Online communities have become ubiquitous, providing not only entertainment but wielding increasing cultural and political influence. While news organizations and researchers have focused a lot of attention on online communities after they become influential, very little is known about how or why they get started. Our survey of hundreds of Wikia.com founders shows that typical online communities are actually very different from the communities that are “in the news”. Online community founders have diverse motivations, but typically have modest goals which are focused on filling their own needs, and they don’t necessarily care if their projects ever get very big. Our research suggests that rather than being failures, small online communities are both intentional and common.
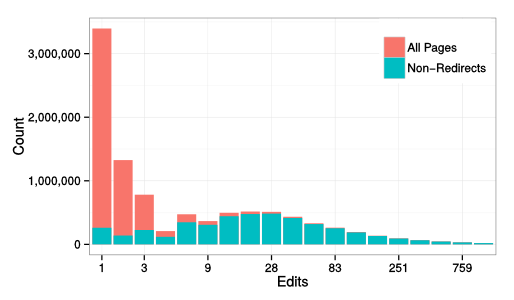
Most online communities are small —Our research is inspired by the skewed distribution of attention online. For example, these three graphs show the number of contributors to each subreddit, github project, and Wikipedia page. (Note the log scale – the reality is even more skewed than these plots make it appear).
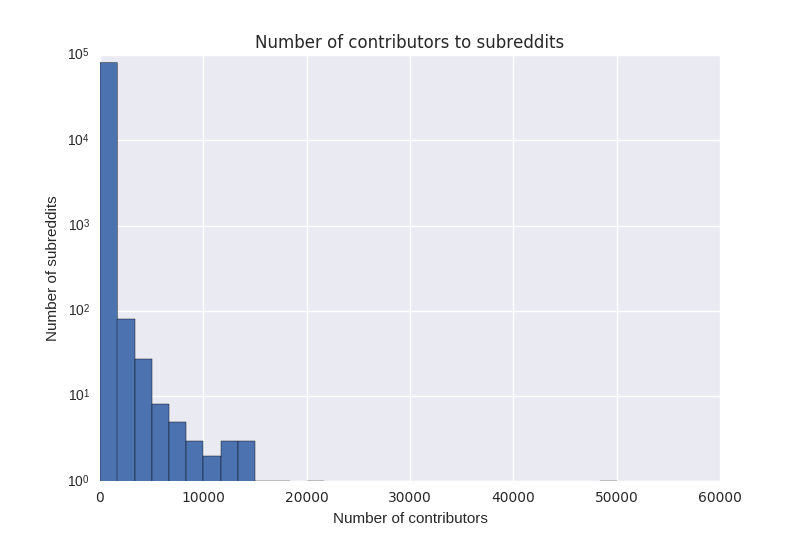
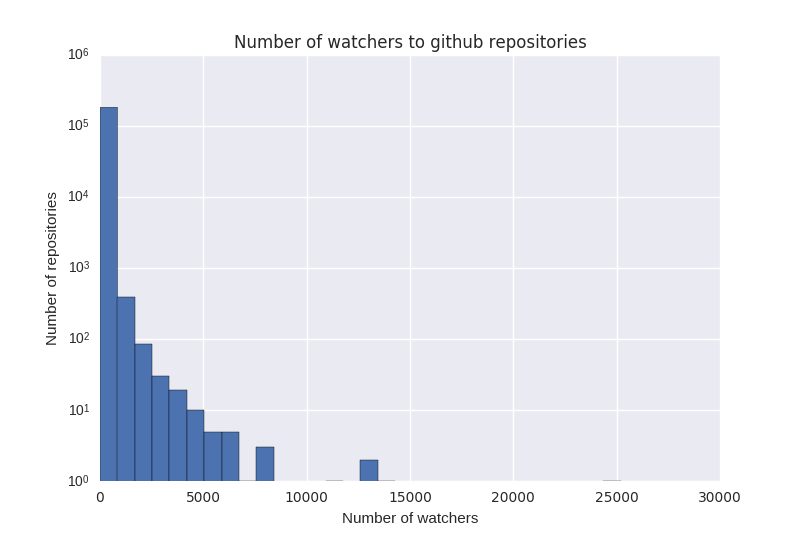
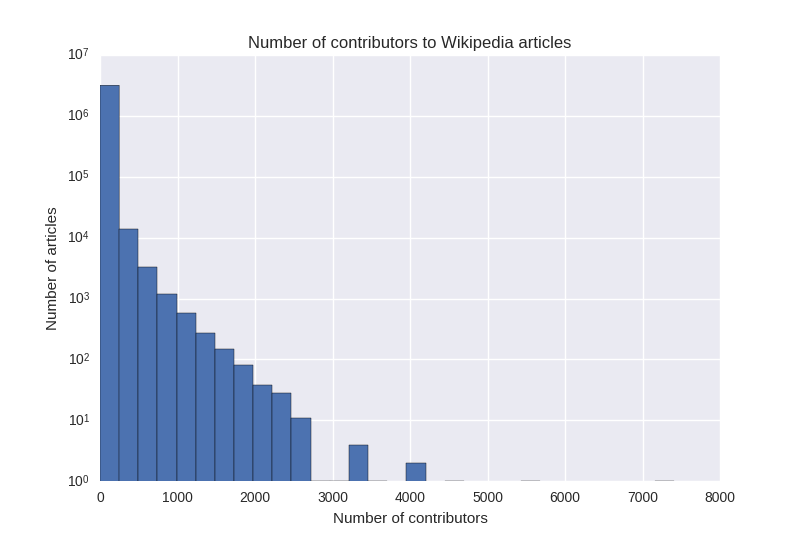 In every case, there is a “long tail” of projects with very few contributions or attention, while the most popular projects get the lion’s share. It is perhaps unsurprising, then, that they also garner the majority of scholarly attention. However, what these graphs also show is that most online communities are very small.
In every case, there is a “long tail” of projects with very few contributions or attention, while the most popular projects get the lion’s share. It is perhaps unsurprising, then, that they also garner the majority of scholarly attention. However, what these graphs also show is that most online communities are very small.
Even when scholars include smaller communities in their analysis, they typically treat longevity and size as measures of success. Using this metric, the vast majority of new projects fail. So why do people start new online communities? Are they simply naive, not realizing that large-scale success is so rare? Are community founders trying to win the attention lottery?
Our Survey —We worked with some great folks at Wikia to send a survey to community founders right after they started their community. We received partial or full responses from hundreds of founders.

In addition to demographic information, we asked a set of thirteen questions about the motivations of founders, based on the contributor motivation literature, and seven questions about their goals for their community. We also asked founders about their plans for their community, and whether they were planning to follow some of the best practices for building and running online communities.
Founders have diverse motivations and modest goals — We found that Wikia founders have diverse motivations. We used PCA to identify four main motivations for creating new wikis: spreading information and building a community, problems with existing wikis, for fun or learning, and creating and publicizing personal content. Spreading information and building a community was the most common motivation, but each of these was marked as a primary motivation by multiple respondents.
We also found that the barriers to starting a new community – both technological and cognitive – are very low. Only 32% of founders reported planning on starting their wiki for a few weeks or longer, while fully 46% of founders had only planned it for a few hours or a few minutes.
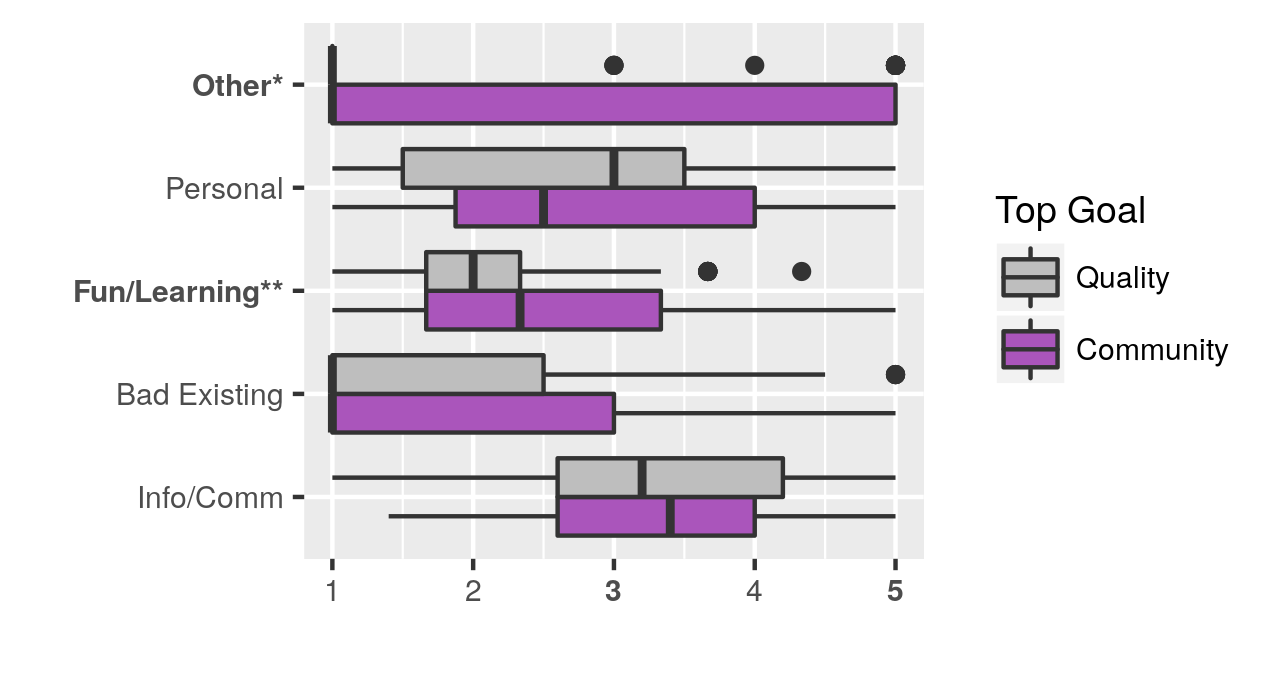
As with motivations, founders had diverse goals. The most common top goal was the creation of high-quality information, with nearly half of respondents selecting it. Community longevity/activity and growth were also common goals.
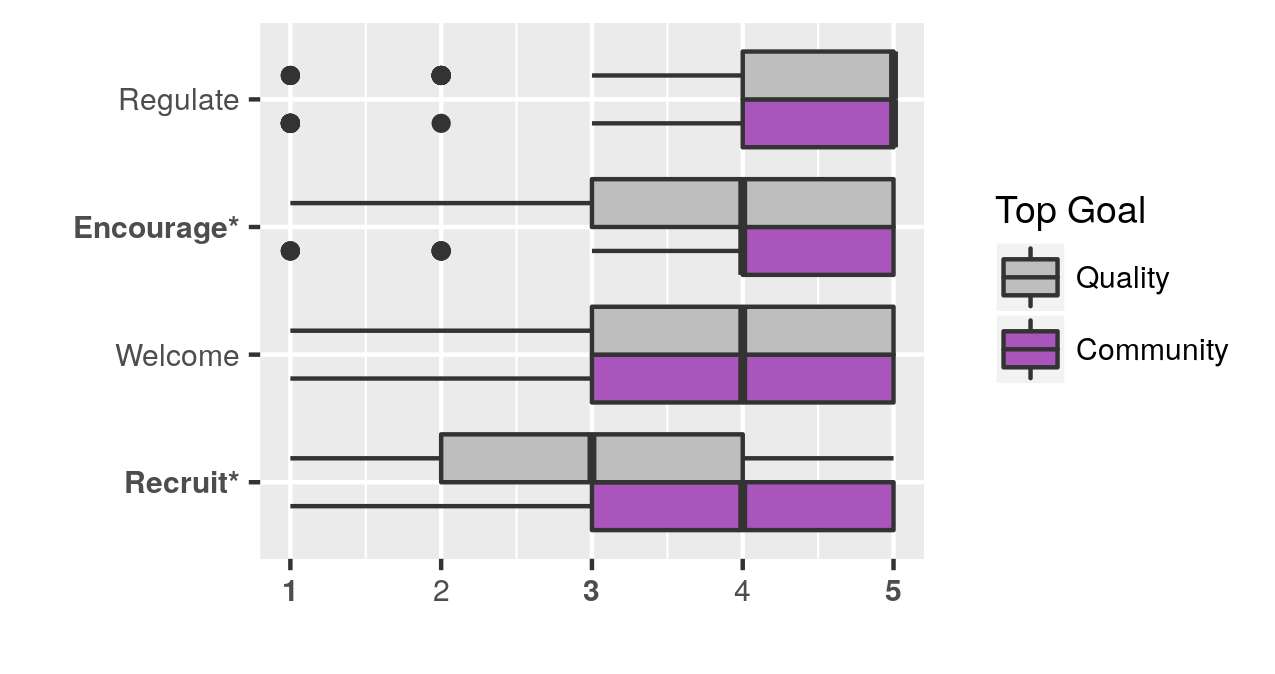
Finally, we looked at whether there was a relationship between motivations and goals, and between goals and plans for community building. We found that those whose top goal was information quality were less likely to be motivated by fun and learning, and that they were less likely to plan on recruiting contributors or encouraging contributions. In future research, we are looking at how a founder’s goals and plans relate to membership and contribution growth.
So what? —We believe that platform designers and researchers should focus more of their resources on understanding small and short-lived communities. Our research suggests that the attention paid to the more popular and long-lived online communities has perpetuated a false assumption that all communities seek to become large and powerful. Indeed, our respondents are typically not seeking or even hoping for large-scale “success”.
In addition, we believe that in many contexts, understanding online communities can be augmented by focusing on founders. Platform designers can study founders to understand how users would like to use a system and researchers can do more to understand the differences between founders and other contributors.
There is also a need to generalize this research – founders on other online platforms (Reddit, github, etc.) may have a different set of motivations and goals (although we suspect that they will be similarly modest in their ambitions). Overall, there is lots of room for additional research on how and why things get started online.
The paper and data — If you liked this blog post, then you’ll love the full paper: Starting online communities: Motivations and goals of wiki founders. Even better, if you are planning to be at CHI 2017, come watch the talk!
This post (and the paper) were written by Jeremy Foote, Aaron Shaw and Darren Gergle. The charts at the beginning of the post were created using data from the great public datasets at Big Query. Anonymized results of the survey are publicly available, and code is coming.