
Workshop Report From Connected Learning Summit 2021
What are data literacies? What should they be? How can we best support youth in developing them via future tools? On July 13th and July 15th 2021, we held a two-day workshop at the Connected Learning Summit to explore these questions. Over the course of two very-full one-hour sessions, 40 participants from a range of backgrounds got to know each other, shared their knowledge and expertise, and engaged in brainstorming to identify important pressing questions around youth data literacies as well as promising ways to design future tools to support youth in developing them. In this blog post, we provide a full report from our workshop, links to the notes and boards we created during the workshop, and a description of how anyone can get involved in the community around youth data literacies that we have begun to build.
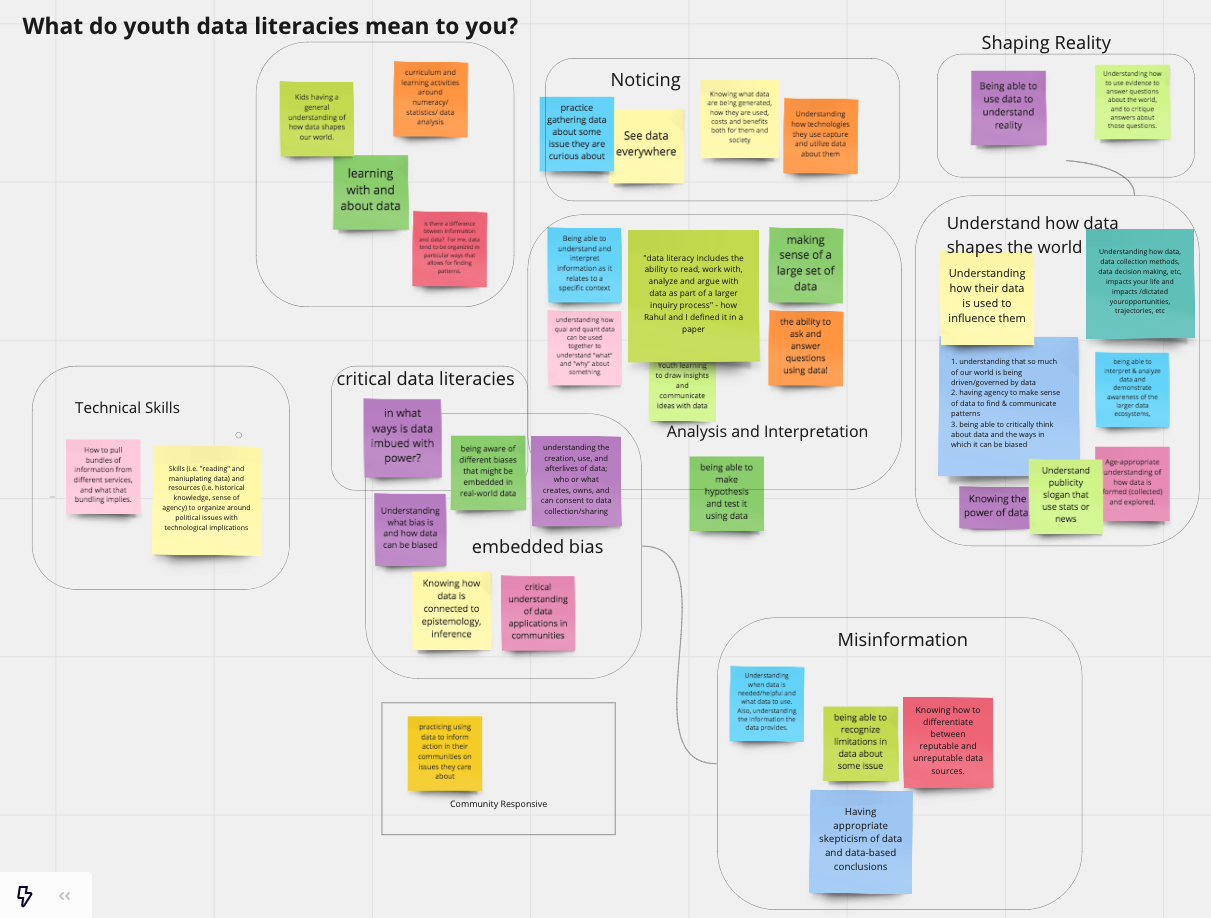
Caption: We opened our sessions by encouraging participants to share and synthesize what youth data literacies meant to them. This affinity diagram is the result.
How this workshop came to be
As part of the research team interested in research about learning at the Community Data Science Collective, we have long been fascinated with how youth and adults learn how to ask and answer questions with data While we have engaged with these questions ourselves by looking to Scratch and Cognimates, we are always curious about how we might design tools to promote youth data literacies in the future in other contexts.
The Connected Learning Summit is a unique gathering of practitioners, researchers, teachers, educators, industry professionals, and others, all interested in formal and informal learning and the impact of new media on current and future communities of learners. When the Connected Learning Summit put up a call for workshops, we thought this was a great opportunity to engage the broader community on the topic of youth data literacies.
Several months ago, the four of us (Stefania, Regina, Emilia and Mako) started to brainstorm ideas for potential proposals. We started by listing potential aspects and elements of data literacies such as: finding & curating data, visualizing & analyzing it, programming with data, and engaging in critical reflection. We then started to identify tools that can be used to accomplish each goal and tied to identify opportunities and gaps. See some examples of these tools on our workshop website.

Caption: Workshop core team and co-organizers community. Find out more here http://www.dataliteracies.com/
As part of this process, we identified a number of leaders in the space. This included people who have built tools like Rahul Bhargava and Catherine D’Ignazio who designed Databasic.io,Andee Rubinwho contributed to CODAP, and Victor Lee who focused on tools that link personal informatics and data. Other leaders included scholars who researched how existing tools are being used to support data literacies, including Tammy Clegg who has researched how college athletes develop data literacy skills, Yasmin Kafai who has looked at e-textile projects, and Camillia Matuk who has done research on data literacy curricula. Happily, all of these leaders agreed to join us as co-organizers for the workshop.
The workshop and what we learned from it
Our workshop took place on July 13th and July 15th as part of the 2021 Connected Learning Summit. Participants came from diverse backgrounds and the group included academic researchers, industry practitioners, K-12 teachers, and librarians. On the first day we focused on exploring existing learning scenarios designed to promote youth data literacies. On the second day we built on big questions raised in the initial session and brainstormed features for future systems. Both workshop sessions were composed of several breakout sessions. We took notes in a shared editor and encouraged participants to add their ideas and comments on sticky notes on collaborative digital white boards and share their definitions and questions around data literacies.
Caption: organizers and participants sharing past projects and ideas in a breakout session.
Day 1 Highlights
On Day 1, we explored a variety of existing tools designed to promote youth data literacies. We had a total of 28 participants who attended the session. We began with a group exercise where we shared their own definitions of youth data literacies before dividing into 3 groups: a group focusing on tools for data visualization and storytelling, a group focusing on block-based tools, and a group focusing on data literacy curricula. In each breakout session, our co-organizers first demonstrated one or two existing tools. Each group then discussed how the demo tool might support a single learning scenario based on the following prompt: “Imagine a six-grader who just learned basic concepts about central tendency, how might she use these tools to apply this concept on real world data?” Each group generated many reflective questions and ideas that would prompt and help inform the design of future data literacies tools. Results of our process are captured in the boards linked below.
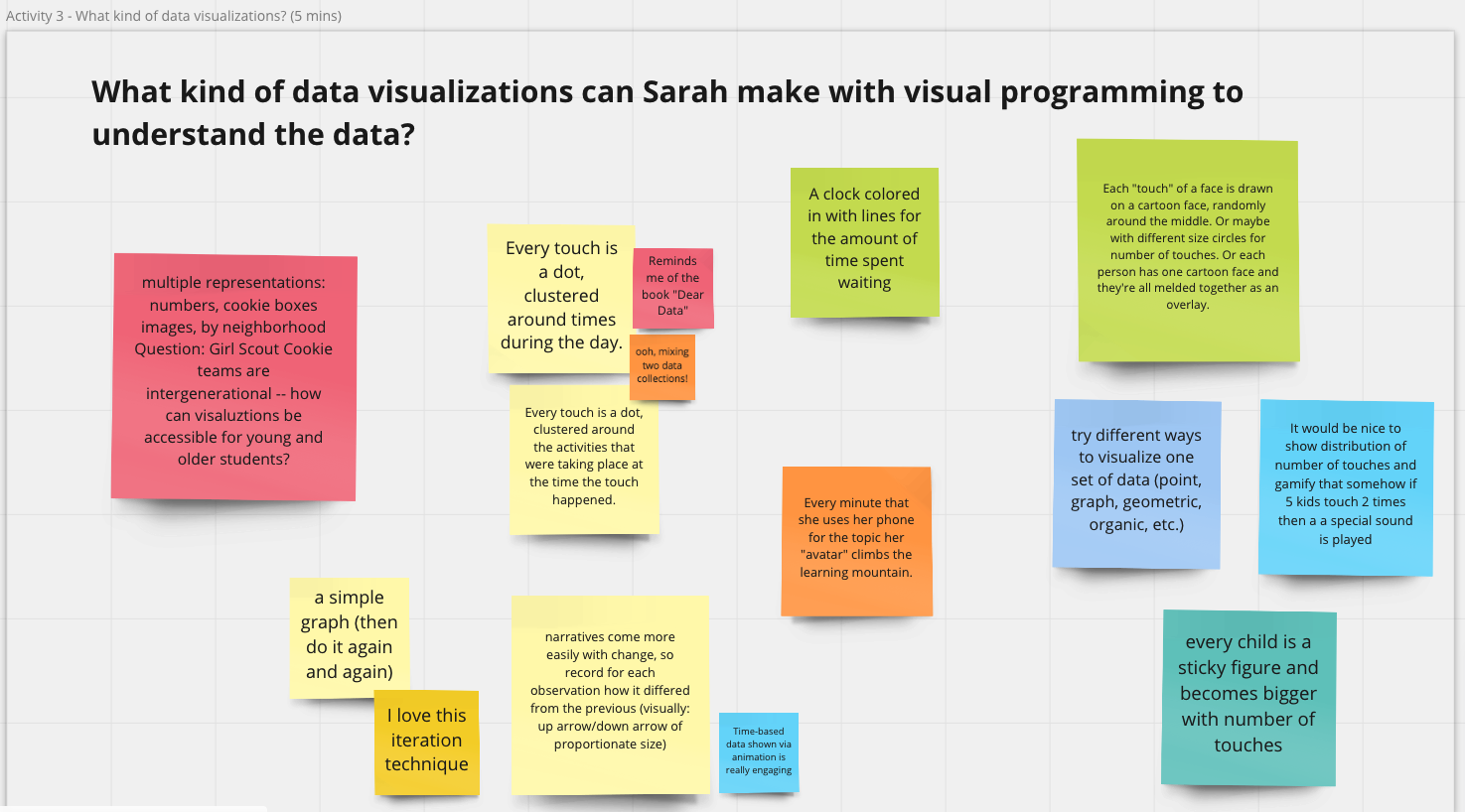
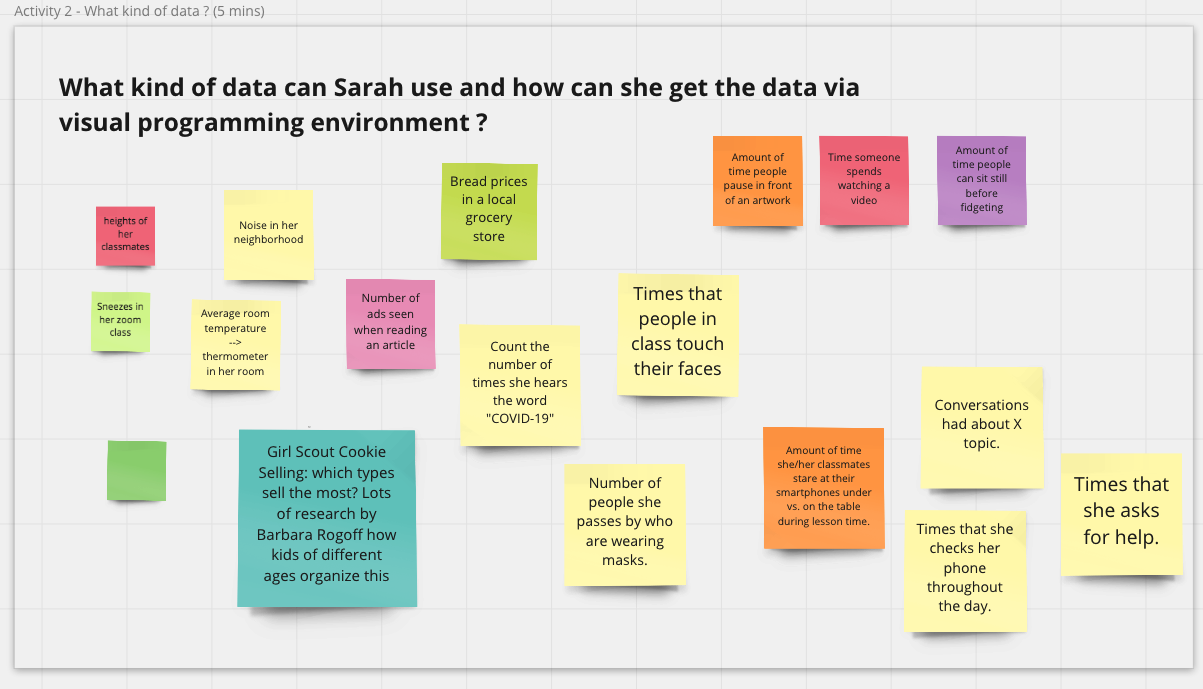

Caption: Activities on Miro boards during the workshop.
Data visualization and storytelling
Click here to see the activities on Miro board for this breakout session.
In the sub-section focusing on data visualization and storytelling, Victor Lee first demonstrated Tinkerplots, a desktop-based software that allows students to explore a variety of visualizations with simple click-button interaction using data in .csv format. Andee Rubin then demonstrated CODAP, a web-based tool similar to Tinkerplots that supports drag-and-drop with data, additional visual representation options including maps, and connection between representations.
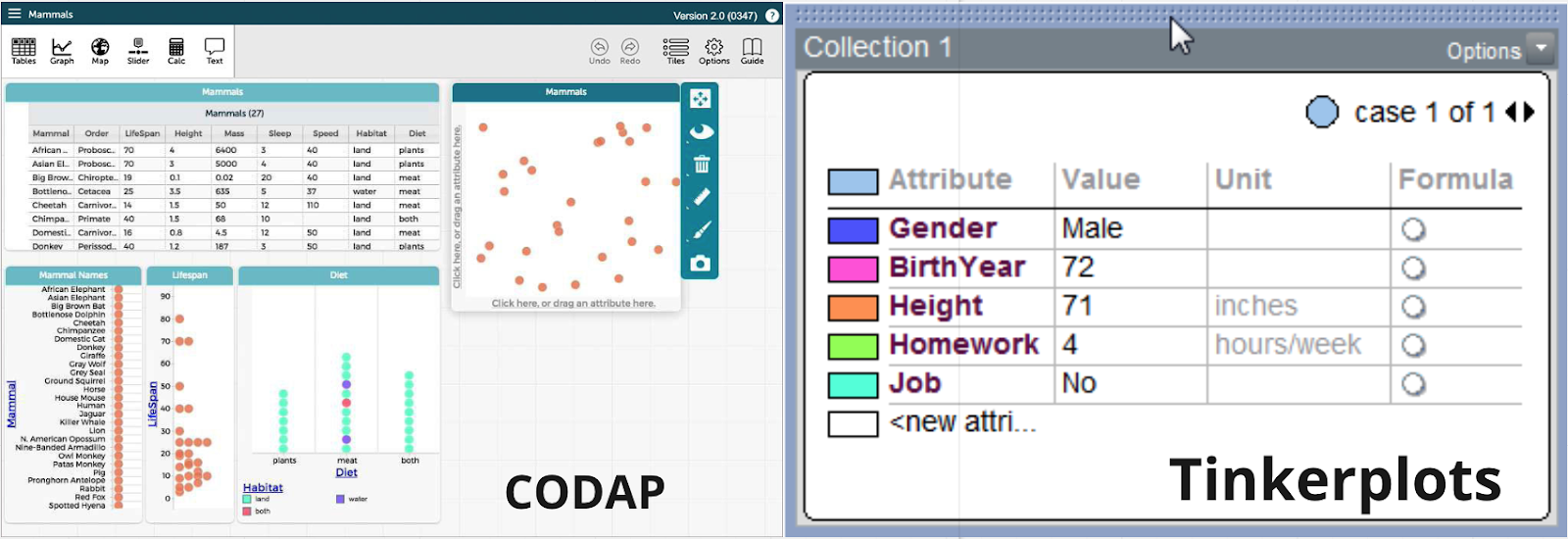
Caption: CODAP and Tinkerplots—two tools demonstrated during the workshop.
We discussed how various features of these tools could support youth data literacies in specific learning scenarios. We saw flexibility as one of the most important factors in tool use, both for learners and teachers. Both tools are topic-agnostic and compatible with any data in .csv format. This allows students to explore data of any topics that interest them. Simplicity in interaction is another important advantage. Students can easily see the links between tabular data and visualizations and try out different representations using simple interactions like drag-and-drop, check boxes, and button clicks. Features of these tools can also support students in performing aggregation on data and telling stories about trends and outliers.
We further discussed potential learning needs beyond what the current features could support. Before creating visualizations, students may need scaffolds during the process of data collection, as well as in the stage of programming with and preprocessing data. Story telling about the process of working with data was another theme that came up a lot from our discussion. Open questions include how features can be designed to support reproducibility, how we can design scaffolds for students to explain what they are doing with data in diary style stories, and how we can help students narrate what they think about a dataset and why they generate particular visualizations.
Block-based tools
Click here to see the activities on Miro board for this breakout session.
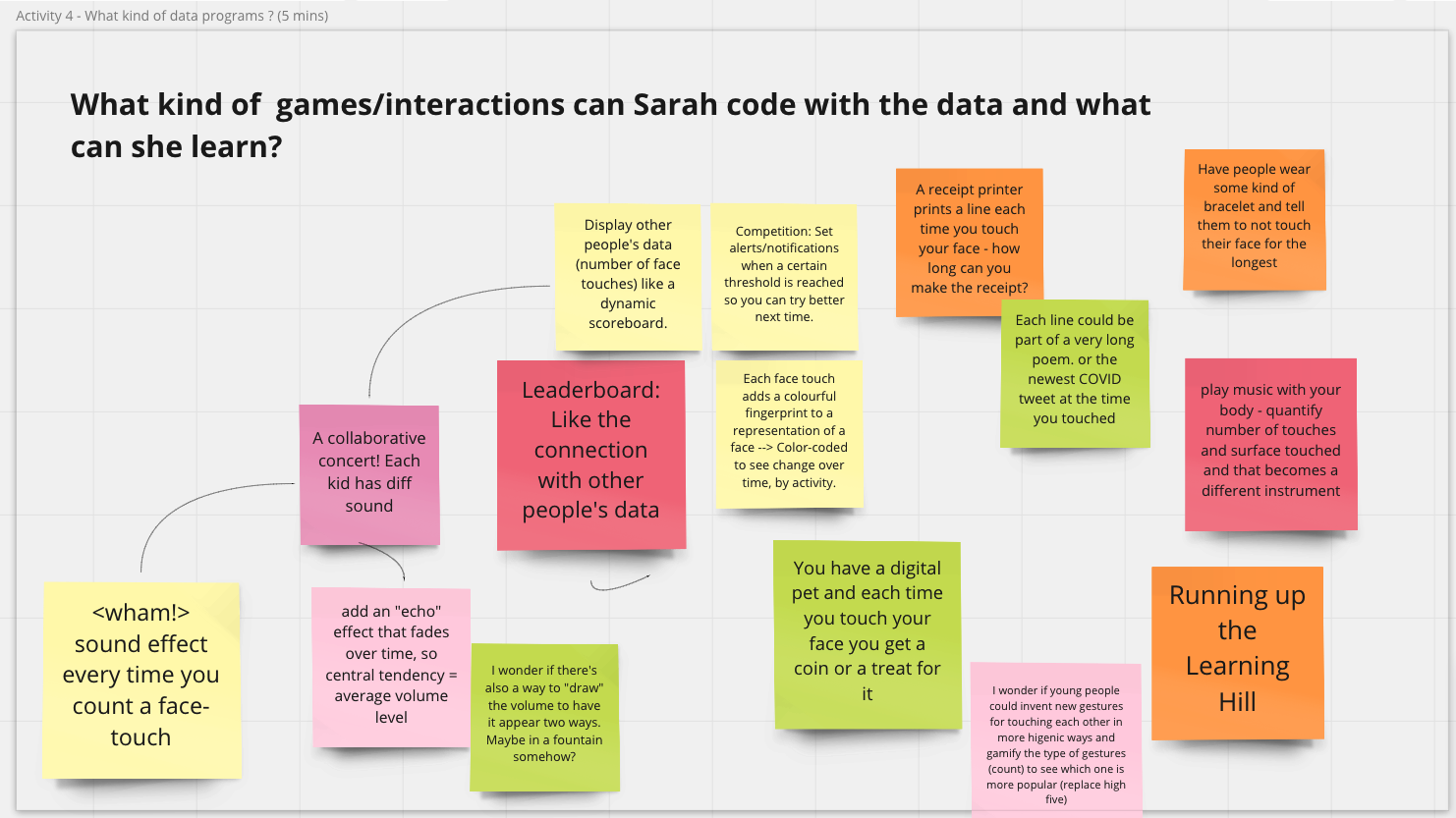
The breakout section about block-based tools started with PhD candidate Stefania Druga demonstrating a program in Scratch and how users could interact with data using the Scratch Cloud Data. We brainstormed about the kind of data students could collect and explore and the kind of visualization, game-based, or other creative interactions youth could create with the help of block-based tools. As a group, we came up with many creative ideas. For example, students can collect and visualize “the newest COVID tweet at the time you touched” a sensor and make “sound effect every time you count a face-touch.”

Caption: A Scratch project demonstrated during the workshop made with Cloud Data.
We discussed how interaction with data was part of an enterprise that is larger than any particular digital scaffold. After all, data exploration is embedded in social context and might reflect hot topics and recent trends. For instance, many of our ideas about data explorations were around COVID-19 related data and topics.
Our group also felt that interaction with data should not be limited to a single digital software. Many scenarios we came up with were centered on personal data collection in physical spaces (e.g., counting the number of times a student touches their own face). This points to a future design direction of how we can connect multiple tools that support interaction in both digital and physical spaces and encourage students to explore questions using different tools.
A final theme from our discussion was around how we can use block-based tools to allow engagement with data among a wider audience. For example, accessible and interesting activities and experience with block-based tools could be designed so that librarians can get involved in meaningful ways to introduce people to data.
Data literacy curriculum
Click here to see the activities on Miro board for this breakout session.
In the breakout section emphasizing on curriculum design, we started with an introduction by Catherine D’Ignazio and Rahul Bhargava on DataBasic.io’s Word Counter: a tool that allows users to paste in text to see word counts in various ways. We also walked through some curricula that the team created to guide students through the process of telling stories with data.
We talked about how this design was powerful in that it allows students to bring their own data and context, and to share knowledge about what they expect to find. Some of the scenarios we imagined included students analyzing their own writings, favorite songs, and favorite texts, and how they might use data to tell personalized stories from there. The specificity of the task supported by the tool enables students to deepen concepts about data by asking specific questions and looking at different datasets to explore the same question.

Caption: dataBASIC.io helps users explore data.
We also reflected on the fact that tools provided in Databasic.io are easy to use precisely because they are quite narrowly focused on a specific analytic task. This is a major strength of the tools, as they are intended as transitional bridges to help users develop foundational skills for data analysis. Using these tools should help answer questions, but should also encourage users to ask even more.
This led to a new set of issues discussed during the breakout session: How do we chain collections of small tools that might serve as one part of a data literacies pipeline together? This is where we felt curricular design could really come into play. Rather than having tools that try to “be everything,” using well-designed tools that address one aspect of an analysis can provide more flexibility and freedom to explore. Our group felt that curriculum can help learners reach the most important step in their learning, going from data to story to the bigger world—and to understanding why the data might matter.
Day 2 Highlights
The goal for the Day 2 of our workshop was to speculate and brainstorm future designs of tools that support youth data literacies. After our tool exploration and discussions on Day 1, three interesting brainstorming questions emerged across the breakout sections described above:
- How can we close the gap between general purpose tools and specific learning goals?
- How can we support storytelling using data?
- How can we support insights into the messiness of data and hidden decisions
We focused on discussing these questions on Day 2. A total of 29 participants attended and we once again divided into breakout groups based on the three questions above. For each brainstorming question, we considered the key questions in terms of the following three sub-questions: What are some helpful tools or features that can help answer the question? What are some pitfalls? And what new ideas can we come up with?
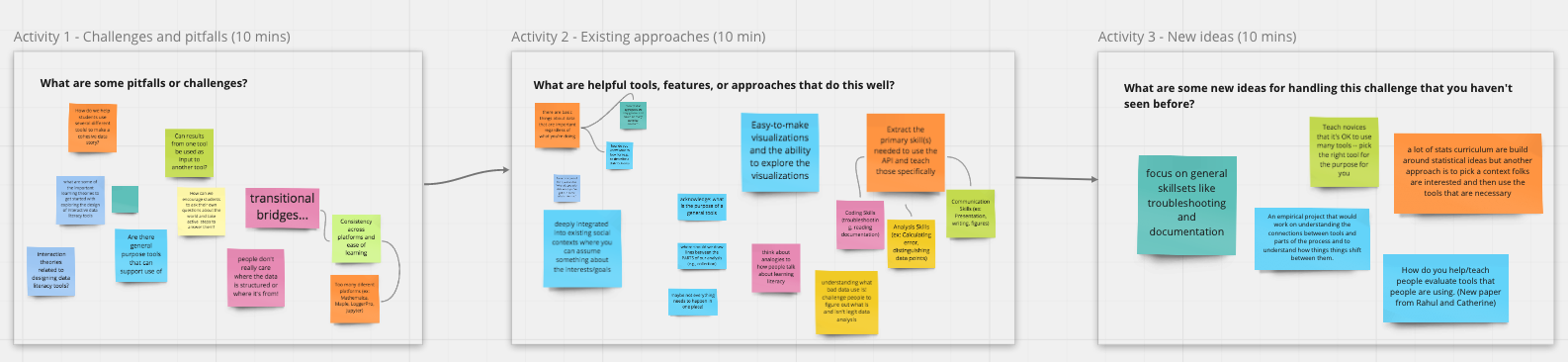
Caption: Workshop activities generated an abundance of ideas.
How can we close the gap between general purpose tools and specific learning goals?
Click here to see the activities on Miro board for this breakout session.
Often tools designed to solve a range of potential problems. That said, learners attempting to engage in data analysis are frequently faced with extremely specific questions about their analysis and datasets. Where does their data come from? How is it structured? How can it be collected? How do we balance the desire to serve many specific learners’ goals with general tools against the desire to handle specific challenges well?
As one approach, we drew lines between different parts of doing data analysis and frequently required features in different tools. Of course, data analysis is rarely a simple linear process. We also concluded that perhaps not everything needs to happen in one place or with one tool, and that this should be acknowledged and considered during the design process. We also discussed the importance of providing context within more general data analytic tools. We also talked about how learners need to think about the purpose of their analysis before they consider what tool to use and how, ideally, youth would learn to see patterns in data and to understand the significance of the patterns they find. Finally, we agreed that tools that help students understand the limitations of data and the uncertainty inherent in the data are also important.
Challenges and opportunities for telling stories with data
Click here to see the activities on Miro board for this breakout session.
In this section, we discussed challenges and opportunities around supporting students to tell stories with data. We talked about enabling students to recognize and represent the backstory of data. Open questions included: How do we make sure learners are aware of bias? And how can we help people recognize and document the decision of what to include and exclude?
As for telling stories about students’ own experience of working with data, collaboration was also a topic that came up frequently. We agreed that narrative with data is never an individual process. We discussed that future tools should be designed to support critique, iteration, and collaboration among storytellers, audiences, and maybe also between tellers and audiences.
Finally, we talked about future directions. This included taking a crowdsourced, community-driven approach to tell stories with data. We also noted that we had seen a lot of research effort to support storytelling about data in visualization systems or computational notebooks. We agreed that storytelling should not be limited to digital format and speculated that future designs could extend the storytelling process to unplugged, physical activities. For example, we can design to encourage students to create artefacts and monuments as part of the data storytelling process. We also talked about designing to engage people from diverse backgrounds and communities to contribute to and explore data together.
Challenges and opportunities for helping students to understand the messiness of data
Click here to see the activities on Miro board for this breakout session.
In this section, we talked about the tension between the need to make data clean and easy to use for students and the need to let youth understand the messiness of real world data. We shared our own experiences helping students engage with real or realistic data. A common way is to engage students in collaborative data production and have them compare the outcomes of a similar analysis between each other. For instance, students can document their weekly groceries and find that different people record the same items under different names. They can then come up with a plan to name things consistently and clean their data.
One very interesting point that came up from our discussion was what we really mean by “messy data.” “Messy,” incomplete, or inconsistent data may be unusable for computers while still comprehensible by humans. Therefore to be able to work with messy data does not only mean to have the skills to preprocess, but also involve the recognition of hidden human decisions and assumptions.
We came up with many ideas regarding future system design. We suggested designing to support crowdsourced data storytelling. For example, students can each contribute a small piece of documentation about the background of a dataset. Features might also be designed to support students to collect and represent the backstory of data in innovative ways. For example, functions that support the generation of rich media, such as videos, drawings, journal entries, can be embedded into data representation systems. We might also innovate on the way we design the interface of data storage so that students can interact with rich background information and metadata while still keeping the data “clean” for computation.
Next steps & community
We intend for this workshop to be only the beginning of our learning and exploration in the space of youth data literacies. We also hope to continue building the community we built. In particular, we have started a mailing list where we can continue our ongoing discussion. Please feel free to add yourself to the mailing list if you would like to be kept informed about our ongoing activities.
Although the workshop has ended, we have included links to many resources on the workshop website, and we invite you to explore the site. We also encourage you to contribute to a crowdsourced list of papers on data literacies by filling out this form.
This blog was collaboratively written by Regina Cheng, Stefania Druga, Emilia Gan, and Benjamin Mako Hill.
Stefania Druga is a PhD candidate in the Information School at University of Washington. Her research centers on AI literacy for families and designing tools for interest-based creative coding. In her most recent project, she focuses on building a platform that leverages youth creative confidence via coding with AI agents.
Regina Cheng is a PhD candidate in the Human Centered Design and Engineering department at University of Washington. Her research centers on broadening and facilitating participation in online informal learning communities. In her most recent work, she focuses on designing for novices’ engagement with data in online communities.
Emilia Gan is a graduate student in the Paul G. Allen School of Computer Science and Engineering (UW-Seattle). Her research explores factors that lead to continued participation of novices in computing.
Benjamin Mako Hill is an Assistant Professor at UW. His research involves democratizing data science—and doing it from time to time as well.
Discover more from Community Data Science Collective
Subscribe to get the latest posts sent to your email.
One Reply to “Future Tools for Youth Data Literacies”