Although Wikipedia is the encyclopedia that anybody can edit, not all edits are welcome. Wikipedia is subject to a constant deluge of vandalism. Random people on the Internet are constantly “blanking” Wikipedia articles by deleting their content, replacing the text of articles with random characters, inserting outlandish claims or insults, and so on. Although volunteer editors and bots do an excellent job of quickly reverting the damage, the cost in terms of volunteer time is real.
Why do people spend their time and energy vandalizing web pages? For readers of Wikipedia that encounter a page that has been marred or replaced with nonsense or a slur—and especially for all the Wikipedia contributors who spend their time fighting back the tide of vandalism by checking and reverting bad edits and maintaining the bots and systems that keep order—it’s easy to dismiss vandals as incomprehensible sociopaths.
In a paper I just published in the ACM International Conference on Social Media and Society, I systematically analyzed a dataset of Wikipedia vandalism in an effort to identify different types of Wikipedia vandalism and to explain how each can been seen as “rational” from the point of view of the vandal.
Leveraging a dataset we created in some of our other work, the study used a random sample of contributions drawn from four groups that vary in the degree to the editors in question can be identified by others in Wikipedia: established users with accounts, users with accounts making their first edits, users without accounts, and users of the Tor privacy tool. Tor users were of particular interest to me because the use of Tor offers concrete evidence that a contributor is deliberately seeking privacy. I compared the frequency of vandalism in each group, developed an ontology to categorize it, and tested the relationship between group membership and different types of vandalism.
Vandalism in an University bathroom. [“Whiteboard Revisited.” Quinn Dombrowski. via flickr, CC BY-SA 2.0]
I found that the group that had engaged in the least effort in order to edit—users without accounts—were the most likely to vandalize. Although privacy-seeking Tor contributors were not the most likely to vandalize, vandalism from Tor-based contributors was less likely to be sociable, was more likely to be large scale (i.e. large blocks of text, such as by pasting in the same lines over and over), and more likely to express frustration with the Wikipedia community.
Thinking systematically about why different groups of users might engage in vandalism can help counter vandalism. Potential interventions might change not just the amount, but also the type, of vandalism a community will receive. Tools to detect vandalism may find that the patterns in each category allow for more accurate targeting. Ultimately, viewing vandals as more than irrational sociopaths opens potential avenues for dialogue.
Paper Citation: Kaylea Champion. 2020. “Characterizing Online Vandalism: A Rational Choice Perspective.” In International Conference on Social Media and Society (SMSociety’20). Association for Computing Machinery, New York, NY, USA, 47–57. https://doi.org/10.1145/3400806.3400813
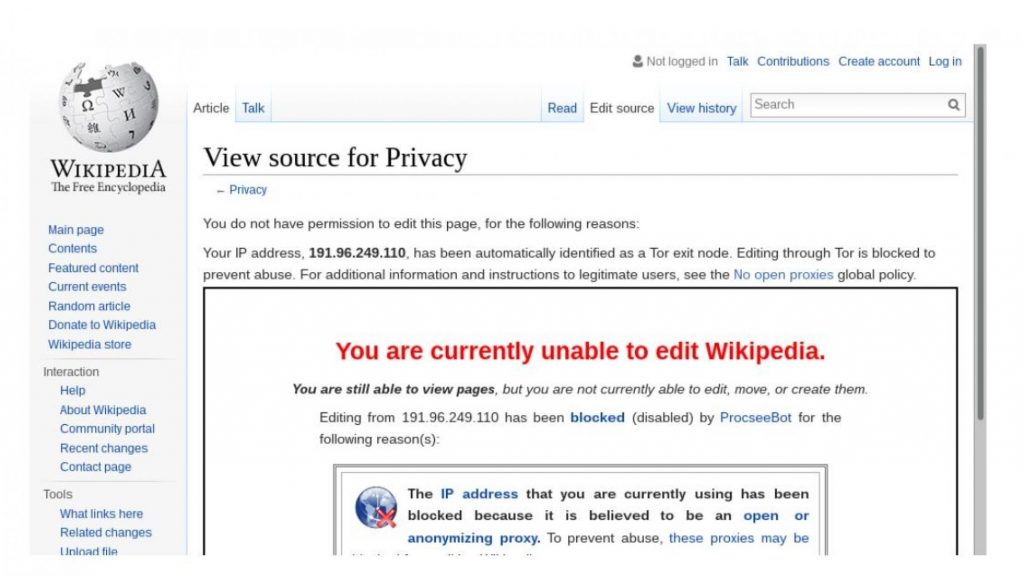
An image displaying the message that Tor users typically receive when trying to make edits on Wikipedia, stating that the user’s IP address has been identified as a Tor exit node, and that “editing through Tor is blocked to prevent abuse.”
Like everyone else, Internet users who protect their privacy by using the anonymous browsing software Tor are welcome to read Wikipedia. However, when Tor users try to contribute to the self-described “encyclopedia that anybody can edit,” they typically come face-to-face with a notice explaining that their participation is not welcome.
Our new paper—led by Chau Tran at NYU and authored by a group of researchers from the University of Washington, the Community Data Science Collective, Drexel, and New York University—was published and presented this week at the IEEE Symposium on Security & Privacy and provides insight into what Wikipedia might be missing out on by blocking Tor. By comparing contributions from Tor that slip past Wikipedia’s ban to edits made by other types of contributors, we find that Tor users make contributions to Wikipedia that are just as valuable as those made by new and unregistered Wikipedia editors. We also found that Tor users are more likely to engage with certain controversial topics.
One-minute “Trailer” for our paper and talk at the IEEE Symposium on Security & Privacy. Video was produced by Tommy Ferguson at the UW Department of Communication.
To conduct our study, we first identified more than 11,000 Wikipedia edits made by Tor users who were able to bypass Wikipedia’s ban on contributions from Tor between 2007 and 2018. We then used a series of quantitative techniques to evaluate the quality of these contributions. We found that Tor users made contributions that were similar in quality to, and in some senses even better than, contributions made by other users without accounts and newcomers making their first edits.
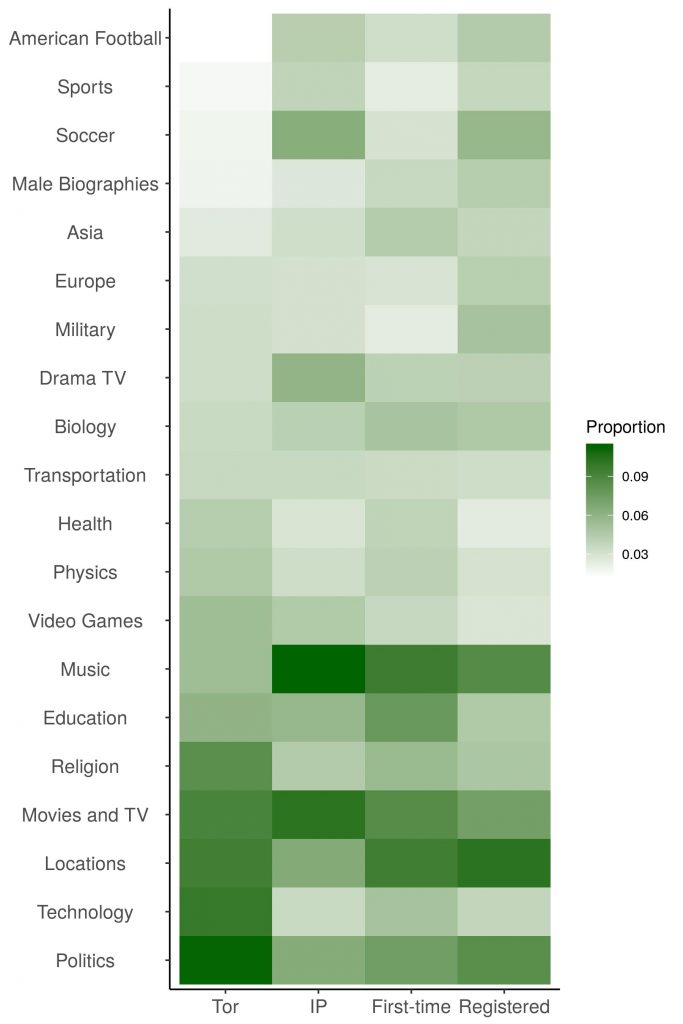
An image from the study showing the differences in topics edited by Tor users and other Wikipedia users. The image suggests that Tor users are more likely to edit pages discussing topics such as politics, religion, and technology. Other types of users, including IP, First-time, and Registered editors, are more likely to edit pages discussing topics such as music and sports.
We used a range of analytical techniques including direct parsing of article histories, manual inspections of article changes, and a machine learning platform called ORES to analyze contributions. We also used a machine learning technique called topic modeling to analyze Tor users’ areas of interest by checking their edits against clusters of keywords. We found that Tor-based editors are more likely than other users to focus on topics that may be considered controversial, such as politics, technology, and religion.
In a closely connected study led by Kaylea Champion and published several months ago in the Proceedings of the ACM on Human Computer Interaction (CSCW), we conducted a forensic qualitative analysis of contributions of the same dataset. Our results in that study are described in a separate blog post about that project and paint a complementary picture of Tor users engaged—in large part—in uncontroversial and quotidian types of editing behavior.
Across the two papers, our results are similar to other work that suggests that Tor users are very similar to other internet users. For example, one previous study has shown that Tor users frequently visit websites in the Alexa top one million.
Much of the discourse about anonymity online tends toward extreme claims backed up by very little in the way of empirical evidence or systematic study. Our work is a step toward remedying this gap and has implications for many websites that limit participation by users of anonymous browsing software like Tor. In the future, we hope to conduct similar systematic studies in contexts beyond Wikipedia.
Video of the conference presentation at the IEEE Symposium on Security & Privacy 2020 by Chau Tran.
In terms of Wikipedia’s own policy decisions about anonymous participation, we believe that our paper suggests that the benefits of a “pathway to legitimacy” for Tor contributors to Wikipedia might exceed the potential harm due to the value of their contributions. We are particularly excited about exploring ways to allow contributors from anonymity-seeking users under certain conditions: for example, requiring review prior to changes going live. Of course, these are questions for the Wikipedia community to decide but it’s a conversation that we hope our research can inform and that we look forward to participating in.
Paper Citation: Tran, Chau, Kaylea Champion, Andrea Forte, Benjamin Mako Hill, and Rachel Greenstadt. “Are Anonymity-Seekers Just like Everybody Else? An Analysis of Contributions to Wikipedia from Tor.” In 2020 IEEE Symposium on Security and Privacy (SP), 1:974–90. San Francisco, California: IEEE Computer Society, 2020. https://doi.org/10.1109/SP40000.2020.00053.
A paper recently published at CSCW describes the results of a forensic qualitative analysis of contributions made to Wikipedia through the anonymous browsing system Tor. The project was conducted collaboratively with researchers from Drexel, NYU, and the University of Washington and complements a quantitative analysis of the same data we also published to provide a rich qualitative picture of what anonymity-seekers are trying to do when they contribute to Wikipedia. The work also shows how the ability to stay anonymous can play a important role in facilitating certain types of contributions to online knowledge bases like Wikipedia.
Many individuals use Tor to reduce their visibility to widespread internet surveillance.
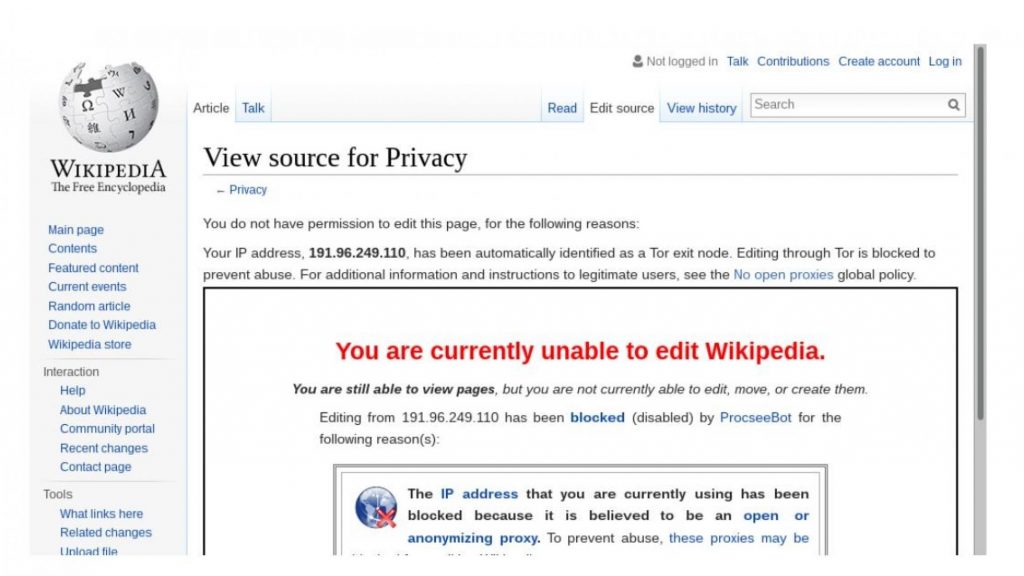
Media reports often describe how online platforms are tracking us. That said, trying to live our lives online without leaving a trail of our personal information can be difficult because many services can’t be used without an account and systems that protect privacy are often blocked. One popular approach to protecting our privacy online involves using the Tor network. Tor protects users from being identified by their IP address which can be tied to a physical location. However, if you’d like to contribute to Wikipedia using Tor, you’ll run into a problem. Although most IP addresses can edit without an account, Tor users are blocked from editing.
Tor users attempting to contributing to Wikipedia are shown a screen that informs them that they are not allowed to edit Wikipedia.
Other research by my team has shown that Wikipedia’s attempt to block Tor is imperfect and that some people have been able to edit despite the ban. This work also built a dataset of more than 11,000 contributions made to Wikipedia via Tor and used quantitative analysis to show that the contributions of people using Tor were about the same quality as contributions from other new editors and other contributors without accounts. Of course, given the unusual circumstances Tor-based contributors faced, we wondered if a deeper look into the content of their edits might tell us more about their motives and the kinds of contributions they seek to make. I led a qualitative investigation that sought to explore these questions.
Given the challenges of studying anonymity seekers, we designed a novel “forensic” qualitative approach that was inspired by the techniques common in the practice of computer security as well as criminal investigation. We applied to this new technique to a sample of 500 different editing sessions and sorted each session into a category based on what the editor seemed to be intending to do.
Most of the contributions we found fell into one of the two following categories:
Many contributions were quotidian attempts to add to the encyclopedia. Tor-based editors added facts, they fixed typos, and they updated train schedules. There’s no way to know if these individuals knew that they were just getting lucky in their ability to edit or if they were patiently reloading to evade the ban.
Second, we found harassing comments and vandalism. Unwelcome conduct is common in online environments, and sometimes more common when the likelihood of being identified is decreased. Some of the harassing comments we observed were direct responses to being banned as a Tor user.
Although these were most of what we observed, we also found evidence of several types of contributor intent:
We observed activism, as when a contributor tried to bring attention to journalistic accounts of environmental and human rights abuses being committed by a mining company, only to have editors traceable to the mining company repeatedly remove their edits. Another example included an editor trying to diminish the influence of alternative medicine proponents.
We also observed quality maintenance activities when editors used Wikipedia’s rules about appropriate sourcing to remove personal websites being cited in conspiracy theories.
We saw edit wars with Tor editors participating in a back-and-forth removal and replacement of content as part of a dispute, in some cases countering the work of an experienced Wikipedia editor who even other experienced editors had gauged to be biased.
Finally, we saw Tor-based editors participating in non-article discussions such as investigations of administrator misconduct, and protesting the mistrust of Tor editors by the Wikipedia platform.
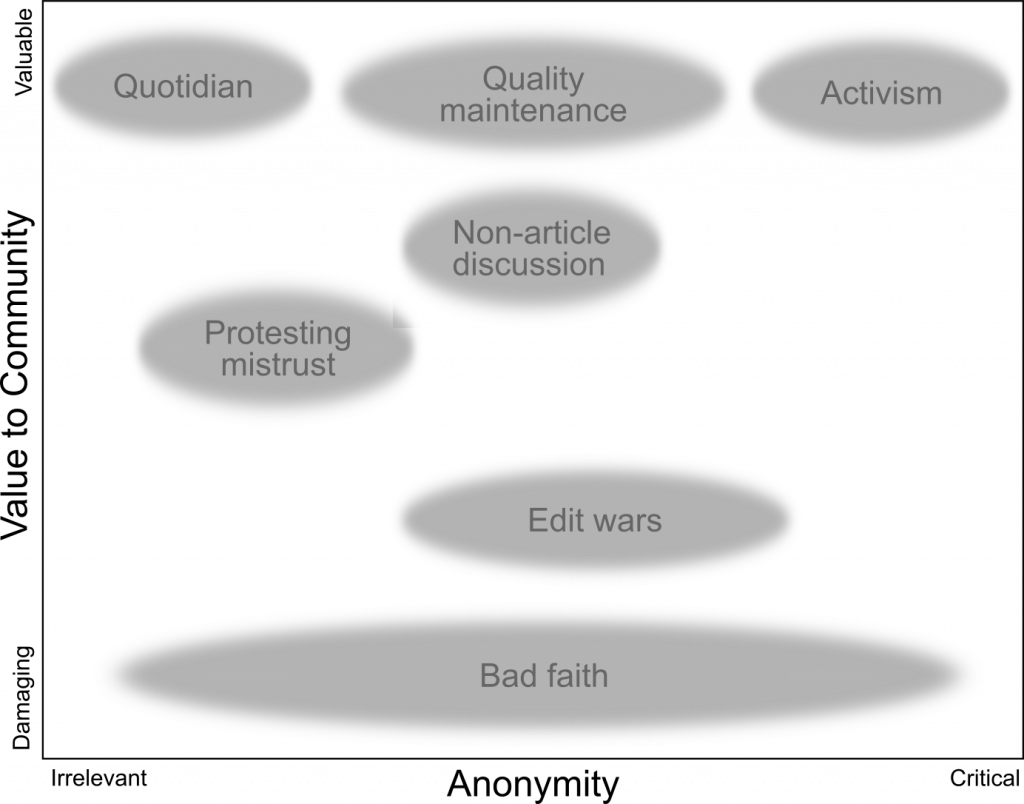
An exploratory mapping of our themes in terms of the value a type of contribution represents to the Wikipedia community and the importance of anonymity in facilitating it. Anonymity protecting tools play a critical role in facilitating contributions on the right side of the figure while edits on the left are more likely to occur even when anonymity is impossible. Contributions toward the top reflect valuable forms of participation in Wikipedia while edits on the bottom reflect damage.
In all, these themes led us to reflect on how the risks that individuals face when contributing to online communities are sometimes out of alignment with the risks the communities face by accepting their work. Expressing minoritized perspectives, maintaining community standards even when you may be targeted by the rulebreaker, highlighting injustice or acting as a whistleblower can be very risky for an individual, and may not be possible without privacy protections. Of course, in platforms seeking to support the public good, such knowledge and accountability may be crucial.
This project was conducted by Kaylea Champion, Nora McDonald, Stephanie Bankes, Joseph Zhang, Rachel Greenstadt, Andrea Forte, and Benjamin Mako Hill. This work was supported by the National Science Foundation (awards CNS-1703736 and CNS-1703049) and included the work of two undergraduates supported through an NSF REU supplement.
Paper Citation: Kaylea Champion, Nora McDonald, Stephanie Bankes, Joseph Zhang, Rachel Greenstadt, Andrea Forte, and Benjamin Mako Hill. 2019. A Forensic Qualitative Analysis of Contributions to Wikipedia from Anonymity Seeking Users. Proceedings of the ACM on Human-Computer Interactaction. 3, CSCW, Article 53 (November 2019), 26 pages. https://doi.org/10.1145/3359155
Do online communities compete with each other over resources or niches? Do they co-evolve in symbiotic or even parasitic relationships? What insights can we gain by applying ecological models of collective behavior to the study of collaborative online groups?
A colorful pisaster ochraceus (a.k.a., pisaster), a sea star species whose presence or absence can radically alter the ecology of an intertidal community. Our research will adapt theories created to explain the population dymamics of organisms like the pisaster in the context of online communities and human organizations (photo: Multi-Agency Rocky Intertidal Network).
We are delighted to announce that a Community Data Science Collective (CDSC) team led by Nate TeBlunthuis and Jeremy Foote has just started work on a three-year grant from the U.S. National Science Foundation to study the ecological dynamics of online communities! Aaron Shaw and Benjamin Mako Hill are principal investigators for the grant.
The projects supported by the award will extend the study of peer production and online communities by analyzing how aspects of communities’ environments impact their growth, patterns of participation, and survival. The work draws on recent research on various biological systems, organizational ecology, and human computer interaction (HCI). In general, we adapt these approaches to inform quantitative and computational analysis of populations of peer production communities and other online organizations.
As a major goal, we want to explain the conditions under which certain ecological dynamics emerge versus when they do not. For example, prior work has suggested that communities interact in ways that are both competitive and mutalistic. But what leads two communities to become competitors and others to benefit each other? We aim to understand when these patterns to arise. We are also interested in how community leaders might pursue effective strategies for survival given circumstances in the surrounding environment.
The grant promises to support a number of projects within the CDSC. Nate and Jeremy led the proposal writing as well as two key pilot studies that informed the development of the proposal. Other group members are now involved in planning and developing multiple studies under the grant.
The grant was awarded by the NSF Cyber-Human Systems (CHS) program within the Directorate for Information and Intellligent Systems (IIS) and the award is shared by Northwestern and the University of Washington (award numbers IIS-1910202 and IIS-1908850).
We’ve published the description of the proposal that we submitted to the NSF, although some details will shift as we carry out the project. The best place to stay up-to-date about the work will be to follow [the CDSC Twitter account (@ComDataSci)or the CDSC blog.
Introducing new technology into a work place is often disruptive, but what if your work was also completely mediated by technology? This is exactly the case for the teams of volunteer moderatorswho work to regulate content and protect online communities from harm. What happens when the social media platforms these communities rely on change completely? How do moderation teams overcome the challenges caused by new technological environments? How do they do so while managing a “brand new” community with tens of thousands of users?
For a new study that will be published in CSCW in November, we interviewed 14 moderators of 8 “subreddit” communities from the social media aggregation and discussion platform Reddit to answer these questions. We chose these communities because each community had recently adopted the real-time chat platform Discord to support real-time chat in their community. This expansion into Discord introduced a range of challenges—especially for the moderation teams of large communities.
We found that moderation teams of large communities improvised their own creative solutions to challenges they faced by building bots on top of Discord’s API. This was not too shocking given that APIs and bots are frequently cited as tools that allow innovation and experimentation when scaling up digital work. What did surprise us, however, was how important moderators’ past experiences were in guiding the way they used bots. In the largest communities that faced the biggest challenges, moderators relied on bots to reproduce the tools they had used on Reddit. The moderators would often go so far as to give their bots the names of moderator tools available on Reddit. Our findings suggest that support for user-driven innovation is important not only in that it allows users to explore new technological possibilities but also in that it allows users to mine their past experiences to introduce old systems into new environments.
What Challenges Emerged in Discord?
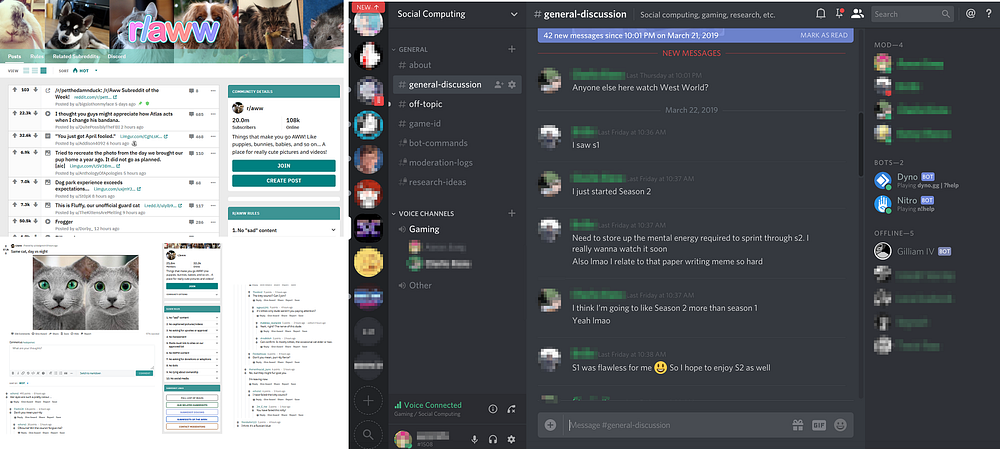
Left: A screenshot of the subreddit /r/aww. Right: A screenshot of a Discord server named “Social Computing”.
Discord’s text channels allow for more natural, in the moment conversations compared to Reddit. In Discord, this social aspect also made moderation work much more difficult. One moderator explained:
“It’s kind of rough because if you miss it, it’s really hard to go back to something that happened eight hours ago and the conversation moved on and be like ‘hey, don’t do that.’ ”
Moderators we spoke to found that the work of managing their communities was made even more difficult by their community’s size:
On the day to day of running 65,000 people, it’s literally like running a small city…We have people that are actively online and chatting that are larger than a city…So it’s like, that’s a lot to actually keep track of and run and manage.”
The moderators of large communities repeatedly told us that the tools provided to moderators on Discord were insufficient. For example, they pointed out tools like Discord’s Audit Log was inadequate for keeping track of the tens of thousands of members of their communities. Discord also lacks automated moderation tools like the Reddit’s Automoderator and Modmail leaving moderators on Discord with few tools to scale their work and manage communications with community members.
How Did Moderation Teams Overcome These Challenges?
The moderation teams we talked with adapted to these challenges through innovative uses of Discord’s API toolkit. Like many social media platforms, Discord offers a public API where users can develop apps that interact with the platform through a Discord “bot.” We found that these bots play a critical role in helping moderation teams manage Discord communities with large populations.
Guided by their experience with using tools like Automoderator on Reddit, moderators working on Discord built bots with similar functionality to solve the problems associated with scaled content and Discord’s fast-paced chat affordances. This bots would search for regular expressions and URLs that go against the community’s rules:
“It makes it so that rather than having to watch every single channel all of the time for this sort of thing or rely on users to tell us when someone is basically running amuck, posting derogatory terms and terrible things that Discord wouldn’t catch itself…so it makes it that we don’t have to watch every channel.”
Bots were also used to replace Discord’s Audit Log feature with what moderators referred to often as “Mod logs”—another term borrowed from Reddit. Moderators will send commands to a bot like “!warn username” to store information such as when a member of their community has been warned for breaking a rule and automatically store this information in a private text channel in Discord. This information helps organize information about community members, and it can be instantly recalled with another command to the bot to help inform future moderation actions against other community members.
Finally, moderators also used Discord’s API to develop bots that functioned virtually identically to Reddit’s Modmail tool. Moderators are limited in their availability to answer questions from members of their community, but tools like the “Modmail” helps moderation teams manage this problem by mediating communication to community members with a bot:
“So instead of having somebody DM a moderator specifically and then having to talk…indirectly with the team, a [text] channel is made for that specific question and everybody can see that and comment on that. And then whoever’s online responds to the community member through the bot, but everybody else is able to see what is being responded.”
The tools created with Discord’s API — customizable automated content moderation, Mod logs, and a Modmail system — all resembled moderation tools on Reddit. They even bear their names! Over and over, we found that moderation teams essentially created and used bots to transform aspects of Discord, like text channels into Mod logs and Mod Mail, to resemble the same tools they were using to moderate their communities on Reddit.
What Does This Mean for Online Communities?
We think that the experience of moderators we interviewed points to a potentially important underlooked source of value for groups navigating technological change: the potent combination of users’ past experience combined with their ability to redesign and reconfigure their technological environments. Our work suggests the value of innovation platforms like APIs and bots is not only that they allow the discovery of “new” things. Our work suggests that these systems value also flows from the fact that they allow the re-creation of the the things that communities already know can solve their problems and that they already know how to use.
Our work has several more specific takeaways as well. For moderators and community leaders:
Leaders of online communities planning to add an additional platform to host more discussion and social interactions for their community members should consider platforms with public APIs like Discord. You may run into challenges that the platform’s default tools are ineffective at solving, but public APIs allow for users to write software to solve their own problems.
For designers of online communities:
Designers of social media applications and platforms that host online communities should consider the effects of community growth and large population sizes on the work of moderation teams, who are often unpaid volunteers with limited time and resources to manage their communities.
Designers should also support a robust, public API for these applications and platforms. As our findings show, not every feature may be imagined in the creation of these platforms, but with a public API, users can drive the creation of custom solutions to unforeseen design problems. Our work suggests that these may be drawn from users unique knowledge of their problems as well as from their knowledge of existing solutions.
Paper Citation: Kiene, Charles, Jialun “Aaron” Jiang, and Benjamin Mako Hill. 2019. “Technological Frames and User Innovation: Exploring Technological Change in Community Moderation Teams.” Proceedings of the ACM: Human-Computer Interaction 3 (CSCW): 44:1-44:23.
Informal online learning communities are one of the most exciting and successful ways to engage young people in technology. As the most successful example of the approach, over 40 million children from around the world have created accounts on the Scratch online community where they learn to code by creating interactive art, games, and stories. However, despite its enormous reach and its focus on inclusiveness, participation in Scratch is not as broad as one would hope. For example, reflecting a trend in the broader computing community, more boys have signed up on the Scratch website than girls.
In a recently published paper, I worked with several colleagues from the Community Data Science Collective to unpack the dynamics of unequal participation by gender in Scratch by looking at whether Scratch users choose to share the projects they create. Our analysis took advantage of the fact that less than a third of projects created in Scratch are ever shared publicly. By never sharing, creators never open themselves to the benefits associated with interaction, feedback, socialization, and learning—all things that research has shown participation in Scratch can support.
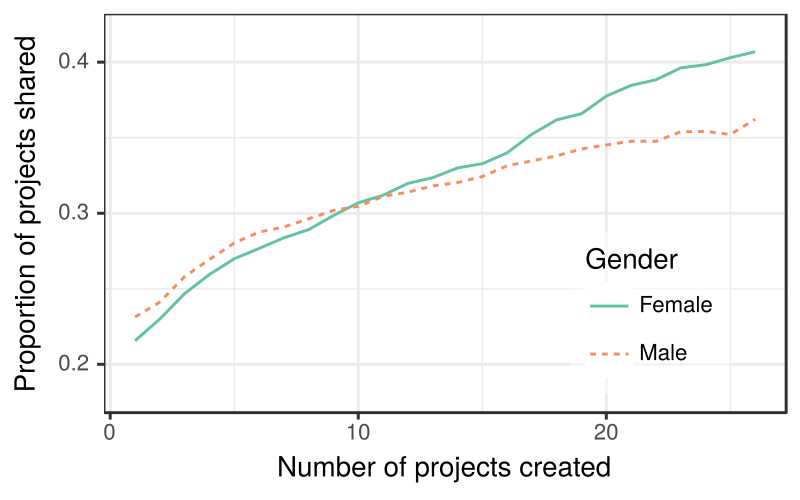
Overall, we found that boys on Scratch share their projects at a slightly higher rate than girls. Digging deeper, we found that this overall average hid an important dynamic that emerged over time. The graph below shows the proportion of Scratch projects shared for male and female Scratch users’ 1st created projects, 2nd created projects, 3rd created projects, and so on. It reflects the fact that although girls share less often initially, this trend flips over time. Experienced girls share much more than often than boys!
Proportion of projects shared by gender across experience levels, measured as the number of projects created, for 1.1 million Scratch users. Projects created by girls are less likely to be shared than those by boys until about the 9th project is created. The relationship is subsequently reversed.
We unpacked this dynamic using a series of statistical models estimated using data from over 5 million projects by over a million Scratch users. This set of analyses echoed our earlier preliminary finding—while girls were less likely to share initially, more experienced girls shared projects at consistently higher rates than boys. We further found that initial differences in sharing between boys and girls could be explained by controlling for differences in project complexity and in the social connectedness of the project creator.
Another surprising finding is that users who had received more positive peer feedback, at least as measured by receipt of “love its” (similar to “likes” on Facebook), were less likely to share their subsequent projects than users who had received less. This relation was especially strong for boys and for more experienced Scratch users. We speculate that this could be due to a phenomenon known in the music industry as “sophomore album syndrome” or “second album syndrome”—a term used to describe a musician who has had a successful first album but struggles to produce a second because of increased pressure and expectations caused by their previous success
Online anonymity often gets a bad rap and complaints about antisocial behavior from anonymous Internet users are as old as the Internet itself. On the other hand, research has shown that many Internet users seek out anonymity to protect their privacy while contributing things of value. Should people seeking to contribute to open collaboration projects like open source software and citizen science projects be required to give up identifying information in order to participate?
We conducted a two-part study to better understand how open collaboration projects balance the threats of bad behavior with the goal of respecting contributors’ expectations of privacy. First, we interviewed eleven people from five different open collaboration “service providers” to understand what threats they perceive to their projects’ mission and how these threats shape privacy and security decisions when it comes to anonymous contributions. Second, we analyzed discussions about anonymous contributors on publicly available logs of the English language Wikipedia mailing list from 2010 to 2017.
In the interview study, we identified three themes that pervaded discussions of perceived threats. These included threats to:
community norms, such as harrassment;
sustaining participation, such as loss of or failure to attract volunteers; and
contribution quality, low-quality contributions drain community resources.
We found that open collaboration providers were most concerned with lowering barriers to participation to attract new contributors. This makes sense given that newbies are the lifeblood of open collaboration communities. We also found that service providers thought of anonymous contributions as a way of offering low barriers to participation, not as a way of helping contributors manage their privacy. They imagined that anonymous contributors who wanted to remain in the community would eventually become full participants by registering for an account and creating an identity on the site. This assumption was evident in policies and technical features of collaboration platforms that barred anonymous contributors from participating in discussions, receiving customized suggestions, or from contributing at all in some circumstances. In our second study of the English language Wikipedia public email listserv, we discovered that the perspectives we encountered in interviews also dominated discussions of anonymity on Wikipedia. In both studies, we found that anonymous contributors were seen as “second-class citizens.”
This is not the way anonymous contributors see themselves. In a study we published two years ago, we interviewed people who sought out privacy when contributing to open collaboration projects. Our subjects expressed fears like being doxed, shot at, losing their job, or harassed. Some were worried about doing or viewing things online that violated censorship laws in their home country. The difference between the way that anonymity seekers see themselves and the way they are seen by service providers was striking.
One cause of this divergence in perceptions around anonymous contributors uncovered by our new paper is that people who seek out anonymity are not able to participate fully in the process of discussing and articulating norms and policies around anonymous contribution. People whose anonymity needs means they cannot participate in general cannot participate in the discussions that determine who can participate.
We conclude our paper with the observation that, although social norms have played an important role in HCI research, relying on them as a yardstick for measuring privacy expectations may leave out important minority experiences whose privacy concerns keep them from participating in the first place. In online communities like open collaboration projects, social norms may best reflect the most privileged and central users of a system while ignoring the most vulnerable
Both this blog post and the paper, Privacy, Anonymity, and Perceived Risk in Open Collaboration: A Study of Service Providers, was written by Nora McDonald, Benjamin Mako Hill, Rachel Greenstadt, and Andrea Forte and will be published in the Proceedings of the 2019 ACM CHI Conference on Human Factors in Computing Systems next week. The paper will be presented at the CHI conference in Glasgow, UK on Wednesday May 8, 2019. The work was supported by the National Science Foundation (awards CNS-1703736 and CNS-1703049).
Leaders and scholars of online communities tend of think of community growth as the aggregate effect of inexperienced individuals arriving one-by-one. However, there is increasing evidence that growth in many online communities today involves newcomers arriving in groups with previous experience together in other communities. This difference has deep implications for how we think about the process of integrating newcomers. Instead of focusing only on individual socialization into the group culture, we must also understand how to manage mergers of existing groups with distinct cultures. Unfortunately, online community mergers have, to our knowledge, never been studied systematically.
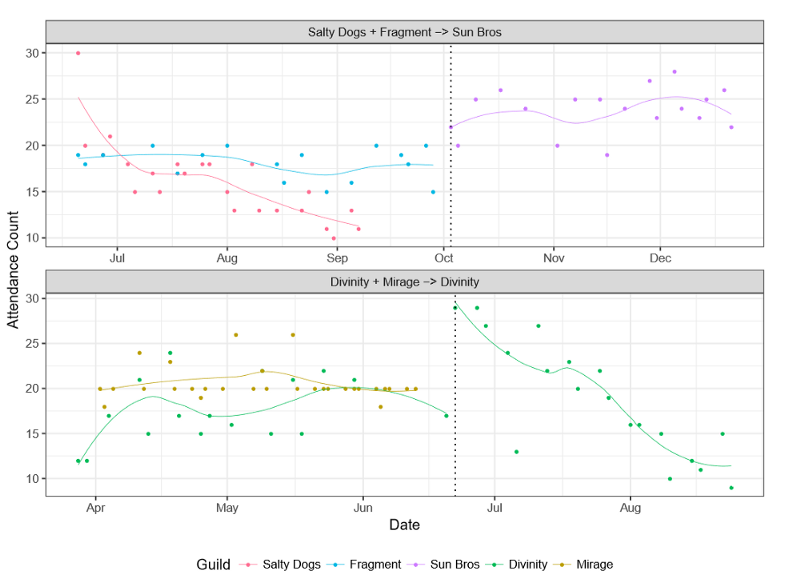
To better understand mergers, I spent six months in 2017 conducting ethnographic participant observation in two World of Warcraft raid guilds planning and undergoing mergers. The results—visible in the attendance plot below—shows that the top merger led to a thriving and sustainable community while the bottom merger led to failure and the eventual dissolution of the group. Why did one merger succeed while the other failed? What can managers of other communities learn from these examples?
In my new paper that will be published in the Proceedings of of the ACM Conference on Computer-supported Cooperative Work and Social Computing (CSCW) and that I will present in New Jersey next month, my coauthors and I try to answer these questions.
Raid team attendance before and after merging. Guilds were given pseudonyms to protect the identity of the research subjects.
In my research setting, World of Warcraft (WoW), players form organized groups called “guilds” to take on the game’s toughest bosses in virtual dungeons that are called “raids.” Raids can be extremely challenging, and they require a large number of players to be successful. Below is a video demonstrating the kind of communication and coordination needed to be successful as a raid team in WoW.
Because participation in a raid guild requires time, discipline, and emotional investment, raid guilds are constantly losing members and recruiting new ones to resupply their ranks. One common strategy for doing so is arranging formal mergers. My study involved following two such groups as they completed mergers. To collect data for my study, I joined both groups, attended and recorded all activities, took copious field notes, and spent hours interviewing leaders.
Although I did not anticipate the divergent outcomes shown in the figure above when I began, I analyzed my data with an eye toward identifying themes that might point to reasons for the success of one merger and the failure of the other. The answers that emerged from my analysis suggest that the key differences that led one merger to be successful and the other to fail revolved around differences in the ways that the two mergers managed organizational culture. This basic insight is supported by a body of research about organizational culture in firms but seem to have not made it onto the radar of most members or scholars of online communities. My coauthors and I think more attention to the role that organizational culture plays in online communities is essential.
We found evidence of cultural incompatibility in both mergers and it seems likely that some degree of cultural clashes is inevitable in any merger. The most important result of our analysis are three observations we drew about specific things that the successful merger did to effectively manage organizational culture. Drawn from our analysis, these themes point to concrete things that other communities facing mergers—either formal or informal—can do.
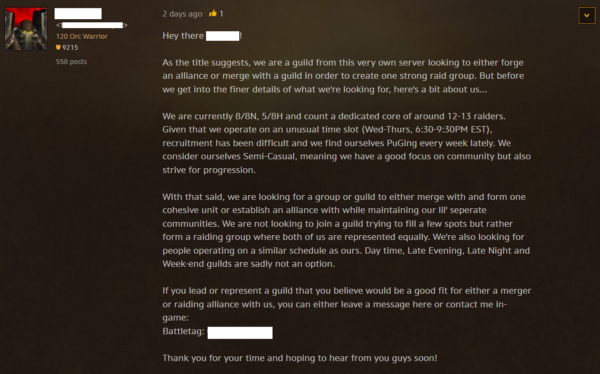
A recent, random example of a guild merger recruitment post found on the WoW forums.
First, when planning mergers, groups can strategically select other groups with similar organizational culture. The successful merger in our study involved a carefully planned process of advertising for a potential merger on forums, testing out group compatibility by participating in “trial” raid activities with potential guilds, and selecting the guild that most closely matched their own group’s culture. In our settings, this process helped prevent conflict from emerging and ensured that there was enough common ground to resolve it when it did.
Second, leaders can plan intentional opportunities to socialize members of the merged or acquired group. The leaders of the successful merger held community-wide social events in the game to help new members learn their community’s norms. They spelled out these norms in a visible list of rules. They even included the new members in both the brainstorming and voting process of changing the guild’s name to reflect that they were a single, new, cohesive unit. The leaders of the failed merger lacked any explicitly stated community rules, and opportunities for socializing the members of the new group were virtually absent. Newcomers from the merged group would only learn community norms when they broke one of the unstated social codes.
The guild leaders in the successful merger documented every successful high end raid boss achievement in a community-wide “Hall of Fame” journal. A screenshot is taken with every guild member who contributed to the achievement and uploaded to a “Hall of Fame” page.
Third and finally, our study suggested that social activities can be used to cultivate solidarity between the two merged groups, leading to increased retention of new members. We found that the successful guild merger organized an additional night of activity that was socially-oriented. In doing so, they provided a setting where solidarity between new and existing members can cultivate and motivate their members to stick around and keep playing with each other — even when it gets frustrating.
Our results suggest that by preparing in advance, ensuring some degree of cultural compatibility, and providing opportunities to socialize newcomers and cultivate solidarity, the potential for conflict resulting from mergers can be mitigated. While mergers between firms often occur to make more money or consolidate resources, the experience of the failed merger in our study shows that mergers between online communities put their entire communities at stake. We hope our work can be used by leaders in online communities to successfully manage potential conflict resulting from merging or acquiring members of other groups in a wide range of settings.
Much more detail is available our paper which will be published open access and which is currently available as a preprint.
Seymour Papert is credited as saying that tools to support learning should have “high ceilings” and “low floors.” The phrase is meant to suggest that tools should allow learners to do complex and intellectually sophisticated things but should also be easy to begin using quickly. Mitchel Resnick extended the metaphor to argue that learning toolkits should also have “wide walls” in that they should appeal to diverse groups of learners and allow for a broad variety of creative outcomes. In a new paper, Benjamin Mako Hill and I attempted to provide the first empirical test of Resnick’s wide walls theory. Using a natural experiment in the Scratch online community, we found causal evidence that “widening walls” can, as Resnick suggested, increase both engagement and learning.
Over the last ten years, the “wide walls” design principle has been widely cited in the design of new systems. For example, Resnick and his collaborators relied heavily on the principle in the design of the Scratch programming language. Scratch allows young learners to produce not only games, but also interactive art, music videos, greetings card, stories, and much more. As part of that team, I was guided by “wide walls” principle when I designed and implemented the Scratch cloud variables system in 2011-2012.
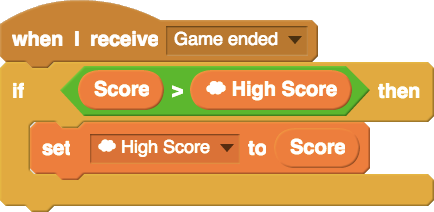
While designing the system, I hoped to “widen walls” by supporting a broader range of ways to use variables and data structures in Scratch. Scratch cloud variables extend the affordances of the normal Scratch variable by adding persistence and shared-ness. A simple example of something possible with cloud variables, but not without them, is a global high-score leaderboard in a game (example code is below). After the system was launched, I saw many young Scratch users using the system to engage with data structures in new and incredibly creative ways.
Example of Scratch code that uses a cloud variable to keep track of high-scores among all players of a game.
Although these examples reflected powerful anecdotal evidence, I was also interested in using quantitative data to reflect the causal effect of the system. Understanding the causal effect of a new design in real world settings is a major challenge. To do so, we took advantage of a “natural experiment” and some clever techniques from econometrics to measure how learners’ behavior changed when they were given access to a wider design space.
Understanding the design of our study requires understanding a little bit about how access to the Scratch cloud variable system is granted. Although the system has been accessible to Scratch users since 2013, new Scratch users do not get access immediately. They are granted access only after a certain amount of time and activity on the website (the specific criteria are not public). Our “experiment” involved a sudden change in policy that altered the criteria for who gets access to the cloud variable feature. Through no act of their own, more than 14,000 users were given access to feature, literally overnight. We looked at these Scratch users immediately before and after the policy change to estimate the effect of access to the broader design space that cloud variables afforded.
We found that use of data-related features was, as predicted, increased by both access to and use of cloud variables. We also found that this increase was not only an effect of projects that use cloud variables themselves. In other words, learners with access to cloud variables—and especially those who had used it—were more likely to use “plain-old” data-structures in their projects as well.
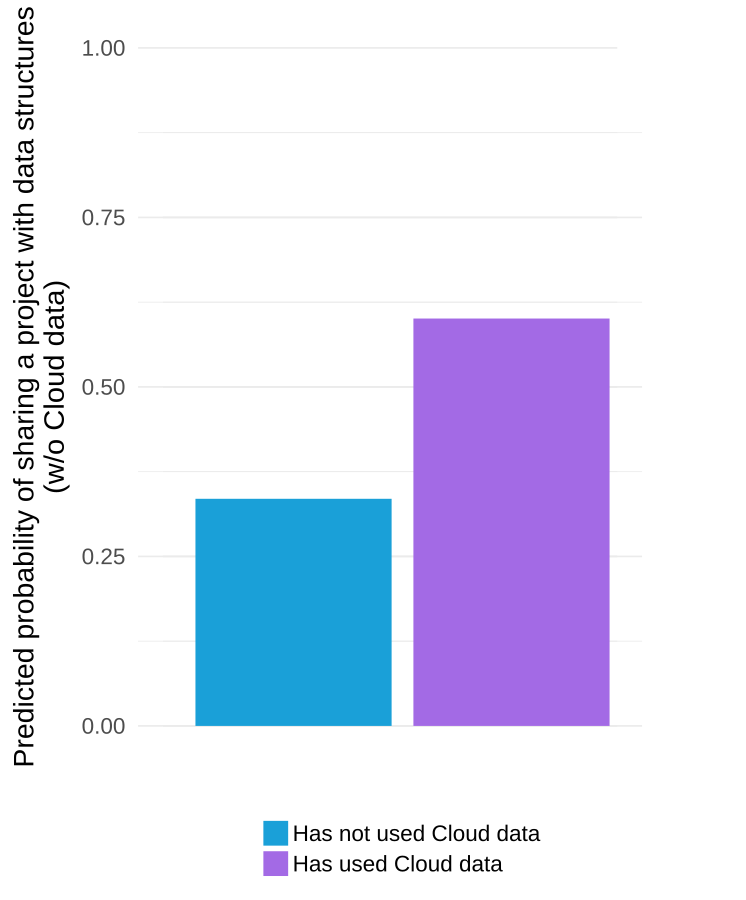
The graph below visualizes the results of one of the statistical models in our paper and suggests that we would expect that 33% of projects by a prototypical “average” Scratch user would use data structures if the user in question had never used used cloud variables but that we would expect that 60% of projects by a similar user would if they had used the system.
Model-predicted probability that a project made by a prototypical Scratch user will contain data structures (w/o counting projects with cloud variables)
It is important to note that the estimated effective above is a “local average effect” among people who used the system because they were granted access by the sudden change in policy (this is a subtle but important point that we explain this in some depth in the paper). Although we urge care and skepticism in interpreting our numbers, we believe our results are encouraging evidence in support of the “wide walls” design principle.
Of course, our work is not without important limitations. Critically, we also found that rate of adoption of cloud variables was very low. Although it is hard to pinpoint the exact reason for this from the data we observed, it has been suggested that widening walls may have a potential negative side-effect of making it harder for learners to imagine what the new creative possibilities might be in the absence of targeted support and scaffolding. Also important to remember is that our study measures “wide walls” in a specific way in a specific context and that it is hard to know how well our findings will generalize to other contexts and communities. We discuss these caveats, as well as our methods, models, and theoretical background in detail in our paper which now available for download as an open-access piece from the ACM digital library.
This blog post, and the open access paper that it describes, is a collaborative project with Benjamin Mako Hill. Financial support came from the eScience Institute and the Department of Communication at the University of Washington. Quantitative analyses for this project were completed using the Hyak high performance computing cluster at the University of Washington.
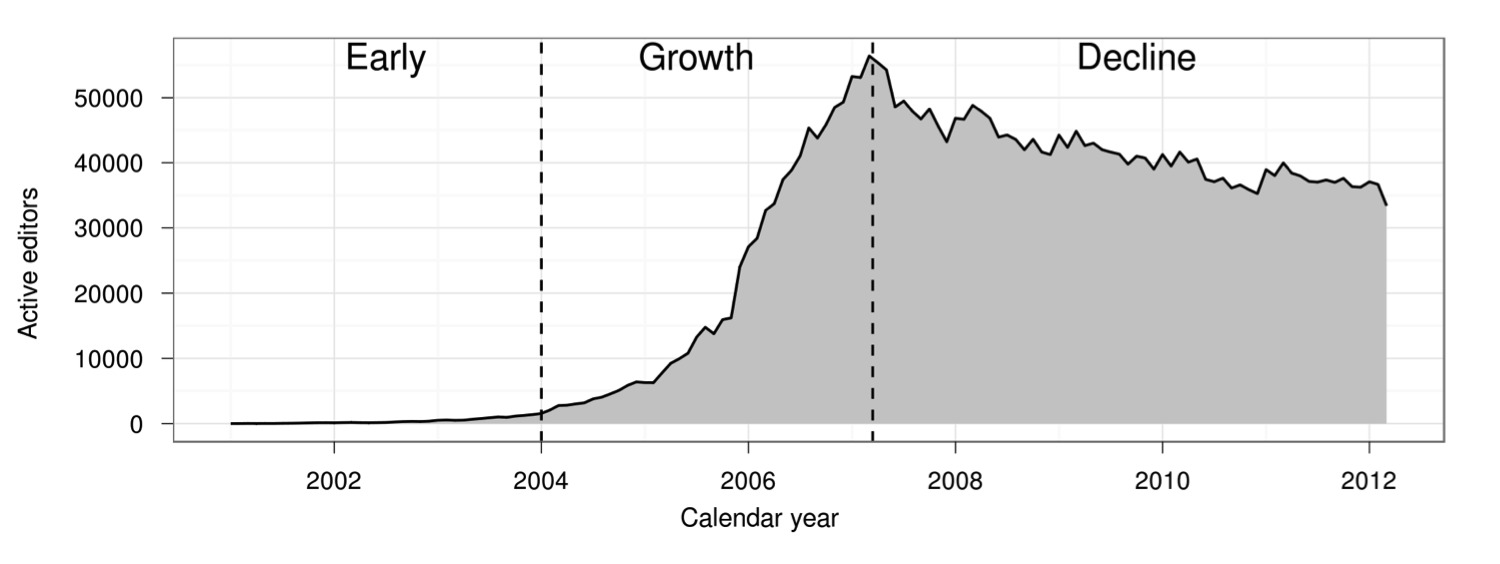
This graph shows the number of people contributing to Wikipedia over time:
The number of active Wikipedia contributors exploded, suddenly stalled, and then began gradually declining. (Figure taken from Halfaker et al. 2013)
The figure comes from “The Rise and Decline of an Open Collaboration System,” a well-known 2013 paper that argued that Wikipedia’s transition from rapid growth to slow decline in 2007 was driven by an increase in quality control systems. Although many people have treated the paper’s finding as representative of broader patterns in online communities, Wikipedia is a very unusual community in many respects. Do other online communities follow Wikipedia’s pattern of rise and decline? Does increased use of quality control systems coincide with community decline elsewhere?
In a paper I am presenting Thursday morning at the Association for Computing Machinery (ACM) Conference on Human Factors in Computing Systems (CHI), a group of us have replicated and extended the 2013 paper’s analysis in 769 other large wikis. We find that the dynamics observed in Wikipedia are a strikingly good description of the average Wikia wiki. They appear to reoccur again and again in many communities.
The original “Rise and Decline” paper (I’ll abbreviate it “RAD”) was written by Aaron Halfaker, R. Stuart Geiger, Jonathan T. Morgan, and John Riedl. They analyzed data from English Wikipedia and found that Wikipedia’s transition from rise to decline was accompanied by increasing rates of newcomer rejection as well as the growth of bots and algorithmic quality control tools. They also showed that newcomers whose contributions were rejected were less likely to continue editing and that community policies and norms became more difficult to change over time, especially for newer editors.
Our paper, just published in the CHI 2018 proceedings, replicates most of RAD’s analysis on a dataset of 769 of the largest wikis from Wikia that were active between 2002 to 2010. We find that RAD’s findings generalize to this large and diverse sample of communities.
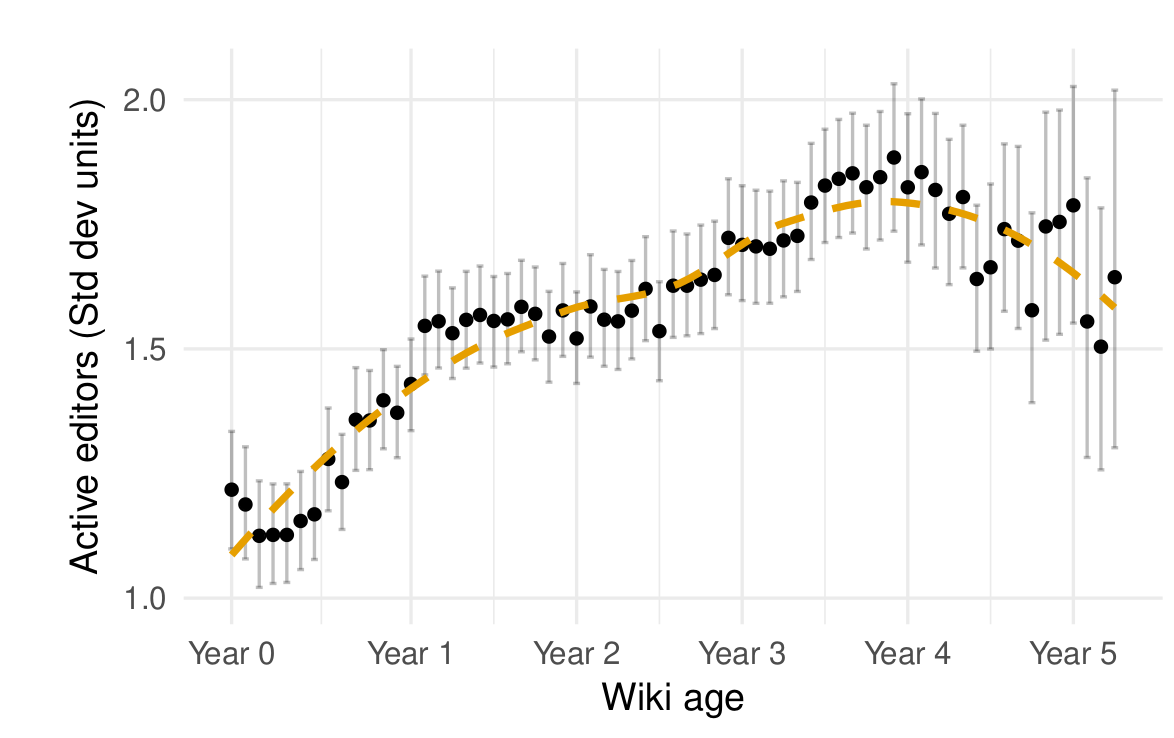
I can walk you through some of the key findings. First, the growth trajectory of the average wiki in our sample is similar to that of English Wikipedia. As shown in the figure below, an initial period of growth stabilizes and leads to decline several years later.
The average Wikia wikia also experience a period of growth followed by stabilization and decline (from TeBlunthuis, Shaw, and Hill 2018).
We also found that newcomers on Wikia wikis were reverted more and continued editing less. As on Wikipedia, the two processes were related. Similar to RAD, we also found that newer editors were more likely to have their contributions to the “project namespace” (where policy pages are located) undone as wikis got older. Indeed, the specific estimates from our statistical models are very similar to RAD’s for most of these findings!
There were some parts of the RAD analysis that we couldn’t reproduce in our context. For example, there are not enough bots or algorithmic editing tools in Wikia to support statistical claims about their effects on newcomers.
At the same time, we were able to do some things that the RAD authors could not. Most importantly, our findings discount some Wikipedia-specific explanations for a rise and decline. For example, English Wikipedia’s decline coincided with the rise of Facebook, smartphones, and other social media platforms. In theory, any of these factors could have caused the decline. Because the wikis in our sample experienced rises and declines at similar points in their life-cycle but at different points in time, the rise and decline findings we report seem unlikely to be caused by underlying temporal trends.
The big communities we study seem to have consistent “life cycles” where stabilization and/or decay follows an initial period of growth. The fact that the same kinds of patterns happen on English Wikipedia and other online groups implies a more general set of social dynamics at work that we do not think existing research (including ours) explains in a satisfying way. What drives the rise and decline of communities more generally? Our findings make it clear that this is a big, important question that deserves more attention.
We hope you’ll read the paper and get in touch by commenting on this post or emailing me if you’d like to learn or talk more. The paper is available online and has been published under an open access license. If you really want to get into the weeds of the analysis, we will soon publish all the data and code necessary to reproduce our work in a repository on the Harvard Dataverse.
I will be presenting the project this week at CHI in Montréal on Thursday April 26 at 9am in room 517D. For those of you not familiar with CHI, it is the top venue for Human-Computer Interaction. All CHI submissions go through double-blind peer review and the papers that make it into the proceedings are considered published (same as journal articles in most other scientific fields). Please feel free to cite our paper and send it around to your friends!
This blog post, and the open access paper that it describes, is a collaborative project with Aaron Shaw, and Benjamin Mako Hill. Financial support came from the US National Science Foundation (grants IIS-1617129, IIS-1617468, and GRFP-2016220885 ), Northwestern University, the Center for Advanced Study in the Behavioral Sciences at Stanford University, and the University of Washington. This project was completed using the Hyak high performance computing cluster at the University of Washington.