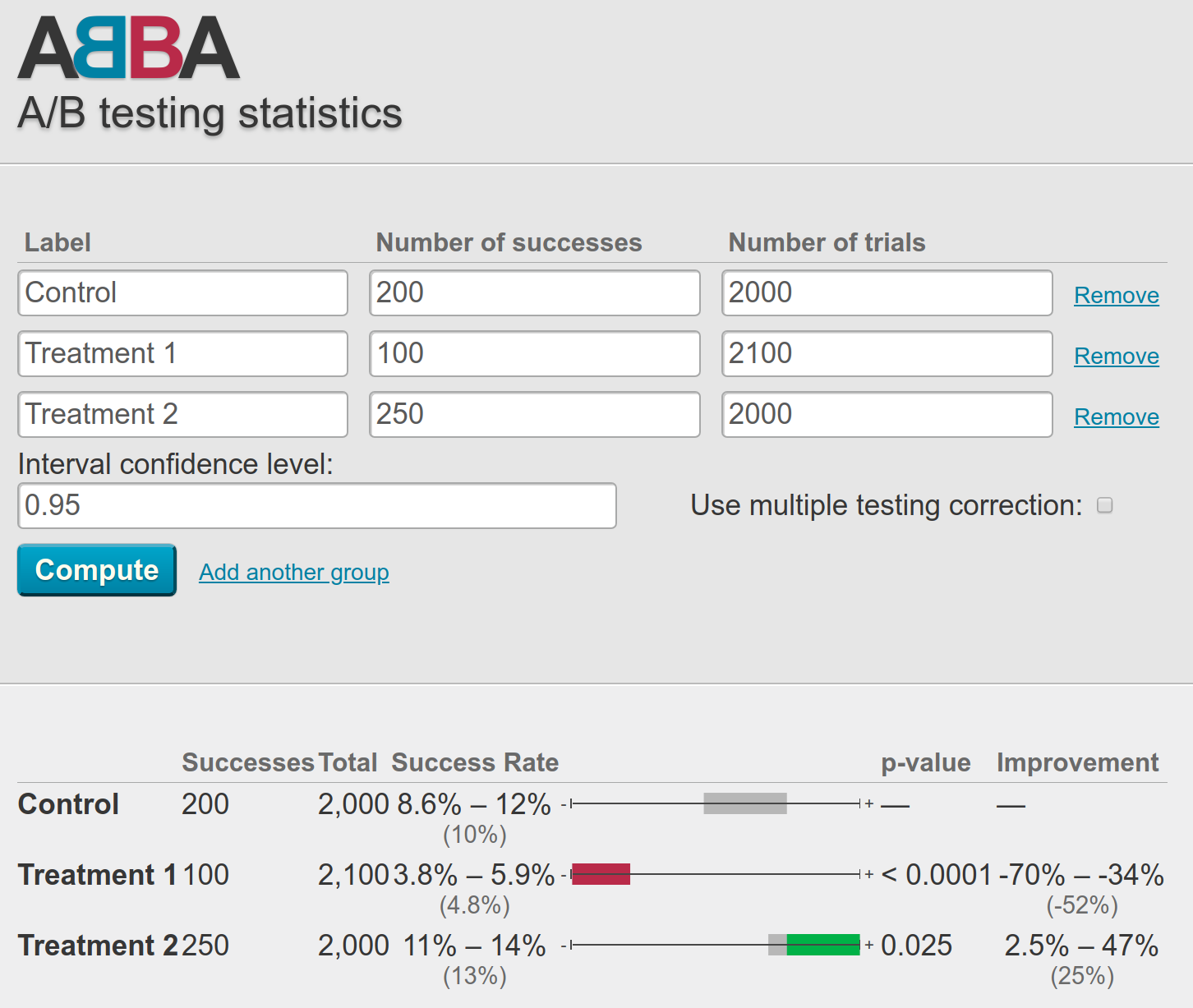
A few team members walked me through a typical field experiment with multiple (about 10) treatment conditions. Everything runs on a small stack of custom scripts that pulled summary data from the platform’s databases. The team uses spreadsheets to record the number of individuals assigned to each condition along with the number of “successful” trials (e.g., cases where an end-user has the desired response to a given design change).
The team then enters the raw summary information into an open source web-based tool called ABBA that runs some calculations and reports a “success rate” (a smoothed percentage) for each trial, a raw and percentage-based confidence interval for the success rate, and a p-value (based on a binomial cumulative distribution function or a normal approximation for large samples). ABBA also presents a handy little visualization plotting the interval estimated for each experimental condition along a bar colored either gray (not different from control), red (lower success rate than control), or green (higher success rate than control) depending on the results of the corresponding hypothesis test. I’ve included a screenshot of what this looks like at the top of the post and you can try it yourself.
Those of you with a statistical background following me into the weeds here might be nodding and thinking “okay, sounds maybe not ideal, but reasonable enough.” While the system puts too much faith in p-values, it follows a pretty standard approach. It’s also a great example of the kind of statistics-as-a-service approach to A/B testing that many organizations have adopted in response to various pressures to be more data driven.
That’s when things started to get weird. As we spoke more, it turned out that the ways members of the team conduct the tests, enter the data, and interpret the results raise major red flags.
For example, they regularly update the number of experimental conditions on-the-fly, dropping old conditions and adding new conditions when others already had thousands of observations (ABBA makes this super easy!).
When experimental conditions are dropped or added, the team routinely re-computes statistical tests and p-values with/without the new/old observations included. Mostly, conditions that do not seem to produce different outcomes from the control were silently removed from the analysis.
For some of the analysis itself, the team uses parametric tests that assume normal distributions on heavily skewed data.
Then, when it comes time to interpret the results, the analysts use the relative magnitude of p-values as an estimate of the magnitude of conditional effect sizes.
At this point, those of you with relevant training in applied statistics, experimental research methods, data science, etc. might be scratching your heads or experiencing full-on panic.
Separately, each of these steps are inferential howlers capable of invalidating results. Together, they render whatever results were coming out of this process untrustworthy in the extreme.
For the rest of the meeting, I did my best to identify a series of steps the team could take to avoid the problems above. But I still walked away disconcerted. This was a technically sophisticated organization with plenty of resources. The team was using a pretty well-designed tool for analyzing experimental data. They had gotten critical feedback on the work they were doing. How did a situation like this happen?
The individuals on the team were doing their best. Nobody is born with deep knowledge of applied statistics. Confronted with a challenging mandate from their supervisors, these people were all doing their absolute best to apply some tools they didn’t fully understand to solve a practical problem. They had generally been told that their work was good, knew they had some issues to fix, and reached out to someone with more knowledge (in this case me) for help.
What about the tools? Can we at least blame the tools? As I mentioned earlier, a bunch of companies are in the business of providing “statistics-as-a-service” or A/B testing platforms, but I’m not convinced that these are the root of the problem either. Sure, ABBA makes some mistakes a little too easy, but the tool was also built and shared by skilled data scientists who painstakingly documented everything before distributing it on GitHub. Their documentation is why I was able to sort out exactly what was happening in the first place and help the team members understand some of the issues involved. Indeed, nothing seems obviously or fundamentally wrong with the implementation of the underlying software or the statistical tests. Instead, the misuse of the system happened despite the software designers’ best efforts.
Here we get into one problem area: the incentives to produce specific kinds of outcomes. The team using the tool needed to run experiments and interpret them as decisive “wins” or “losses.” The reality was much less clear and, in this way, the p-values obscured some of that ambiguity. Imposing a dichotomous logic on experimental evidence is often impossible and will, even under the best conditions, lead to systematic abuses of statistical reasoning.
What about the organizational leadership then? Shouldn’t they be responsible for making sure that the company does high quality data science? On the one hand yes, and on the other hand, this is hard too and understandable problems arise. Executives and managers often lack the requisite statistical expertise to evaluate operations like this in a rigorous way. They have heard, through professional networks, industry publications, media, etc., that more data and more A/B tests are Good Things for their organization. At a certain point, they cannot do the auditing of experimental procedures and inference themselves.
Shouldn’t the managers just make sure someone else can audit the statistics then? This is probably where the most important breakdowns occurred. Turns out that other staff possess all the skills to diagnose and repair the issues I identified (and more). One of these people had even been assigned to work with the team in question for a while! However, that assignment had ended during a restructuring and statistical expertise had never returned to the team. In the meantime, managers continued to demand results without fully appreciating that the existing approach had deep problems.
So given this particular mix of data and organizational sciences gone awry, what lessons can we learn?
The future of data-intensive social science remains, as William Gibson might say, unevenly distributed. As the infrastructure for data collection and analysis has become more widely accessible, the choke-point in many organizations has become the dissemination of deeper knowledge of the techniques necessary to produce valid, reliable inference. These inequalities emerge both within and between organizations. Some companies and some teams have more expertise than others. Some have more effective systems for feedback and improvement than others.
In this sense, organizational (not just technical or statistical) obstacles stand in the way of more effective, accountable, and transparent uses of evidence to make decisions. Web-scale organizations can run 100,000 randomized trials and analyze the results very quickly. The results can look real and have p-values attached and the executives can believe that they have got the whole data science thing nailed down. However, the analysis might not mean much unless it is implemented skillfully.
The inundation of behavioral trace data does not guarantee that we will be similarly inundated by reliable findings, valid inference, or skilled implementation. High quality research design and interpretation may not scale so easily as the data or the analysis tools.
All of this has distributive implications. Organizations with access to the best social scientific knowledge as well as the organizational capacity to deploy and harness that knowledge will be the ones most likely to reap benefits from it. Others, such as many public administrations in the U.S. (especially those that deliver social services), smaller firms, non-profits, and community organizations will likely get inferior inference (to the extent they get any at all).
It takes time and effort to build organizational resources and cultures capable of supporting widespread, high quality, data-driven inference. Some recent work in HCI and related fields speaks to these issues. For example, some folks at CU Boulder have a 2017 CHI paper about how mission-driven organizations can struggle to do data-driven work. In a more interventionist vein, Catherine D’Ignazio and Rahul Barghava have launched the Data Culture Project in an effort to help smaller non-profits and community organizations use data more effectively.
Whatever the organizational context, high quality social scientific and statistical work requires more than just a clear understanding of p-values and massive A/B testing infrastructure. Statistical expertise also needs to be embedded and managed effectively within organizations and teams in order to produce reliable inference.
This is a cross-post from the CASBS Medium channel. Thanks to members of the CDSC, Margaret Levi, and some anonymous friends for feedback on earlier versions of the text.
Discover more from Community Data Science Collective
Subscribe to get the latest posts sent to your email.
One Reply to “Adventures in applied data science”