It seems natural to think that online political discussion happens in political spaces: comment sections under news articles, campaign pages, partisan forums, or video-sharing communities built around elections and public affairs.
But anyone who spends time online knows that politics does not stay neatly contained in those spaces. It shows up in local forums, hobby groups, gaming communities, entertainment discussions, and personal social media feeds. A conversation that begins with everyday life can suddenly become a debate about policy, rights, or government.
Communication scholars call this incidental political discussion: political talk that emerges in spaces not primarily organized around politics. I was interested in a simple question: what happens when people talk about politics in non-political online communities?
A common expectation in political communication research is that these conversations might be less polarized and more civil than political talk in explicitly political spaces. The logic goes: in non-political communities, people may not arrive with partisan identities already activated. They may also be guided by community norms built around shared interests, local concerns, or social connection rather than political conflict.
We wanted to test whether political talk in non-political spaces was actually less polarized, and perhaps less uncivil in real-world digital communities. To do so, I led an effort (with the support of Benjamin Mako Hill and Patricia Moy) to examine Reddit discussions about mass shootings and gun control in October 2017. Sampling over 100,000 comments on gun control issues across the platform that month, we compared comments from 15 explicitly political communities with those from 15 non-political communities, including culture-, location-, and game-based ones, among others.
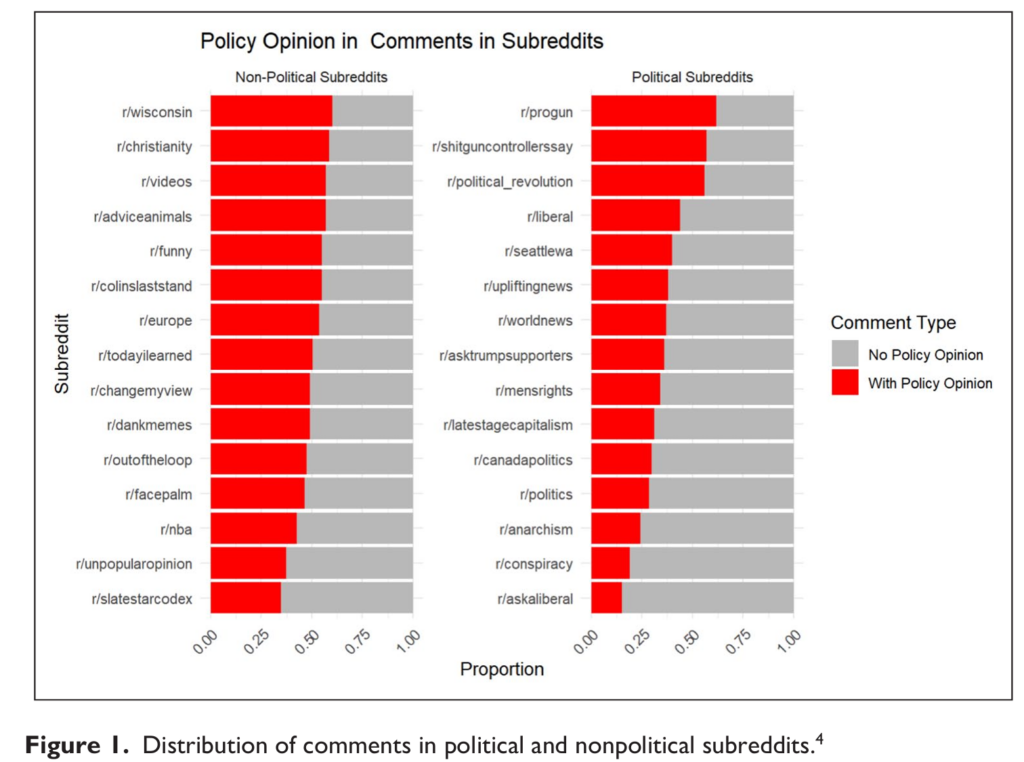
The results surprised us. As the figure below from our study shows, policy opinion expression was, on average, more common in non-political communities than in political ones. Several non-political subreddits—including r/Wisconsin, r/Christianity, r/videos, and r/funny—had especially high levels of policy opinion expression. In total, 10 non-political subreddits had policy opinions in more than half of the sampled comments. By contrast, only three political subreddits—r/progun, r/ShitGunControllersSay, and r/Political_Revolution—crossed the same 50% threshold. This pattern suggests that policy talk is not confined to explicitly political spaces; in some cases, it appears even more frequently in communities organized around local life, religion, entertainment, or humor.
After accounting for a range of factors in our regression model, we found that comments in non-political communities were more likely to contain a clear policy opinion than comments in explicitly political communities. The model estimated that the predicted probability of expressing a clear policy position was about 34% in political communities, compared with 51% in non-political communities. This difference was statistically significant. At the same time, we found no significant difference in incivility between political and non-political communities.
This combination of findings was especially interesting and contrasts with what’s most commonly reported in the current social science literature on digital political communication.
One possible explanation is that participants in explicitly political communities are often immersed in ongoing political debate. Their comments may include detailed argumentation, interpretation, irony, criticism of political actors, or discussion of the news cycle without always stating a clear policy position. By contrast, when a major political issue enters a non-political community, participants may be more likely to be newly exposed to it and react by saying what they think should be done.
Another explanation for incivility is that Reddit’s community-based moderation matters. Many communities, political and non-political alike, rely on rules, moderators, and shared expectations that can limit openly uncivil behavior. This helps explain why we did not find a significant difference in incivility: both types of communities show a low level of uncivil comments (around 6% of the sample).
The broader lesson is that political communication does not only happen where politics is expected. It also happens in the ordinary spaces of digital life, where people gather to talk about games, cities, hobbies, entertainment, or shared interests. If we want to understand democracy online, we need to pay attention not only to where people go to talk about politics, but also to where politics shows up uninvited.
Often, several different online communities exist where similar people talk about similar things. This is really easy to observe from browsing platforms like Reddit or Facebook groups.
Names of bicycle-related subreddits in cluster of subreddits with many overlapping users.
For example, as we can see from this visualization of clustered subreddits with overlapping users, there are many different subreddits related to cycling. We see some communities have different emphases in complementary ways like “fixedgearbicycle” and “bicycletouring” — these are different types of cycling. But why have a community for “cycling” and a different one for “bicycling”? A number of puzzles appear when we reflect on the existence of such related communities.
How do online communities relate to each other?
Why not have one large community that does everything?
How do people construct these systems of related online communities?
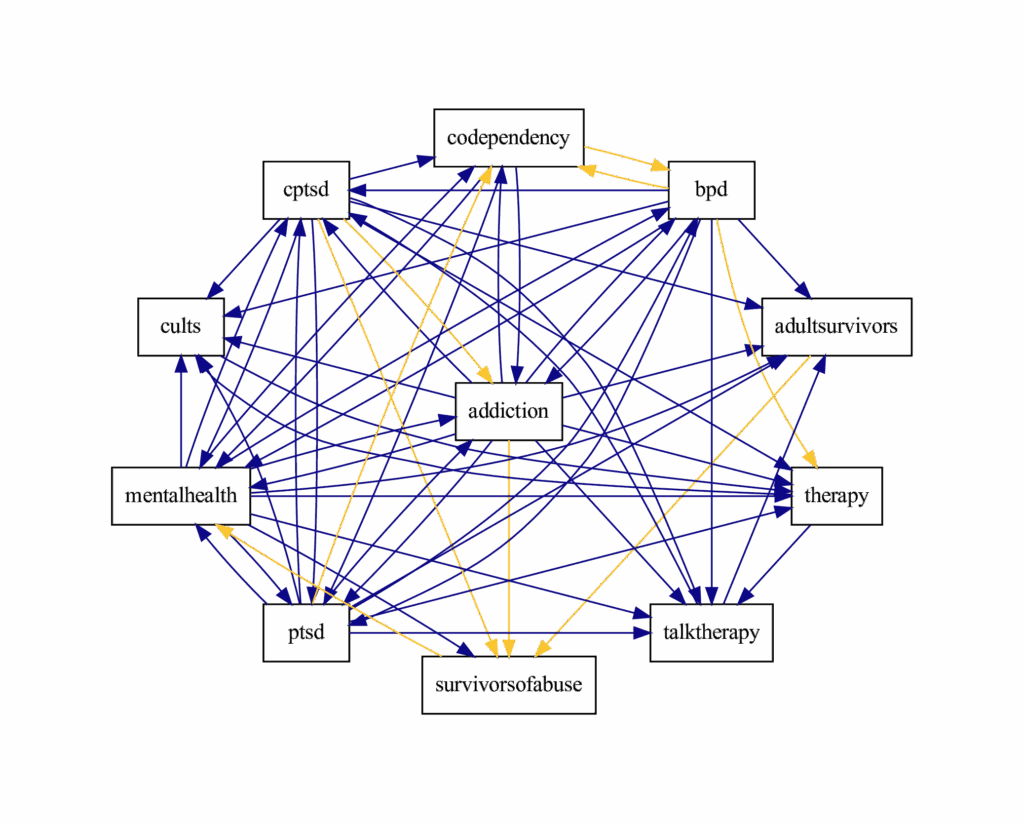
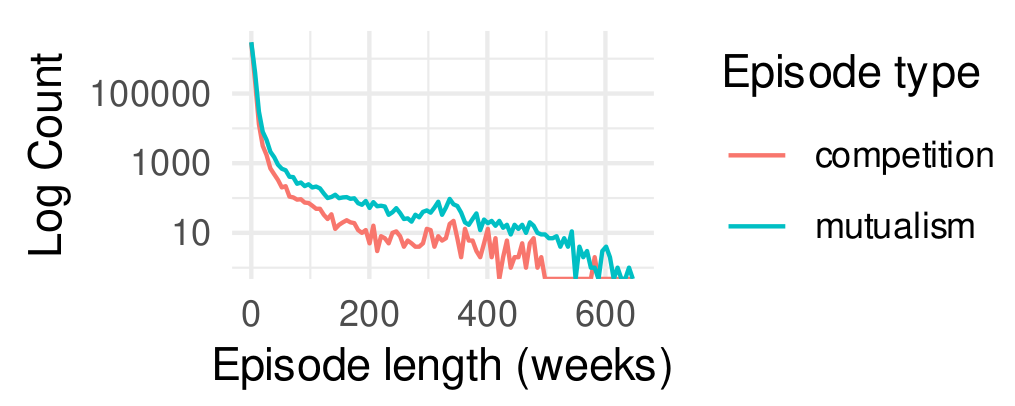
I investigated these questions in my dissertation using the theoretical lens of organizational ecology drawn from organizational sociology. This new paper explored some findings from earlier projects in more depth. The paper I published in ICWSM 2022 (pdf), takes up the question of ecological relationships among online communities. I used time series models to infer networks of competition and mutualism between overlapping online communities. This work found evidence that they tended to be mutualistic. For example, the diagram below shows a network of mental health subreddits that is dense with mutualism.
Ecological network of a cluster of mental subreddits. Blue arrows indicate mutualism and yellow arrows indicate competition according to a vector autoregression model.
However, this method, based on vector autoregression (VAR) models of activity, assumes that these relationships are static and constant over time. But dynamics of attention online are often bursty, and online communities grow, decline, and change over time in other ways. So, in this new work, I adopted nonlinear models called (regularized) S-map that can model more complex dynamics.
Since I found in the previous work that mutualism tended to happen more often than competition, I wanted to find out if that result was robust using the S-map. Since the S-map breaks these relationships down into episodes of competition or mutualism it afforded testing a more nuanced hypothesis about this tendency towards mutualism.
H1: Mutualistic interactions will be more frequent and longer lasting than competitive interactions.
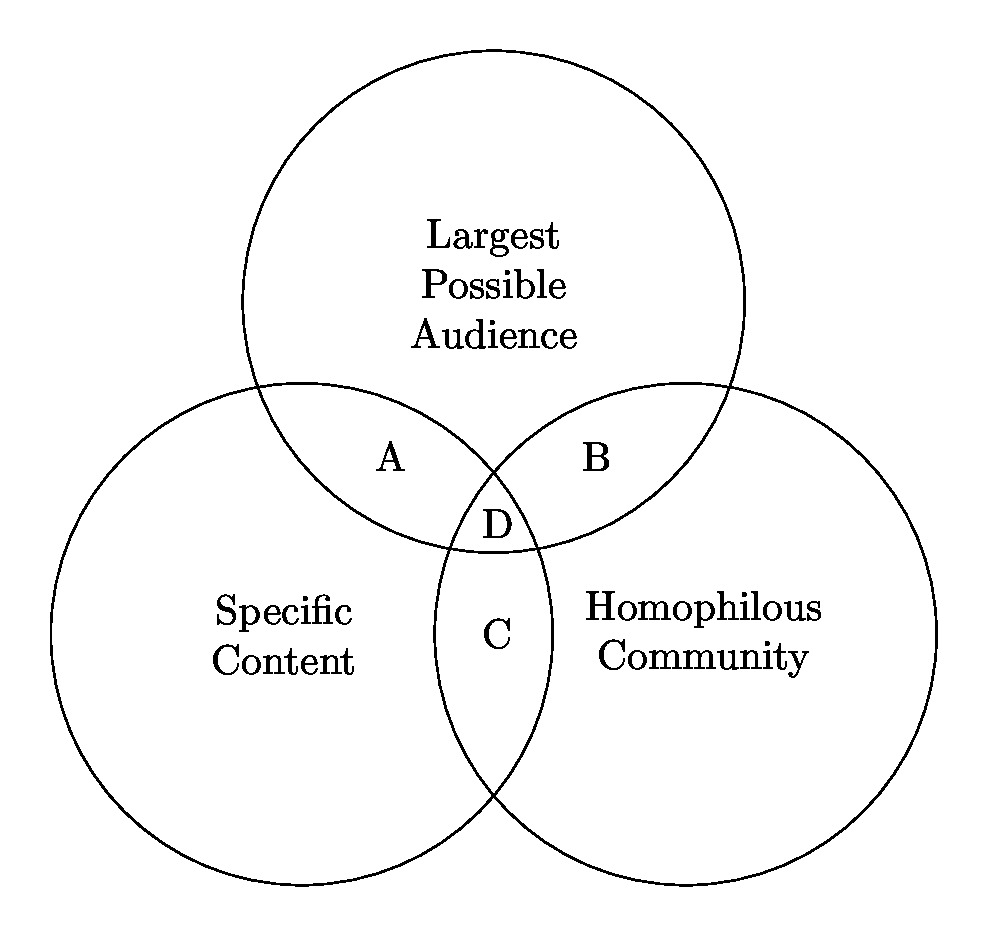
In the another empirical paper previously published at CSCW 2022 (acm dl), we focused on the question of why people build overlapping online communities and found that they complementary sets of benefits to members, as illustrated below. Trade-offs between the benefits lead to specialized roles for different types of communities.
Figure from “No Community Can Do Everything: Why People Participate in Similar Online Communities” depicts three key benefits that people seek from online communities and how individual communities tend not to optimally provide all three. For example, large communities tend not to afford tight-knit homophilous community.
This reflects propositions from ecology that specialization can be a strategy to avoid competition. The new study seeks to provide more generalizable quantitative evidence about how online communities find their specialized niches. Ecology theory suggests that online communities, similar to organizations or organisms, might adapt to increase specialization and thereby promote more mutualistic relationships. To investigate whether people build specialized online communities through such an adaptive feedback process, I set out to test the following two hypotheses:
H2: Two communities having greater competition (mutualism) will subsequently have greater decreases (increases) in overlap.
H3: Two subreddits having decreasing (increasing) overlap will subsequently have greater mutualism (competition).
Methods and measures
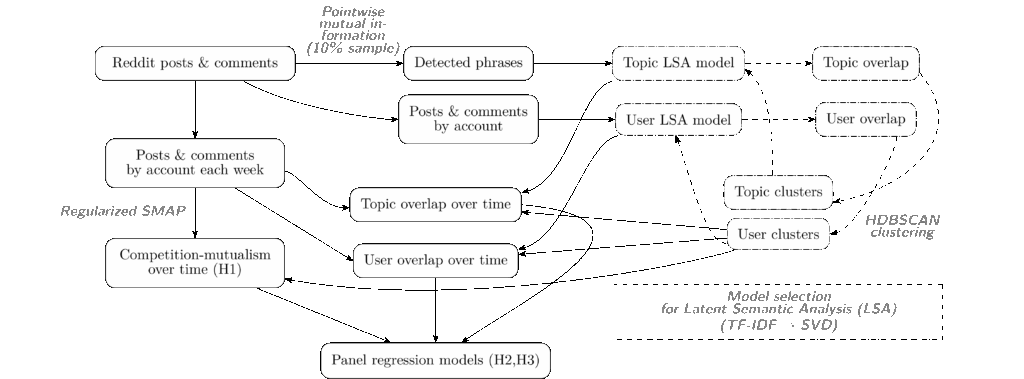
To test these three hypotheses, I had to measure competition/mutualism, and overlap within clusters of related subreddits over time. I made topic- and user-overlap measures based on a community embedding via the LSA algorithm. To create the clusters I reused the approach from the earlier paper by using the HDBSCAN algorithm based on user overlap. As mentioned above I used the Regularized S-MAP algorithm to create a dynamic measure of ecological influence. With these longitudinal measures in hand I could test the hypotheses using two-way fixed-effects panel data estimators with dyad-robust standard errors. That’s a brief and dense summary of the methods. The chart below might help you make sense of it, but if you care to fully understand you’ll want to check out the full paper.
This flowchart illustrates the dataset and measures in the study. On the left-hand side, nonline “Regularized S-Map models” are fit to time series of posts and comments in clusters of subreddits with high user-overlap to test hypothesis 1. In the middle, competition and mutualism from the S-Map models are used with longitidunal measures of topic and user overlap based on community embeddings in panel regression models to test hypotheses 2 and 3. Model selection is on the right-hand side.
Here are a few final notes on the data and methods. The data came from the Pushshift Reddit archive of submissions and comments from December 5th 2015 to April 13th 2020. I Started with the 19,533 subreddits that were active during at least 20% of study period weeks, excluding NSFW subreddits. HDBSCAN clustering discovered related 1,919 clusters of 8,806 subreddits having 48,484 relationships measured 17,374,116 times over 758 weeks.
Results
I found support for H1, which predicted that mutualistic interactions will be more frequent and longer lasting than competitive interactions. The plot below shows evidence in favor of the hypothesis. First, we can see clearly that the longest episodes tend to be mutualistic. Notably, these ecological relationships are often bursty and short-lived. The average length of a mutualistic episode was 2.13 weeks and the average length of a competitive episode was just 1.83 weeks.
Frequency plot of the durations of competition and mutualism episodes. Mutualism tends to last longer than competition. The y-axis is log-transformed. The axes truncated to omit outliers for visibility.
I also found support for H2, which predicted that I’d find positive coefficients for previous ecological interaction indicating that competition predicts decreases in overlap. Indeed, the panel regression models found that online communities tend to increase their specialization a bit in relatively competitive conditions, by about 0.02 standard deviations in term or user overlap for every 1-unit increase in competition.
Do increasingly specialized communities tend to decrease their competition as predicted by H3? My analysis didn’t find evidence for this. In fact, according to the panel regression models, after specialization increases, competition actually tends to increase as well.
Discussion
What to take away from all this? I still think the most important finding from this work to me is the robustness of the tendency toward mutualism among online communities. Unlike firms or other organizations that demand relatively exclusive commitments from their members, it is easy to participate in many online communities. Where classical organizations (imagine firms, churches, sports teams, nonprofit, and state organizations) seem likely to compete over employees, customers, or members online communities seem to benefit to some extant from sharing users with each other. I suspect this has to do with the ease with which nonrival content, ideas, and knowledge move between communities.
A second important takeaway from this work is that I think the evidence it finds for the adaptation explanation for the tendency toward mutualism isn’t all that convincing. Sure, communities in competition tend to become more specialized, but the effect size is pretty small and the fact that specialization doesn’t reduce competition suggests that it isn’t truly adaptive in the strongest sense. Put another way, specialized online communities might be made via an adaptive process, or they might be born out of the intentions and designs of their founders and early joiners. This work finds a bit of evidence for how specialization might be made, but the born process merits more investigation.
One clue about the significance of design for specialization comes from fellow CDSC-er Jeremy Foote‘s a nice CHI paper (acm dl) last year on how the early stages of a subreddit’s development are important to its trajectory and found that most subreddit creators didn’t set out to create a large community. Another study (arxiv.org), by Chenhao Tan on “community genealogy” shows how the growth of new subreddits often seems to depend on having high overlap with a “parent” subreddit. These papers don’t focus on specialization, but it would be cool to see future work take up these ideas.
If you enjoyed reading this summary or want to learn more, please check out the full paper. I got the chance to speculate a bit about what sorts of future technology designs might assist community leaders in crafting online communities to fill ecological roles. I also got to engage with ecological theory in a new way writing this. I hope you read and enjoy.
Finally, I wasn’t able to attend ICWSM in person this year, so I want to thank Kristen Engel for presenting on my behalf. I also want to note that CDSC-er Kaylea Champion and I were both recognized as “best reviewers” at the conference.
This work started as a chapter of my dissertation. Thanks to the committee — Professors Benjamin Mako Hill, Kirsten Foot, Aaron Shaw, David McDonald and Emma Spiro.
I also gratefully acknowledge support by NSF grants IIS-1908850 and IIS-1910202 and GRFP \#2016220885. This work was facilitated through the use of the advanced computational infrastructure provided by the Hyak supercomputer system at the University of Washington and TACC at the University of Texas.
Community decay and abandonment are persistent risks to free/libre and open source software (FLOSS) projects. As such, large institutions such as GitHub or Mozilla offer advice to FLOSS projects on how to organize their work for sustainability and community-building. Guides recommend the production of README files and CONTRIBUTING guides as useful tools in recruiting new project contributors and driving activity. Yet though the development of these documents is widely-suggested, there is little empirical study of how projects use these files and what happens when documents are introduced to projects.
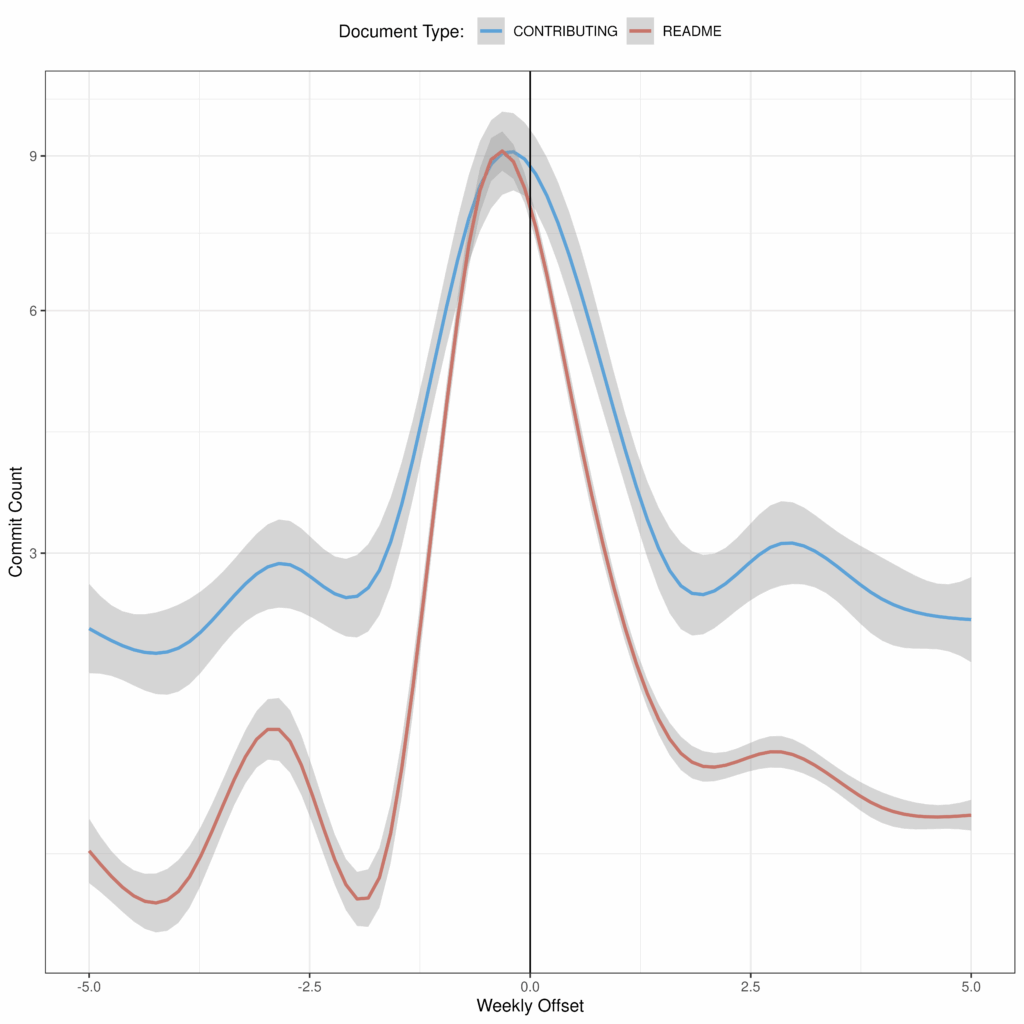
Plot of average (log-transformed) weekly contribution counts over time around the point of document introduction (weeks offset from document publication date) for README (red) and CONTRIBUTING (blue) files. The Y-axis has been scaled to real count values.
In one of the first empirical studies of the initial publication of documentation files, our findings suggest a disconnect between institutional recommendations and FLOSS projects’ actual use the documents. Instead of being proactively developed and community-oriented, first-version files are published following an increase of activity and focus on the functional details of using or contributing to the library. Often, documents are published with hardly any content at all, with projects publishing empty or minimal files. We found no support for any causal claims around the nature of a document’s depth or focus and subsequent project activity.
Our results suggest that projects may use these documents to perform a norm. The publication of empty documentation files implies that an empty file in their home directory was more important to projects than any benefits of document contents. Our results also suggest that projects may use these documents to ‘get their house in order’ after an influx of activity.
The guides and recommendations that we examined did not specify when projects should take what actions to grow sustainably. This lack of specificity limits the utility for projects trying to figure out how to sustain themselves in ever-changing environments. The work necessary to develop meticulous, community-oriented files may not be a good time investment for early-stage projects with only a handful of contributors. More research is necessary to develop useful context-situated recommendations to support FLOSS projects adaptation.
This paper was presented a few weeks ago in Ottawa at the International Conference on Cooperative and Human Aspects of Software Engineering (CHASE) 2025. A pre-print of the paper can be found here; the data and code for the project can be found here.
This research wouldn’t be possible without the work of the volunteers producing FLOSS who have made their work available for inspection. We also gratefully acknowledge support from the Ford/Sloan Digital Infrastructure Initiative (Sloan Award 2018-113560) and the National Science Foundation (Grant IIS-2045055). This work was conducted using the Hyak supercomputer at the University of Washington as well as research computing resources at Northwestern University.
If you are attending the ACM conference on Computer-supported Cooperative Work and Social Computing (CSCW) this year CSCW in San José, Costa Rica. You are warmly invited to join CDSC members during our talks and other scheduled events. Please come say hi!
This CDSC has four papers at CSCW, which we will be presenting over the next three days:
Monday: At 11:00 am in Talamanca, Kaylea Champion will be presenting “Life Histories of Taboo Knowledge Artifacts” (full paper)
Tuesday: At 11:00 am in Central 3, Zarine Kharazian will be presenting “Governance Capture in a Self-Governing Community: A Qualitative Comparison of the Croatian, Serbian, Bosnian, and Serbo-Croatian Wikipedias” (full paper, blog post), followed by Sohyeon Hwang presenting “Adopting third-party bots for managing online communities” (full paper, blog post)
Wednesday: At 2:30 pm in Guanacaste 3, Kaylea Champion will be co-presenting “Challenges in Restructuring Community-based Moderation” (full paper, preprint)
If you’re at CSCW, feel free to get in touch in person or via Discord!
A screenshot of the configuration panel for Moderator functions of a popular end-user bot called Dyno, adopted by millions of communities on Discord.
Bots made by end users are crucial to the success of online communities, helping community leaders moderate content as well as manage membership and engagement. But most folks don’t have the resources to develop custom bots and turn to existing bots shared by their peers. For example, on Discord, some especially popular bots are adopted by millions of communities. However, because these bots are ultimately third-party tools — made by neither the platform nor the community leader in question — they still come with several challenges. In particular, community leaders need to develop the right understandings about a bot’s nature, value, and use in order to adopt it into their community’s existing processes and culture.
In organizational research, these “understandings” are sometimes described as technological frames, a concept developed by Orlikowski & Gash (1994) as they studied why technologies became used in unexpected ways in organizational settings. When your technological frames are well-aligned with a tool’s design, you can imagine that it is easier to assess whether that tool will be useful and can be smoothly incorporated into your organization as intended. In the context of online communities, well-aligned frames can not only reduce the labor and time of bot adoption, but also help community leaders anticipate issues that might cause harm to the community. Our new paper looks to communities on Discord and asks: How do community leaders shift their technology frames of third-party bots and leverage them to address community needs?
Emergent social ecosystems around bot adoption
Our study interviewed 16 community leaders on Discord, walking through their experiences adopting third-party bots for their communities. These interviews underscore how community leaders have developed social ecosystems around bots: organicuser-to-user networks of resources, aid, and knowledge about bots across communities.
Despite the decentralized arrangement of communities on Discord, users devised and took advantage of formal and informal opportunities to revise their understandings about bots, both supporting and constraining how bots became used. This was particularly important because third-party bots pose heightened uncertainties about their reliability and security, especially for bots used to protect the community from external threads (such as scammers). For example, interviewees laid out concerns about whether a bot developer could be trusted to keep their bot online, to respond to problems users had, and to manage sensitive information. The emergent social ecosystems helped users get recommendations from others, assess the reputation of bot developers, and consider whether the bot was a good fit for them along much more nuanced dimensions (in the case of one interviewee, the values of the bot developer mattered as well). They also created opportunities for people to directly get help in setting up bots and troubleshooting them, such as via engaged discussions with other users who had more experience.
Our findings underscore a couple of core reasons why we should care about these social ecosystems:
Closing gaps in bot-related skills and knowledge. Across interviews, we saw patterns of people leveraging the resources and aid in social ecosystems to move towards using more powerful but complex bots. Ultimately, people with diverse technical backgrounds (including those who stated they had no technical background) were able to adopt and use bots — even bots involving code-like configurations in markdown languages that might normally pose barriers. We suggest that the diffusion of end-user tools on social platforms be matched with efforts to provide bottom-up social scaffoldings that support exploration, learning, and user discussion of those tools.
Changing perceptions of the labor involved in bot adoption. The process of bot adoption as a deeply social one appeared to impact how people saw the labor they invested into it, shifting it into something fun and satisfying. Bot adoption was both collaborative, involving many individuals as a user discovered, evaluated, set up, and fine-tuned bots; and communal, with community members themselves taking part in some of these steps. We suggest that bot adoption can provide one avenue to deepen community engagement by creating new ways of participating and generating meta discussions about the community, as well as the platform.
Shaping the assumptions around third-party tools. Social ecosystems enabled people to cherry-pick functions across bots, enabling creative wiggle room in curating a set of preferred functions. At the same time, people were constrained by social signals about what bots are and can do, why certain bots are worth adopting, and how the bot is used. For example, people often talked about genres of bots even though no such formal categories existed. We suggest that spaces where leaders from different communities interact with one another to discuss strategies and experiences can be impactful settings for further research, intervention, and design ideas.
Ultimately, the social nature of adopting third-party bots in our interviews offers insight into how we can better support the adoption of valuable user-facing tools across online communities. As online harms become more and more technically sophisticated (e.g., the recent rise of AI-generated disinformation), user-made bots that quickly respond to emerging issues will play an important role in managing communities — and will be even more valuable if they can be shared across communities. Further attention to the dynamics that enable tools to be used across communities with diverse norms and goals will be important as the risks that communities face, and the tools available to them, evolve.
Engage with us!
If you have thoughts, ideas, questions, we are always happy to talk – especially if you think there are community-facing resources we can develop from this work. There are a few ways to engage with us:
Hundreds of new subreddits are created every day, but most of them go nowhere, and never receive more than a few posts or comments. On the other hand, some become wildly popular. If we want to figure out what helps some things to get attention, then looking at new and small online communities is a great place to start. Indeed, the whole focus of my dissertation was trying to understand who started new communities, and why. So, I was super excited when Sanjay Kairam at Reddit told me that Reddit was interested in studying founders of new subreddits!
The research that Sanjay and I (but mostly Sanjay!) did was accepted at CHI 2024, a leading conference for human-computer interaction research. The goal of the research is to understand 1) founders’ motivations for starting new subreddits, 2) founders’ goals for their communities, 3) founders’ plans for making their community successful, and 4) how all of these relate to what happens to a community in the first month of its existence. To figure this out, we surveyed nearly 1,000 redditors one week after they created a new subreddit.
Lots of Motivations and Goals
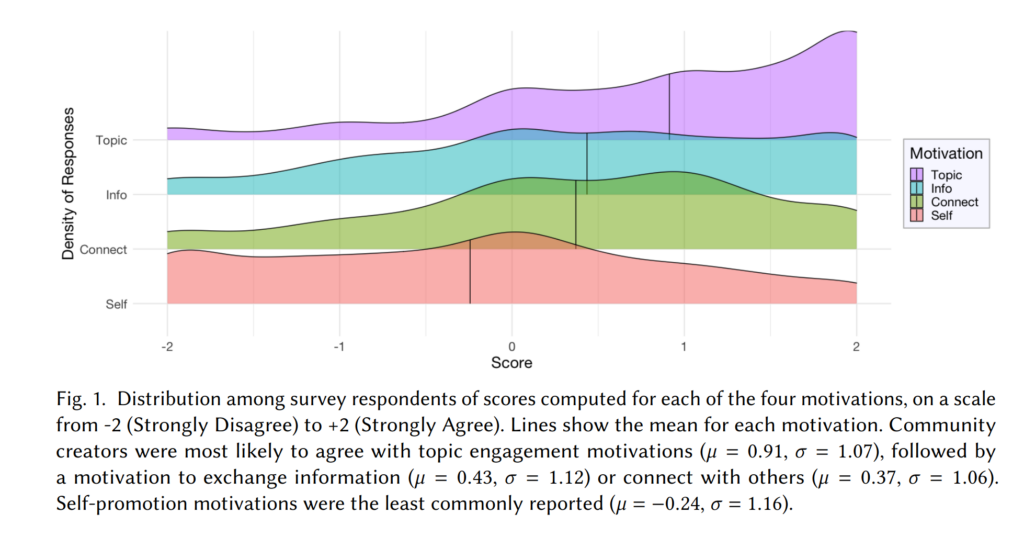
So, what did we learn? First, that founders have diverse motivations, but the most common is interest in the topic. As shown in the figure above, most founders reported being motivated by topic engagement, information exchange, and connecting with others, while self-promotion was much more rare.
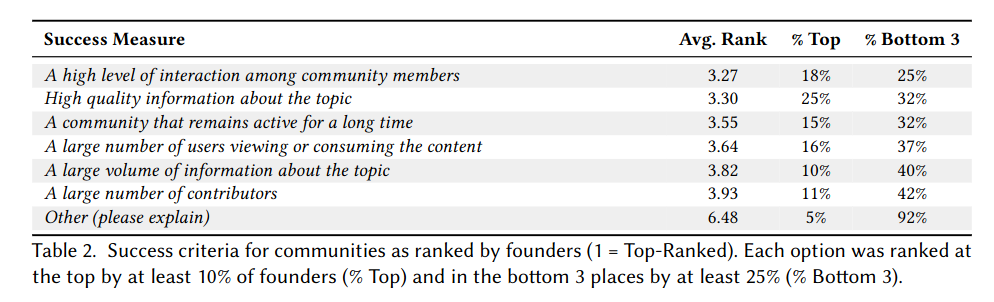
When we asked about their goals for the community, founders were split, and each of the options we gave was ranked as a top goal by a good chunk of participants. While there is some nuance between the different versions of success, we grouped them into “quantity-oriented” and “quality-oriented”, and looked at how motivations related to goals. Somewhat unsurprisingly, folks interested in self-promotion had quantity-oriented goals, while those interested in exchanging information were more focused on quality.
Diversity in plans
We then asked founders about what plans they had for building their community, based on recommendations from the online community literature, such as raising awareness, welcoming newcomers, encouraging contributions, and regulating bad behavior. Surprisingly, for each activity, about half of people said they planned to engage in doing that thing.
Early Community Outcomes
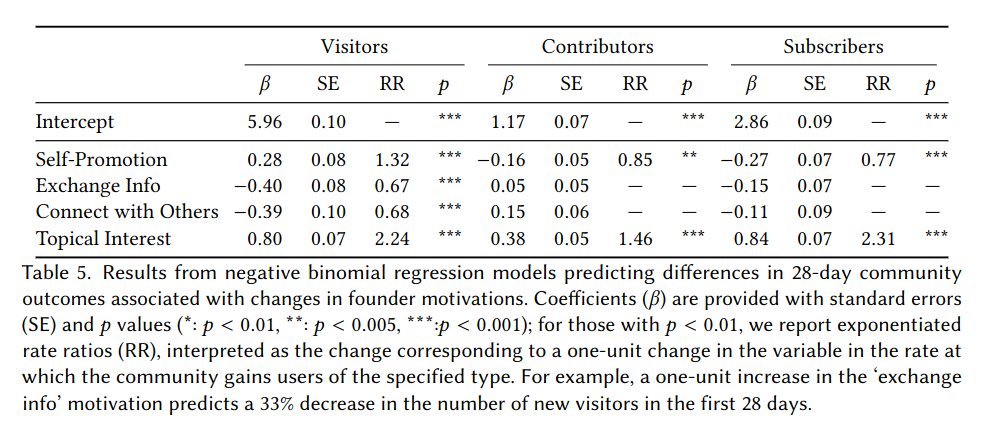
So, how do these motivations, goals, and plans relate to community outcomes? We looked at the first 28 days of each founded subreddit, and counted the number of visitors, number of contributors, and number of subscribers. We then ran regression analyses analyzing how well each aspect of motivations, goals, and plans predicted each outcome. High-level results and regression tables are shown below. For each row, when β is positive, that means that the given feature has a positive relationship with the given outcome. The exponentiated rate ratio (RR) column provides a point estimate of the effect size. For example, Self-Promotion has an RR of 1.32, meaning that if a given person’s self-promotion motivation was one unit higher the model predicts that their community would receive 32% more visitors.
A number of motivations predicted each of the outcomes we measured. The only consistently positive predictor was topical interest. Those who started a community because of interest in a topic had more visitors, more contributors, and more subscribers than others. Interestingly, those motivated by self-promotion had more visitors, but fewer contributors and subscribers.
Goals had a less pronounced relationship with outcomes. Those with quality-oriented goals had more contributors but fewer visitors than those with quantity-oriented goals. There was no significant difference in subscribers for founders with different types of goals.
Finally, raising awareness was the strategy most associated with our success metrics, predicting all three of them. Surprisingly, encouraging contributions was associated with more contributors, but fewer visitors. While we don’t know the mechanism for sure, asking for contributions seems to provide a barrier that discourages newcomers from taking interest in a community.
So what?
We think that there are some key takeaways for platform designers and those starting new communities. Sanjay outlined many of them on the Reddit engineering blog, but I’ll recap a few.
First, topical knowledge and passion is important. This isn’t a causal study, so we don’t know the mechanisms for sure, but people who are passionate about a topic may be aware of other communities in the space and are able to find the right niche; they are also probably better at writing the kinds of welcome messages, initial posts, etc. that appeal to people interested in the topic.
Second, our work is yet more evidence that communities require different things at different points in their lifecycle. Founders should probably focus on building awareness at first, and worry less about encouraging contributions or regulating behavior.
Finally, we think there are a lot of opportunities for designers to take diverse motivations and goals seriously. This could include matching people by their motivations for using a community, developing dashboards that capture different aspects of success and community health and quality, etc.
Learn More
If you want to learn more about the paper, you have options!
If you’re at CHI, come to the talk. It will be at 9:45 in room 319 on Tuesday, May 14
Screenshot of the same rule, Neutral Point of View, on five different language editions. Notably, the pages are different because they exist as connected but ultimately separate pages.
While Wikipedia is famous for its encyclopedic content, it may be surprising to realize that a whole other set of pages on Wikipedia help guide and govern the creation of the peer-produced encyclopedia. These pages extensively describe processes, rules, principles, and technical features of creating, coordinating, and organizing on Wikipedia. Because of the success of Wikipedia, these pages have provided valuable insights into how platforms might decentralize and facilitate participation in online governance. However, each language edition of Wikipedia has a unique set of such pages governing it respectively, even though they are part of the same overarching project: in other words, an under-explored opportunity to understand how governance operates across diverse groups.
In a manuscript published at ICWSM2022, we present descriptive analyses examining on rules and rule-making across language editions of Wikipedia motivated by questions like:
What happens when communities are both relatively autonomous but within a shared system? Given that they’re aligned in key ways, how do their rules and rule-making develop over time? What can patterns in governance work tell us about how communities are converging or diverging over time?
We’ve been very fortunate to share this work with the Wikimedia community since publishing the paper, such as the Wikipedia Signpost and Wikimedia Research Showcase. At the end of last year, we published the replication data and files on Dataverse after addressing a data processing issue we caught earlier in the year (fortunately, it didn’t affect the results – but yet another reminder to quadruple-check one’s data pipeline!). In the spirit of sharing the work more broadly since the Dataverse release, we summarize some of the key aspects of the work here.
Study design
In the project, we examined the five largest language editions of Wikipedia as distinct editing communities: English, German, Spanish, French and Japanese. After manually constructing lists of rules per wiki (resulting in 780 pages), we took advantage of two features on Wikipedia: the revision histories, which log every edit to every page; and the interlanguage links, which connect conceptually equivalent pages across language editions. We then conducted a series of analyses examining comparisons across and relationships between language editions.
Shared patterns across communities
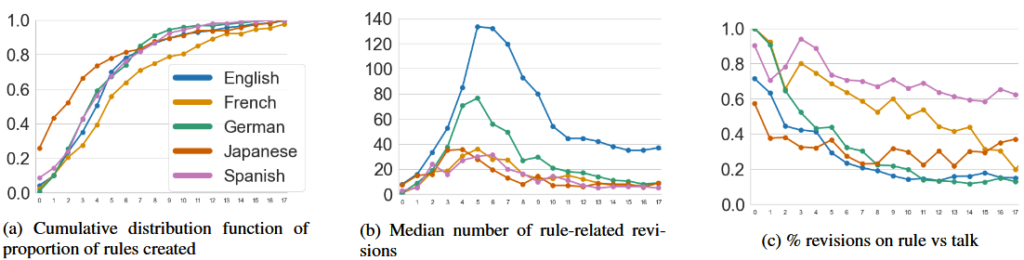
Across communities, we observed that trends suggested that rule-making often became less open over time:
Figure 2 from the ICWSM paper
Most rules are created early in the life of the language edition community’s life. Over a nearly 20 year period, roughly 50-80% of the rules (depending on the language edition) were created within the first five years!
The median edit count to rule pages peaked in early years (between years 3 and 5) before tapering down. The percent of revisions dedicated to editing the actual rule text versus discussing it shifts towards discussion of rule across communities. These both suggest that rules across communities have calcified over time.
Said simply, these communities have very similar trends in rule-making towards formalization.
Divergence vs convergence in rules
Wikipedia’s interlanguage link (ILL) feature, as mentioned above, lets us explore how the rules being created and edited on communities relate to one another. While the trends above highlight similarities in rule-making, here, the picture about how the rule sets are similar or not is a bit more complicated.
On one hand, the top panel here shows that over time, all five communities see an increase in the proportion of rules in their rules sets that are unique to them individually. On the other hand, the bottom panel shows that editing efforts concentrate on rules that are more shared across communities.
Altogether, we see that communities sharing goals, technology, and a lot more develop substantial and sustained institutional variations; but it’s possible that broad, widely-shared rules created early may help keep them relatively aligned.
Key takeaways
Investigating governance across groups like Wikipedia is valuable for at least two reasons.
First, an enormous amount of effort has gone into studying governance on English Wikipedia, the largest and oldest language edition, to distill lessons about how we can meaningfully decentralize governance in online spaces. But, as prior work [e.g., 1] shows, language editions are often non-aligned in both the content they produce and how they organize that content. Some early stage work we did noted this held true for rule pages on the five language editions of Wikipedia explored here. In recent years, the Wikimedia Foundation itself has made several calls to understand dynamics and patterns beyond English Wikipedia. This work is in part in response to this movement.
Second, the questions explored in our work highlight a key tension in online governance today. While online communities are relatively autonomous entities, they often exist within social and technical systems that put them in relation with one another – whether directly or not. Effectively addressing concerns about online governance means understanding how distinct spaces online govern in ways that are similar or dissimilar, overlap or conflict, diverge and converge. Wikipedia can offer many lessons to this end because it has an especially decentralized and participatory vision of how to govern itself online, such as how patterns of formalization impact success and engagement. Future work we are working on continues in this vein – stay tuned!
Although the world relies on free/libre open source software (FLOSS) for essential digital infrastructure such as the web and cloud, the software that supports that infrastructure are not always as high quality as we might hope, given our level of reliance on them. How can we find this misalignment of quality and importance (or underproduction) before it causes major failures?
How can we find misalignment of quality and importance (underproduction) before it causes major failures?
In previous work, we found that underproduction is widespread in packages maintained by the Debian community, and when we shared this work in the Debian and FLOSS community, developers suggested that the age and language of the packages might be a factor, and tech managers suggested looking at the teams doing the maintenance work. Software engineering literature had found some support for these suspicions as well, and we embarked on a study to dig deeper into some of the factors associated with underproduction.
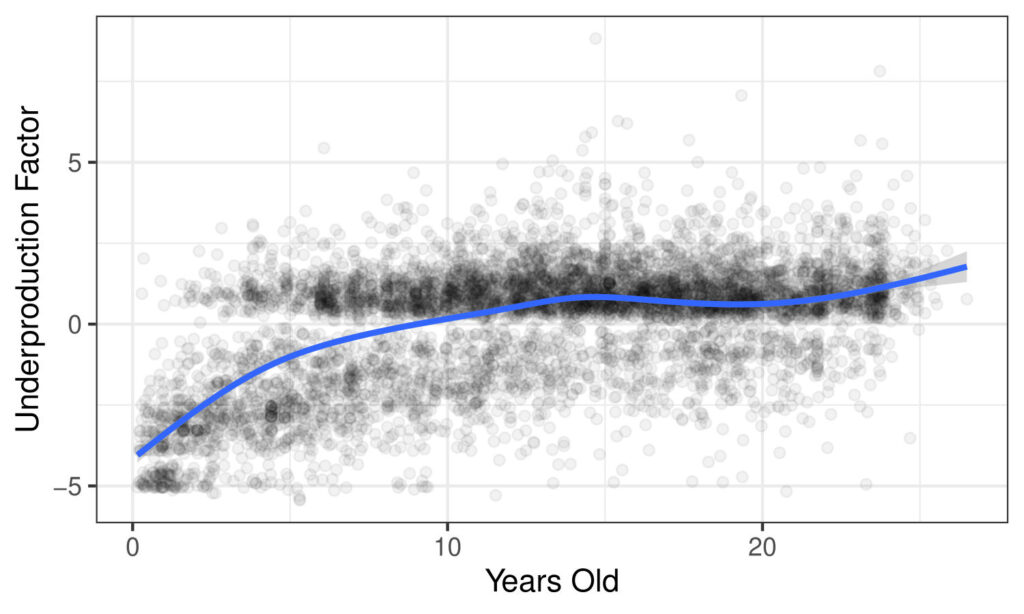
Our study was able to partially confirm this perspective using the underproduction analysis dataset from our previous study: software risk due to underproduction increases with age of both the package and its language, although many older packages and those written in older languages are and continue to be very well-maintained.
In this plot, dots represent software packages and their age, with higher underproduction factor indicating higher risk. The blue line is a smoothed average: note that we see an increase over time initially, but the trend flattens out for older packages.
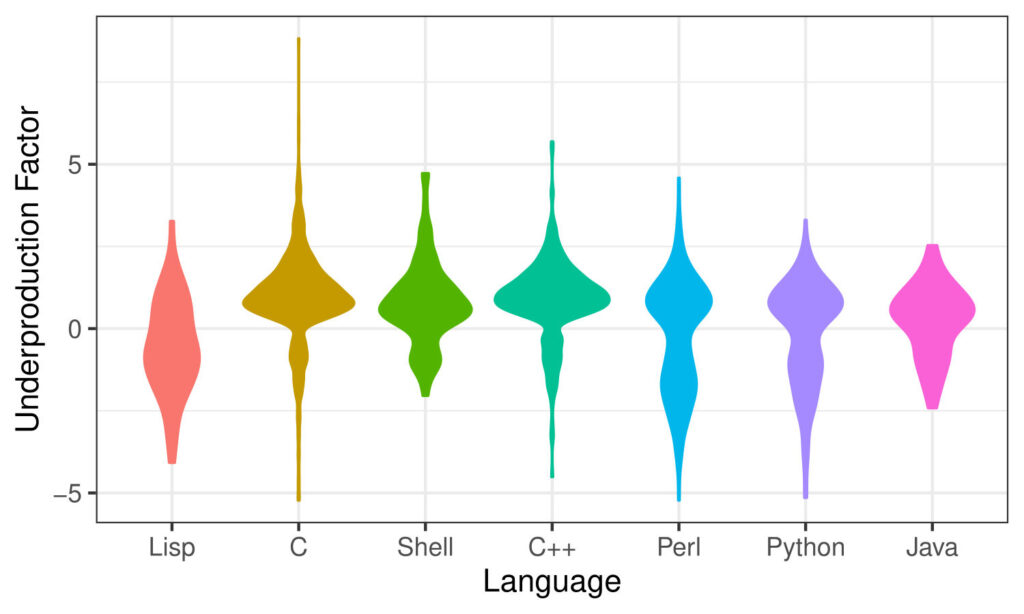
This plot shows the spread of the data across the range of underproduction factor, grouped by language, where higher values are indications of higher risk. Languages are sorted from oldest on the left (Lisp) to youngest on the right (Java). Although newer languages overall are associated with lower risk, we see a great deal of variation.
However, we found the resource question more complex: additional contributors were associated with higher risk instead of decreasing it as we hypothesized. We also found that underproduction is associated with higher eigenvector centrality in the network formed if we take packages as nodes and edges by having shared maintainers; that is, underproduced packages were likely to be maintained by the same people maintaining other parts of Debian, and not isolated efforts. This suggests that these high-risk packages are drawing from the same resource pool as those which are performing well. A lack of turnover in maintainership and being maintained by a team were not statistically significant once we included maintainer network structure and age in our model.
How should software communities respond? Underproduction appears in part to be associated with age, meaning that all communities sooner or later may need to confront it, and new projects should be thoughtful about using older languages. Distributions and upstream project developers are all part of the supply chain and have a role to play in the work of preventing and countering underproduction. Our findings about resources and organizational structure suggest that “more eyeballs” alone are not the answer: supporting key resources may be of particular value as a means to counter underproduction.
This work would not have been possible without the generosity of the Debian community. We are indebted to thesevolunteers who, in addition to producing Free/Libre Open Source Software software, have also made their records available to the public. We also gratefully acknowledge support from the Sloan Foundation through the Ford/Sloan DigitalInfrastructure Initiative, Sloan Award 2018-11356 as well as the National Science Foundation (Grant IIS-2045055). This work was conducted using the Hyak supercomputer at the UniversityofWashingtonaswellasresearchcomputing resources at Northwestern University.
What structure and rules are best for communities producing high-quality free/libre and open source software (FLOSS)? The stakes are high: cybersecurity researchers are raising the alarm about cybersecurity risk due to undermaintained components in the global software supply chain—much of which is FLOSS. In work that’s just been accepted to the IEEE International Conference on Software Analysis, Evolution and Reengineering (‘SANER’), we studied 182 Python-language packages in the GNU/Linux Debian distribution, examining the relationship between their levels of engineering formality and software risk. We found that more formal developer organization is associated with higher levels of software risk, and more widely spread developer responsibility is associated with lower levels of software risk.
We studied software risk through the underproduction metric initially developed by Champion and Hill (2021). Underproduction is a measurement of misalignment between the usage demands of a software project and the contributions of the project’s developer community. As such, underproduction measures the risk that software will be undermaintained, possibly including a security bug.
Our work examines the relationship between risk due to underproduction and governance formality. We employed measures initially developed by Tamburri et al. (2013) and later re-implemented in Tamburri et al. (2019). These metrics use multiple measures of software project formality — such as the average contributor type, usage of GitHub milestones, and age — to evaluate how formally structured a given project is.
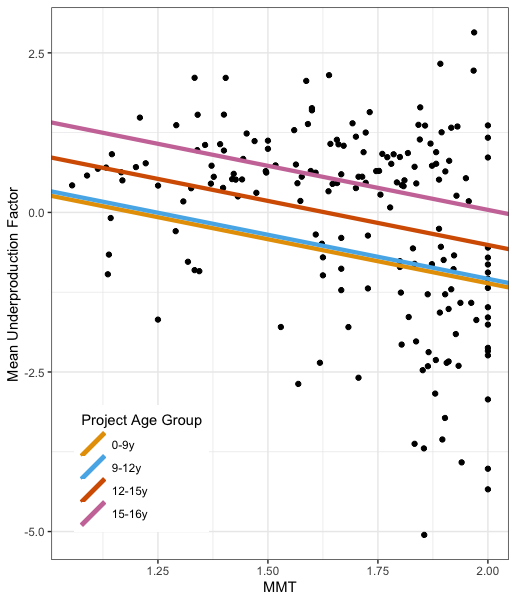
Plot of the relationship between mean underproduction factor and mean membership type (MMT), a metric encapsulating the diffusion of merge responsibility across a project’s developer community.
We used linear regression to conclude that more formal project structures are associated with higher levels of underproduction and thus, increased project risk. We also found that the share of community-members who have merged code into the main development branch is also related to underproduction, with lower levels of underproduction correlated with larger shares of community mergers.
Evaluated together, these two conclusions suggest that operating less formally and sharing power more equally is associated with lower underproduction risk. The development of FLOSS project engineering is a process laden with tradeoffs, we hope that our conclusions can help better inform community decision making and organization.
For more details, visualizations, statistics, and more, we hope you’ll take a look at our paper. If you are attending SANER in March 2024, we hope you’ll talk to us in Rovaniemi, Finland!
—————
The full citation for the paper is:
Gaughan, Matthew, Champion, Kaylea, and & Hwang, Sohyeon. (2024) “Engineering Formality and Software Risk in Debian Python Packages.” In 31st IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER2024) (Short Paper and Posters Track). Rovaniemi, Finland.
We have also released replication materials for the paper, including all the data and code used to conduct the analyses.
Wikipedia is one of the most visited websites in the world and the largest online repository of human knowledge. It is also both a target of and a defense against misinformation, disinformation, and other forms of online information manipulation. Importantly, its 300 language editions are self-governed—i.e., they set most of their rules and policies. Our new paper asks: What types of governance arrangements make some self-governed online groups more vulnerable to disinformation campaigns? We answer this question by comparing two Wikipedia language editions—Croatian and Serbian Wikipedia. Despite relying on common software and being situated in a common sociolinguistic environment, these communities differed in how successfully they responded to disinformation-related threats.
For nearly a decade, the Croatian language version of Wikipedia was run by a cabal of far-right nationalists who edited articles in ways that promoted fringe political ideas and involved cases of historical revisionism related to the Ustaše regime, a fascist movement that ruled the Nazi puppet state called the Independent State of Croatia during World War II. This cabal seized complete control of the governance of the encyclopedia, banned and blocked those who disagreed with them, and operated a network of fake accounts to give the appearance of grassroots support for their policies.
Thankfully, Croatian Wikipedia appears to be an outlier. Though both the Croatian and Serbian language editions have been documented to contain nationalist bias and historical revisionism, Croatian Wikipedia alone seems to have succumbed to governance capture: a takeover of the project’s mechanisms and institutions of governance by a small group of users.
The situation in Croatian Wikipedia was well-documented and is now largely fixed, but still know very little about why Croatian Wikipedia was taken over, while other language editions seem to have rebuffed similar capture attempts. In a new paper that is accepted for publication in the Proceedings of the ACM: Human-Computer Interaction (CSCW), we present an interview-based study that tries to explain why Croatian was captured while several other editions facing similar contexts and threats fared better.
Short video presentation of the work given at Wikimania in August 2023.
We interviewed 15 participants from both the Croatian and Serbian Wikipedia projects, as well as the broader Wikimedia movement. Based on insights from these interviews, we arrived at three propositions that, together, help explain why Croatian Wikipedia succumbed to capture while Serbian Wikipedia did not:
Perceived Value as a Target. Is the project worth expending the effort to capture?
Bureaucratic Openness. How easy is it for contributors outside the core founding team to ascend to local governance positions?
Institutional Formalization. To what degree does the project prefer personalistic, informal forms of organization over formal ones?
The conceptual model from our paper, visualizing possible institutional configurations among Wikipedia projects that affect the risk of governance capture.
We found that both Croatian Wikipedia and Serbian Wikipedia were attractive targets for far-right nationalist capture due to their sizable readership and resonance with a national identity. However, we also found that the two projects diverged early on in their trajectories in terms of how open they remained to new contributors ascending to local governance positions and the degree to which they privileged informal relationships over formal rules and processes as organizing principles of the project. Ultimately, Croatian’s relative lack of bureaucratic openness and rules constraining administrator behavior created a window of opportunity for a motivated contingent of editors to seize control of the governance mechanisms of the project.
Though our empirical setting was Wikipedia, our theoretical model may offer insight into the challenges faced by self-governed online communities more broadly. As interest in decentralized alternatives to Facebook and X (formerly Twitter) grows, communities on these sites will likely face similar threats from motivated actors. Understanding the vulnerabilities inherent in these self-governing systems is crucial to building resilient defenses against threats like disinformation.
For more details on our findings, take a look at the preprint of our paper.
Preprint on arxiv.org: https://arxiv.org/abs/2311.03616. The paper has been accepted for publication in Proceedings of the ACM on Human-Computer Interaction (CSCW) and will be presented at CSCW in 2024. This blog post and the paper it describes are collaborative work by Zarine Kharazian, Benjamin Mako Hill, and Kate Starbird.