The ubiquity of large-scale data and improvements in computational hardware and algorithms have provided enabled researchers to apply computational approaches to the study of human behavior. One of the richest contexts for this kind of work is social media datasets like Facebook, Twitter, and Reddit.
We were invited by Jean Burgess, Alice Marwick, and Thomas Poell to write a chapter about computational methods for the Sage Handbook of Social Media. Rather than simply listing what sorts of computational research has been done with social media data, we decided to use the chapter to both introduce a few computational methods and to use those methods in order to analyze the field of social media research.
A “hairball” diagram from the chapter illustrating how research on social media clusters into distinct citation network neighborhoods.
Explanations and Examples
In the chapter, we start by describing the process of obtaining data from web APIs and use as a case study our process for obtaining bibliographic data about social media publications from Elsevier’s Scopus API. We follow this same strategy in discussing social network analysis, topic modeling, and prediction. For each, we discuss some of the benefits and drawbacks of the approach and then provide an example analysis using the bibliographic data.
We think that our analyses provide some interesting insight into the emerging field of social media research. For example, we found that social network analysis and computer science drove much of the early research, while recently consumer analysis and health research have become more prominent.
More importantly though, we hope that the chapter provides an accessible introduction to computational social science and encourages more social scientists to incorporate computational methods in their work, either by gaining computational skills themselves or by partnering with more technical colleagues. While there are dangers and downsides (some of which we discuss in the chapter), we see the use of computational tools as one of the most important and exciting developments in the social sciences.
Steal this paper!
One of the great benefits of computational methods is their transparency and their reproducibility. The entire process—from data collection to data processing to data analysis—can often be made accessible to others. This has both scientific benefits and pedagogical benefits.
To aid in the training of new computational social scientists, and as an example of the benefits of transparency, we worked to make our chapter pedagogically reproducible. We have created a permanent website for the chapter at https://communitydata.science/social-media-chapter/ and uploaded all the code, data, and material we used to produce the paper itself to an archive in the Harvard Dataverse.
Through our website, you can download all of the raw data that we used to create the paper, together with code and instructions for how to obtain, clean, process, and analyze the data. Our website walks through what we have found to be an efficient and useful workflow for doing computational research on large datasets. This workflow even includes the paper itself, which is written using LaTeX + knitr. These tools let changes to data or code propagate through the entire workflow and be reflected automatically in the paper itself.
If you use our chapter for teaching about computational methods—or if you find bugs or errors in our work—please let us know! We want this chapter to be a useful resource, will happily consider any changes, and have even created a git repository to help with managing these changes!
Millions of young people from around the world are learning to code. Often, during their learning experiences, these youth are using visual block-based programming languages like Scratch, App Inventor, and Code.org Studio. In block-based programming languages, coders manipulate visual, snap-together blocks that represent code constructs instead of textual symbols and commands that are found in more traditional programming languages.
The textual symbols used in nearly all non-block-based programming languages are drawn from English—consider “if” statements and “for” loops for common examples. Keywords in block-based languages, on the other hand, are often translated into different human languages. For example, depending on the language preference of the user, an identical set of computing instructions in Scratch can be represented in many different human languages:
Although my research with Benjamin Mako Hill focuses on learning, both Mako and I worked on local language technologies before coming back to academia. As a result, we were both interested in how the increasing translation of programming languages might be making it easier for non-English speaking kids to learn to code.
After all, a large body of education research has shown that early-stage education is more effective when instruction is in the language that the learner speaks at home. Based on this research, we hypothesized that children learning to code with block-based programming languages translated to their mother-tongues will have better learning outcomes than children using the blocks in English.
We sought to test this hypothesis in Scratch, an informal learning community built around a block-based programming language. We were helped by the fact that Scratch is translated into many languages and has a large number of learners from around the world.
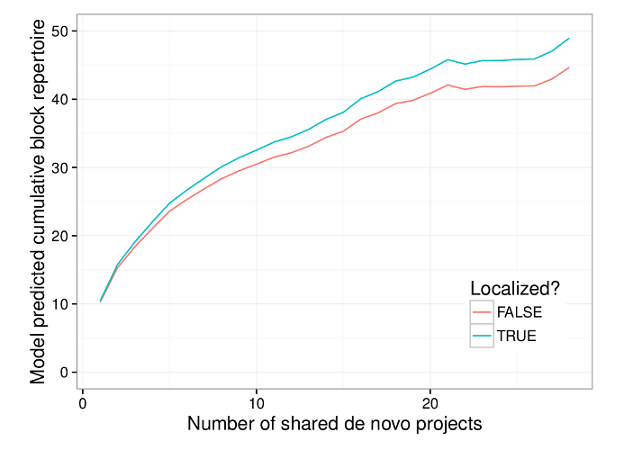
To measure learning, we built on some of our our own previous work and looked at learners’ cumulative block repertoires—similar to a code vocabulary. By observing a learner’s cumulative block repertoire over time, we can measure how quickly their code vocabulary is growing.
Using this data, we compared the rate of growth of cumulative block repertoire between learners from non-English speaking countries using Scratch in English to learners from the same countries using Scratch in their local language. To identify non-English speakers, we considered Scratch users who reported themselves as coming from five primarily non-English speaking countries: Portugal, Italy, Brazil, Germany, and Norway. We chose these five countries because they each have one very widely spoken language that is not English and because Scratch is almost fully translated into that language.
Even after controlling for a number of factors like social engagement on the Scratch website, user productivity, and time spent on projects, we found that learners from these countries who use Scratch in their local language have a higher rate of cumulative block repertoire growth than their counterparts using Scratch in English. This faster growth was despite having a lower initial block repertoire. The graph below visualizes our results for two “prototypical” learners who start with the same initial block repertoire: one learner who uses the English interface, and a second learner who uses their native language.
Our results are in line with what theories of education have to say about learning in one’s own language. Our findings also represent good news for designers of block-based programming languages who have spent considerable amounts of effort in making their programming languages translatable. It’s also good news for the volunteers who have spent many hours translating blocks and user interfaces.
Although we find support for our hypothesis, we should stress that our findings are both limited and incomplete. For example, because we focus on estimating the differences between Scratch learners, our comparisons are between kids who all managed to successfully use Scratch. Before Scratch was translated, kids with little working knowledge of English or the Latin script might not have been able to use Scratch at all. Because of translation, many of these children are now able to learn to code.
This blog-post and the work that it describes is a collaborative project with Benjamin Mako Hill. You can read our paper here. The paper was published in the ACM Learning @ Scale Conference. We also recently gave a talk about this work at the International Communication Association’s annual conference. We have received support and feedback from members of the Scratch team at MIT (especially Mitch Resnick and Natalie Rusk), as well as from Nathan TeBlunthuis at the University of Washington. Financial support came from the US National Science Foundation.
I recently finished a paper that presents a novel social computing system called the Wikipedia Adventure. The system was a gamified tutorial for new Wikipedia editors. Working with the tutorial creators, we conducted both a survey of its users and a randomized field experiment testing its effectiveness in encouraging subsequent contributions. We found that although users loved it, it did not affect subsequent participation rates.
Start screen for the Wikipedia Adventure.
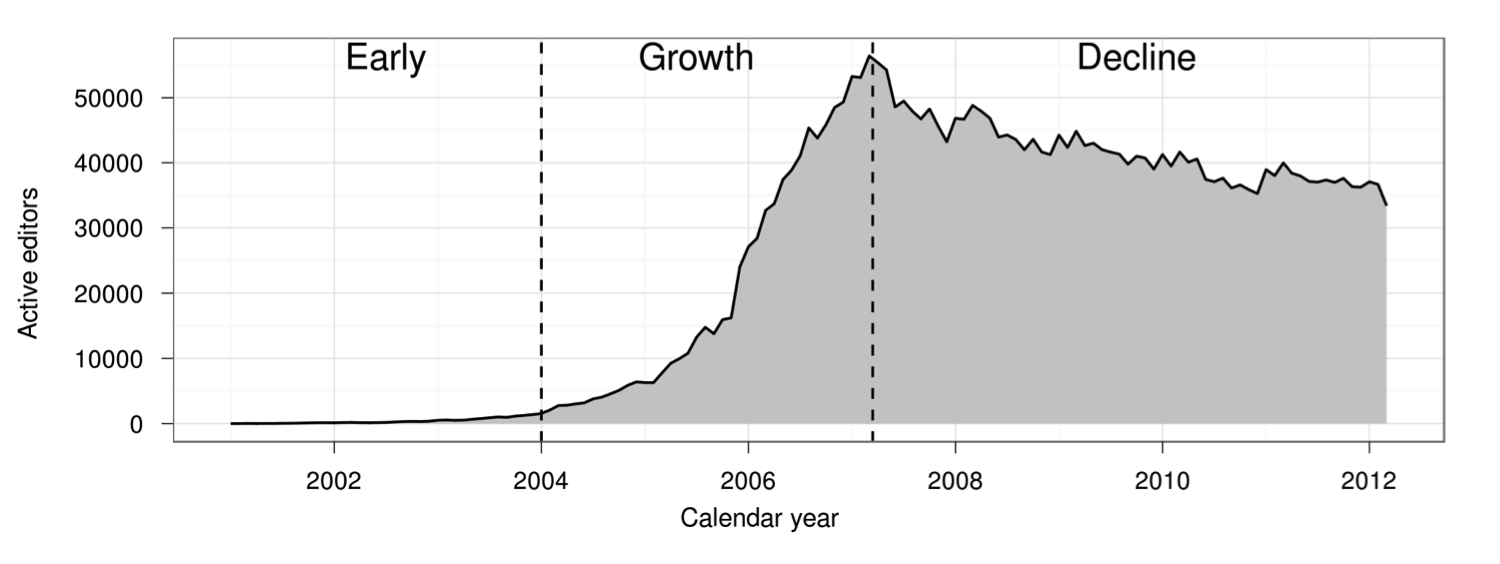
A major concern that many online communities face is how to attract and retain new contributors. Despite it’s success, Wikipedia is no different. In fact, researchers have shown that after experiencing a massive initial surge in activity, the number of active editors on Wikipedia has been in slow decline since 2007.
Research has attributed a large part of this decline to the hostile environment that newcomers experience when begin contributing. New editors often attempt to make contributions which are subsequently reverted by more experienced editors for not following Wikipedia’s increasingly long list of rules and guidelines for effective participation.
This problem has led many researchers and Wikipedians to wonder how to more effectively onboard newcomers to the community. How do you ensure that new editors Wikipedia quickly gain the knowledge they need in order to make contributions that are in line with community norms?
To this end, Jake Orlowitz and Jonathan Morgan from the Wikimedia Foundation worked with a team of Wikipedians to create a structured, interactive tutorial called The Wikipedia Adventure. The idea behind this system was that new editors would be invited to use it shortly after creating a new account on Wikipedia, and it would provide a step-by-step overview of the basics of editing.
The Wikipedia Adventure was designed to address issues that new editors frequently encountered while learning how to contribute to Wikipedia. It is structured into different ‘missions’ that guide users through various aspects of participation on Wikipedia, including how to communicate with other editors, how to cite sources, and how to ensure that edits present a neutral point of view. The sequence of the missions gives newbies an overview of what they need to know instead of having to figure everything out themselves. Additionally, the theme and tone of the tutorial sought to engage new users, rather than just redirecting them to the troves of policy pages.
Those who play the tutorial receive automated badges on their user page for every mission they complete. This signals to veteran editors that the user is acting in good-faith by attempting to learn the norms of Wikipedia.
An example of a badge that a user receives after demonstrating the skills to communicate with other users on Wikipedia.
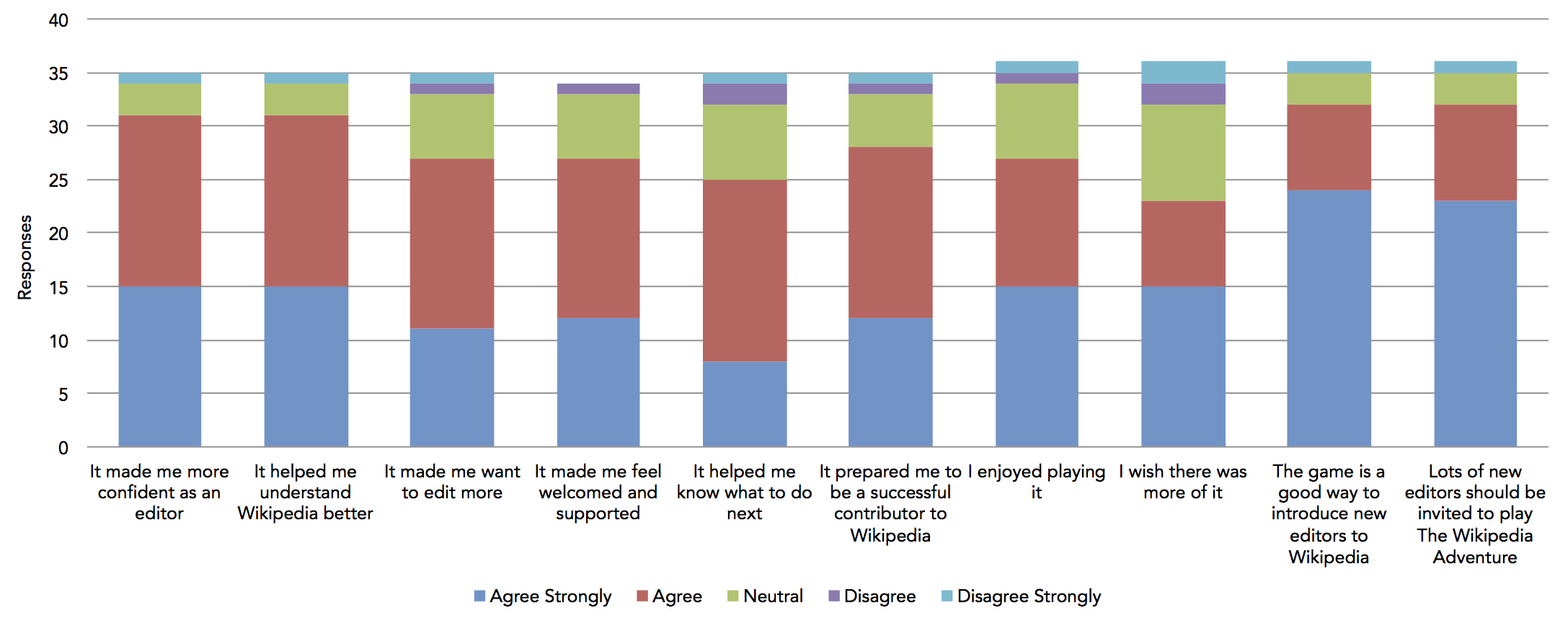
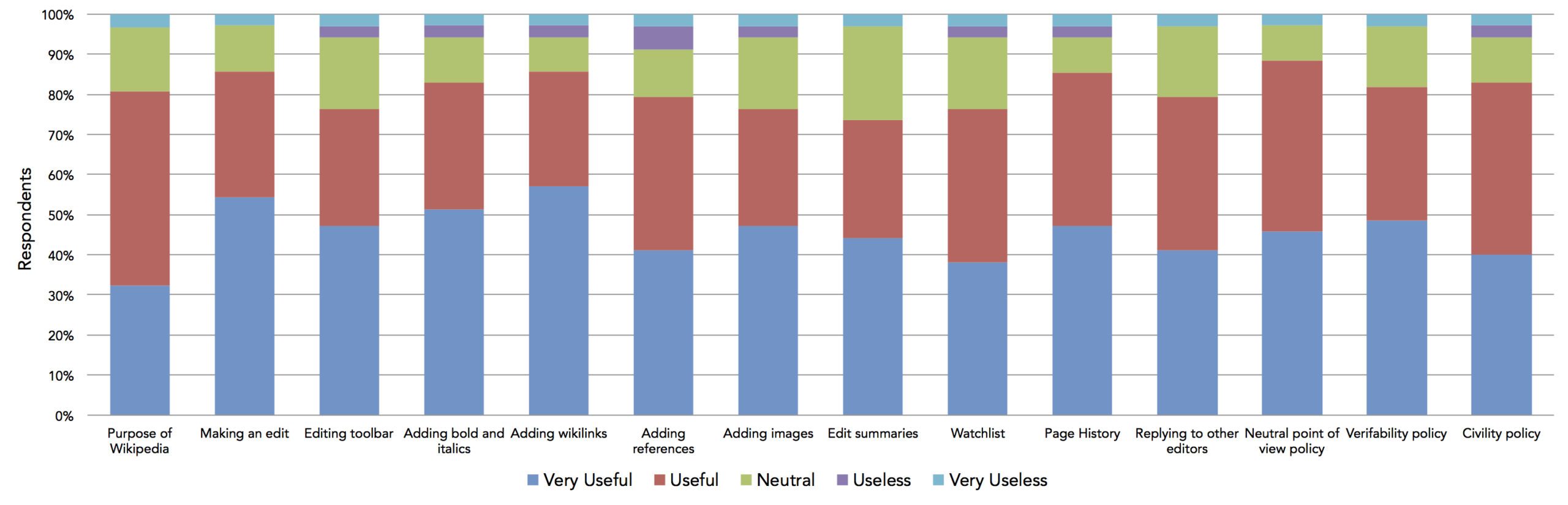
Once the system was built, we were interested in knowing whether people enjoyed using it and found it helpful. So we conducted a survey asking editors who played the Wikipedia Adventure a number of questions about its design and educational effectiveness. Overall, we found that users had a very favorable opinion of the system and found it useful.
Survey responses about how users felt about TWA.
Survey responses about what users learned through TWA.
We were heartened by these results. We’d sought to build an orientation system that was engaging and educational, and our survey responses suggested that we succeeded on that front. This led us to ask the question – could an intervention like the Wikipedia Adventure help reverse the trend of a declining editor base on Wikipedia? In particular, would exposing new editors to the Wikipedia Adventure lead them to make more contributions to the community?
To find out, we conducted a field experiment on a population of new editors on Wikipedia. We identified 1,967 newly created accounts that passed a basic test of making good-faith edits. We then randomly invited 1,751 of these users via their talk page to play the Wikipedia Adventure. The rest were sent no invitation. Out of those who were invited, 386 completed at least some portion of the tutorial.
We were interested in knowing whether those we invited to play the tutorial (our treatment group) and those we didn’t (our control group) contributed differently in the first six months after they created accounts on Wikipedia. Specifically, we wanted to know whether there was a difference in the total number of edits they made to Wikipedia, the number of edits they made to talk pages, and the average quality of their edits as measured by content persistence.
We conducted two kinds of analyses on our dataset. First, we estimated the effect of inviting users to play the Wikipedia Adventure on our three outcomes of interest. Second, we estimated the effect of playing the Wikipedia Adventure, conditional on having been invited to do so, on those same outcomes.
To our surprise, we found that in both cases there were no significant effects on any of the outcomes of interest. Being invited to play the Wikipedia Adventure therefore had no effect on new users’ volume of participation either on Wikipedia in general, or on talk pages specifically, nor did it have any effect on the average quality of edits made by the users in our study. Despite the very positive feedback that the system received in the survey evaluation stage, it did not produce a significant change in newcomer contribution behavior. We concluded that the system by itself could not reverse the trend of newcomer attrition on Wikipedia.
Why would a system that was received so positively ultimately produce no aggregate effect on newcomer participation? We’ve identified a few possible reasons. One is that perhaps a tutorial by itself would not be sufficient to counter hostile behavior that newcomers might experience from experienced editors. Indeed, the friendly, welcoming tone of the Wikipedia Adventure might contrast with strongly worded messages that new editors receive from veteran editors or bots. Another explanation might be that users enjoyed playing the Wikipedia Adventure, but did not enjoy editing Wikipedia. After all, the two activities draw on different kinds of motivations. Finally, the system required new users to choose to play the tutorial. Maybe people who chose to play would have gone on to edit in similar ways without the tutorial.
Ultimately, this work shows us the importance of testing systems outside of lab studies. The Wikipedia Adventure was built by community members to address known gaps in the onboarding process, and our survey showed that users responded well to its design.
While it would have been easy to declare victory at that stage, the field deployment study painted a different picture. Systems like the Wikipedia Adventure may inform the design of future orientation systems. That said, more profound changes to the interface or modes of interaction between editors might also be needed to increase contributions from newcomers.
Last week, we presented a new paper that describes how children are thinking through some of the implications of new forms of data collection and analysis. The presentation was given at the ACM CHI conference in Denver last week and the paper is open access and online.
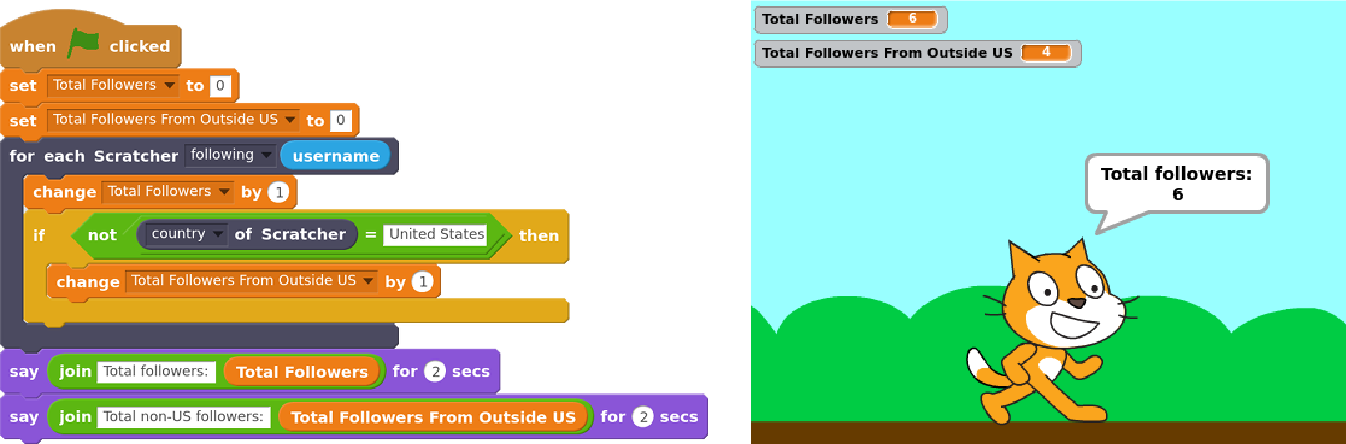
Over the last couple years, we’ve worked on a large project to support children in doing — and not just learning about — data science. We built a system, Scratch Community Blocks, that allows the 18 million users of the Scratch online community to write their own computer programs — in Scratch of course — to analyze data about their own learning and social interactions. An example of one of those programs to find how many of one’s follower in Scratch are not from the United States is shown below.
Last year, we deployed Scratch Community Blocks to 2,500 active Scratch users who, over a period of several months, used the system to create more than 1,600 projects.
As children used the system, Samantha Hautea, a student in UW’s Communication Leadership program, led a group of us in an online ethnography. We visited the projects children were creating and sharing. We followed the forums where users discussed the blocks. We read comment threads left on projects. We combined Samantha’s detailed field notes with the text of comments and forum posts, with ethnographic interviews of several users, and with notes from two in-person workshops. We used a technique called grounded theory to analyze these data.
What we found surprised us. We expected children to reflect on being challenged by — and hopefully overcoming — the technical parts of doing data science. Although we certainly saw this happen, what emerged much more strongly from our analysis was detailed discussion among children about the social implications of data collection and analysis.
In our analysis, we grouped children’s comments into five major themes that represented what we called “critical data literacies.” These literacies reflect things that children felt were important implications of social media data collection and analysis.
First, children reflected on the way that programmatic access to data — even data that was technically public — introduced privacy concerns. One user described the ability to analyze data as, “creepy”, but at the same time, “very cool.” Children expressed concern that programmatic access to data could lead to “stalking“ and suggested that the system should ask for permission.
Second, children recognized that data analysis requires skepticism and interpretation. For example, Scratch Community Blocks introduced a bug where the block that returned data about followers included users with disabled accounts. One user, in an interview described to us how he managed to figure out the inconsistency:
At one point the follower blocks, it said I have slightly more followers than I do. And, that was kind of confusing when I was trying to make the project. […] I pulled up a second [browser] tab and compared the [data from Scratch Community Blocks and the data in my profile].
Third, children discussed the hidden assumptions and decisions that drive the construction of metrics. For example, the number of views received for each project in Scratch is counted using an algorithm that tries to minimize the impact of gaming the system (similar to, for example, Youtube). As children started to build programs with data, they started to uncover and speculate about the decisions behind metrics. For example, they guessed that the view count might only include “unique” views and that view counts may include users who do not have accounts on the website.
Fourth, children building projects with Scratch Community Blocks realized that an algorithm driven by social data may cause certain users to be excluded. For example, a 13-year-old expressed concern that the system could be used to exclude users with few social connections saying:
I love these new Scratch Blocks! However I did notice that they could be used to exclude new Scratchers or Scratchers with not a lot of followers by using a code: like this:
when flag clicked
if then user’s followers < 300
stop all.
I do not think this a big problem as it would be easy to remove this code but I did just want to bring this to your attention in case this not what you would want the blocks to be used for.
Fifth, children were concerned about the possibility that measurement might distort the Scratch community’s values. While giving feedback on the new system, a user expressed concern that by making it easier to measure and compare followers, the system could elevate popularity over creativity, collaboration, and respect as a marker of success in Scratch.
I think this was a great idea! I am just a bit worried that people will make these projects and take it the wrong way, saying that followers are the most important thing in on Scratch.
Kids’ conversations around Scratch Community Blocks are good news for educators who are starting to think about how to engage young learners in thinking critically about the implications of data. Although no kid using Scratch Community Blocks discussed each of the five literacies described above, the themes reflect starting points for educators designing ways to engage kids in thinking critically about data.
Our work shows that if children are given opportunities to actively engage and build with social and behavioral data, they might not only learn how to do data analysis, but also reflect on its implications.
This blog-post and the work that it describes is a collaborative project by Samantha Hautea, Sayamindu Dasgupta, and Benjamin Mako Hill. We have also received support and feedback from members of the Scratch team at MIT (especially Mitch Resnick and Natalie Rusk), as well as from Hal Abelson from MIT CSAIL. Financial support came from the US National Science Foundation.
Attracting newcomers is among the most widely studied problems in online community research. However, with all the attention paid to challenge of getting new users, much less research has studied the flip side of that coin: large influxes of newcomers can pose major problems as well!
The most widely known example of problems caused by an influx of newcomers into an online community occurred in Usenet. Every September, new university students connecting to the Internet for the first time would wreak havoc in the Usenet discussion forums. When AOL connected its users to the Usenet in 1994, it disrupted the community for so long that it became widely known as “The September that never ended.”
Our study considered a similar influx in NoSleep—an online community within Reddit where writers share original horror stories and readers comment and vote on them. With strict rules requiring that all members of the community suspend disbelief, NoSleep thrives off the fact that readers experience an immersive storytelling environment. Breaking the rules is as easy as questioning the truth of someone’s story. Socializing newcomers represents a major challenge for NoSleep.
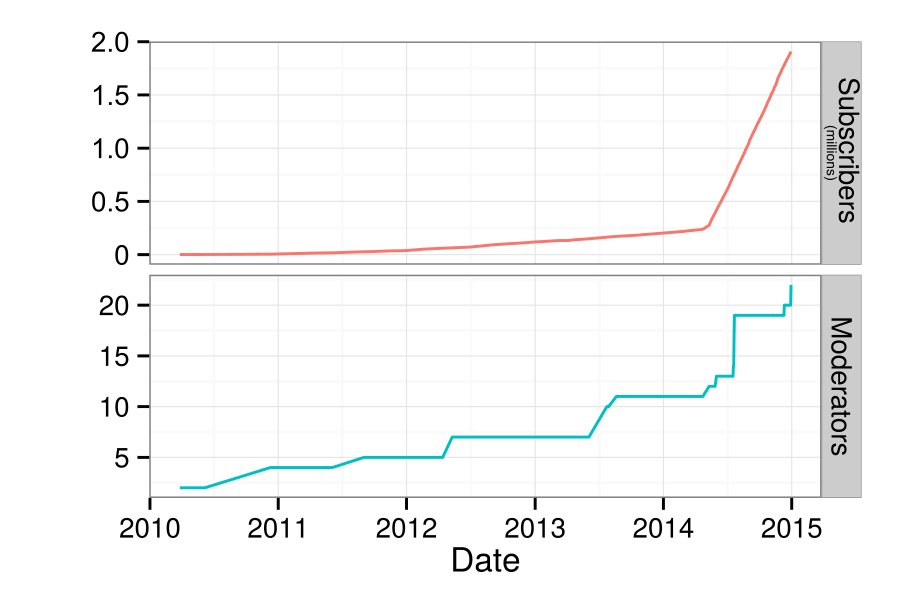
Number of subscribers and moderators on /r/NoSleep over time.
On May 7th, 2014, NoSleep became a “default subreddit”—i.e., every new user to Reddit automatically joined NoSleep. After gradually accumulating roughly 240,000 members from 2010 to 2014, the NoSleep community grew to over 2 million subscribers in a year. That said, NoSleep appeared to largely hold things together. This reflects the major question that motivated our study: How did NoSleep withstand such a massive influx of newcomers without enduring their own Eternal September?
To answer this question, we interviewed a number of NoSleep participants, writers, moderators, and admins. After transcribing, coding, and analyzing the results, we proposed that NoSleep survived because of three inter-connected systems that helped protect the community’s norms and overall immersive environment.
First, there was a strong and organized team of moderators who enforced the rules no matter what. They recruited new moderators knowing the community’s population was going to surge. They utilized a private subreddit for NoSleep’s staff. They were able to socialize and educate new moderators effectively. Although issuing sanctions against community members was often difficult, our interviewees explained that NoSleep’s moderators were deeply committed and largely uncompromising.
That commitment resonates within the second system that protected NoSleep: regulation by normal community members. From our interviews, we found that the participants felt a shared sense of community that motivated them both to socialize newcomers themselves as well as to report inappropriate comments and downvote people who violate the community’s norms.
Finally, we found that the technological systems protected the community as well. For instance, post-throttling was instituted to limit the frequency at which a writer could post their stories. Additionally, Reddit’s “Automoderator”, a programmable AI bot, was used to issue sanctions against obvious norm violators while running in the background. Participants also pointed to the tools available to them—the report feature and voting system in particular—to explain how easy it was for them to report and regulate the community’s disruptors.
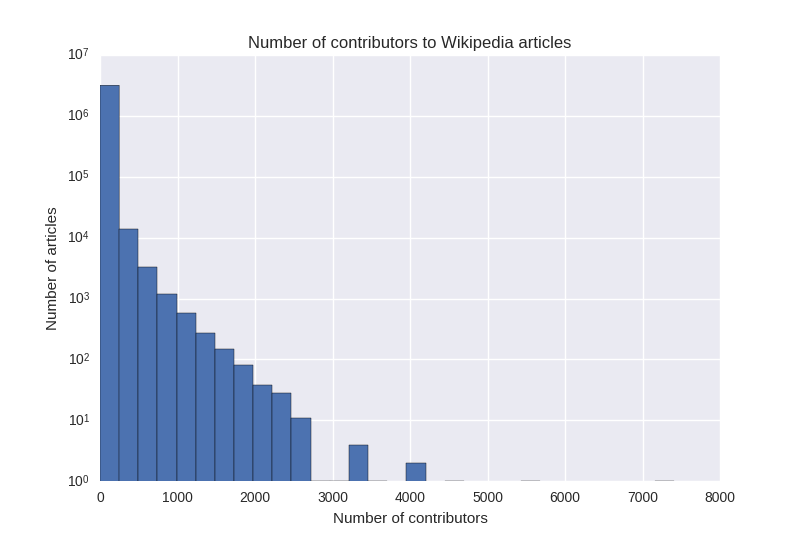
Online communities have become ubiquitous, providing not only entertainment but wielding increasing cultural and political influence. While news organizations and researchers have focused a lot of attention on online communities after they become influential, very little is known about how or why they get started. Our survey of hundreds of Wikia.com founders shows that typical online communities are actually very different from the communities that are “in the news”. Online community founders have diverse motivations, but typically have modest goals which are focused on filling their own needs, and they don’t necessarily care if their projects ever get very big. Our research suggests that rather than being failures, small online communities are both intentional and common.
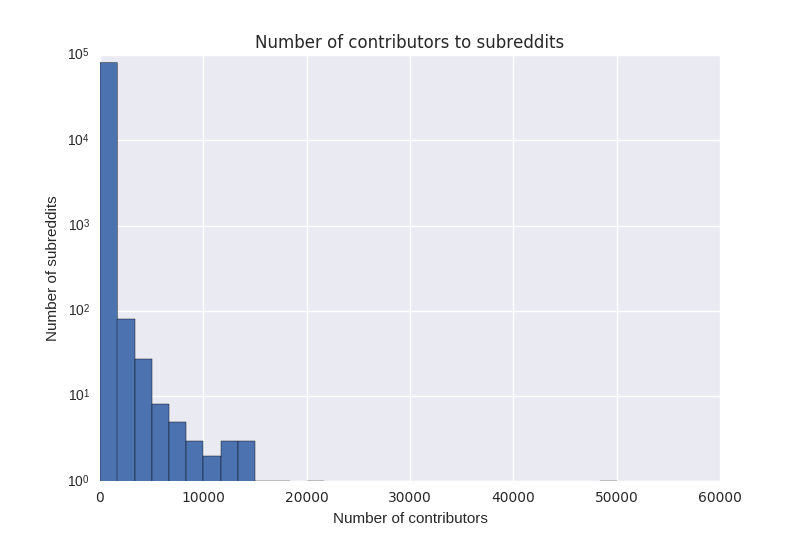
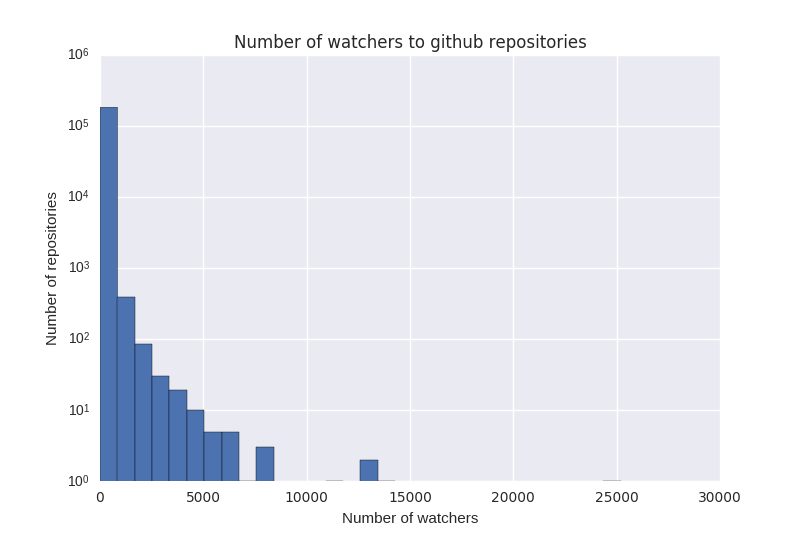
Most online communities are small —Our research is inspired by the skewed distribution of attention online. For example, these three graphs show the number of contributors to each subreddit, github project, and Wikipedia page. (Note the log scale – the reality is even more skewed than these plots make it appear). In every case, there is a “long tail” of projects with very few contributions or attention, while the most popular projects get the lion’s share. It is perhaps unsurprising, then, that they also garner the majority of scholarly attention. However, what these graphs also show is that most online communities are very small.
Even when scholars include smaller communities in their analysis, they typically treat longevity and size as measures of success. Using this metric, the vast majority of new projects fail. So why do people start new online communities? Are they simply naive, not realizing that large-scale success is so rare? Are community founders trying to win the attention lottery?
Our Survey —We worked with some great folks at Wikia to send a survey to community founders right after they started their community. We received partial or full responses from hundreds of founders.
Wikia homepage as it appeared during our data collection (via archive.org) with the invitation to found a new wiki highlighted. Twilight was really big in 2010.
In addition to demographic information, we asked a set of thirteen questions about the motivations of founders, based on the contributor motivation literature, and seven questions about their goals for their community. We also asked founders about their plans for their community, and whether they were planning to follow some of the best practices for building and running online communities.
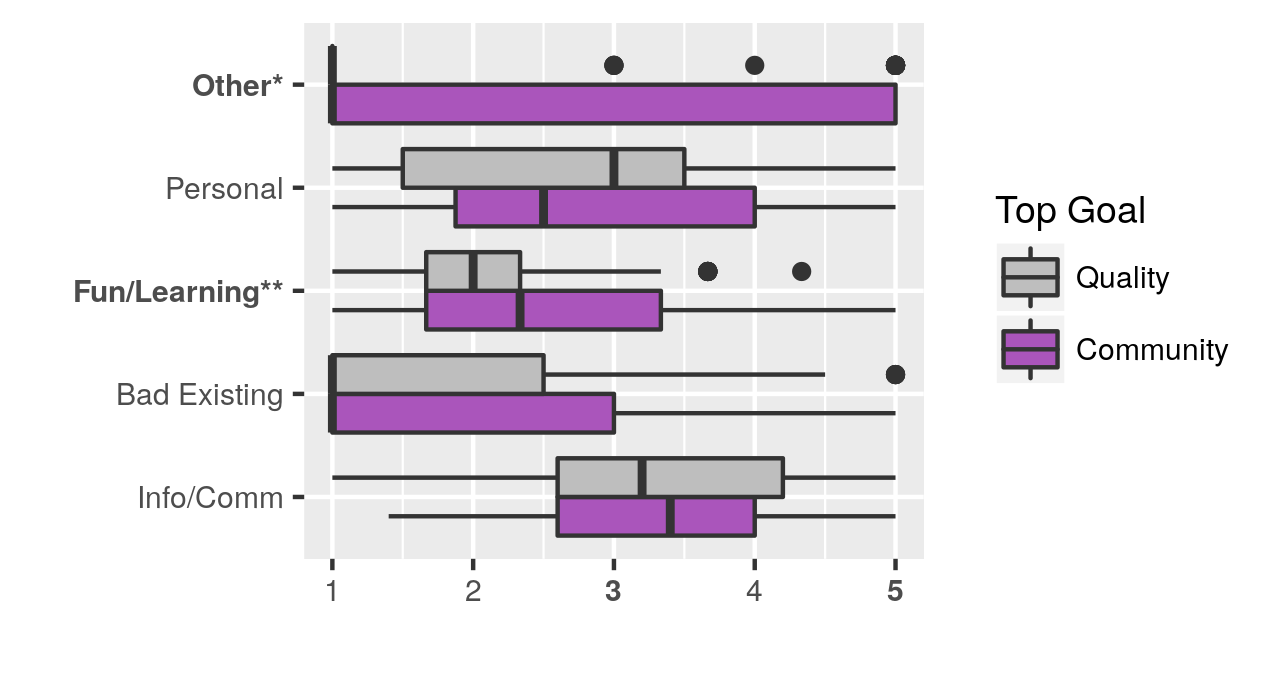
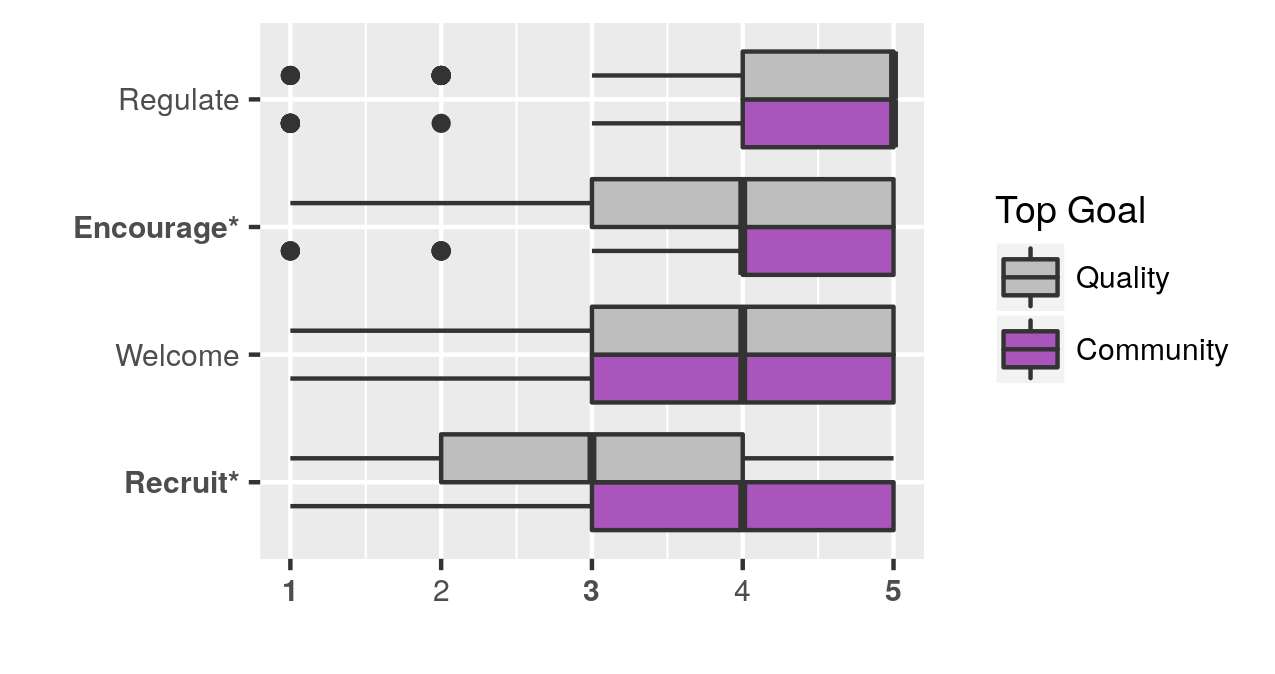
Founders have diverse motivations and modest goals — We found that Wikia founders have diverse motivations. We used PCA to identify four main motivations for creating new wikis: spreading information and building a community, problems with existing wikis, for fun or learning, and creating and publicizing personal content. Spreading information and building a community was the most common motivation, but each of these was marked as a primary motivation by multiple respondents.
We also found that the barriers to starting a new community – both technological and cognitive – are very low. Only 32% of founders reported planning on starting their wiki for a few weeks or longer, while fully 46% of founders had only planned it for a few hours or a few minutes.
As with motivations, founders had diverse goals. The most common top goal was the creation of high-quality information, with nearly half of respondents selecting it. Community longevity/activity and growth were also common goals.
Finally, we looked at whether there was a relationship between motivations and goals, and between goals and plans for community building. We found that those whose top goal was information quality were less likely to be motivated by fun and learning, and that they were less likely to plan on recruiting contributors or encouraging contributions. In future research, we are looking at how a founder’s goals and plans relate to membership and contribution growth.
Distribution of founder motivations and plans, based on whether their top goal is community or information quality.
So what? —We believe that platform designers and researchers should focus more of their resources on understanding small and short-lived communities. Our research suggests that the attention paid to the more popular and long-lived online communities has perpetuated a false assumption that all communities seek to become large and powerful. Indeed, our respondents are typically not seeking or even hoping for large-scale “success”.
In addition, we believe that in many contexts, understanding online communities can be augmented by focusing on founders. Platform designers can study founders to understand how users would like to use a system and researchers can do more to understand the differences between founders and other contributors.
There is also a need to generalize this research – founders on other online platforms (Reddit, github, etc.) may have a different set of motivations and goals (although we suspect that they will be similarly modest in their ambitions). Overall, there is lots of room for additional research on how and why things get started online.
This post (and the paper) were written by Jeremy Foote, Aaron Shaw and Darren Gergle. The charts at the beginning of the post were created using data from the great public datasets at Big Query. Anonymized results of the survey are publicly available, and code is coming.
Front page of the Scratch online community (https://scratch.mit.edu) during the period covered by the dataset.
Since 2010, I havepublishedaseriesofpapers using quantitative data collected from the database behind the Scratch online community. As the source of data for many of my first quantitative and data scientific papers, it’s not a major exaggeration to say that I have built my academic career on the dataset.
I was able to do this work because I happened to be doing my masters in a research group that shared a physical space (“The Cube”) with LLK and because I was friends with Andrés Monroy-Hernández, who started in my masters cohort at the Media Lab. A year or so after we met, Andrés conceived of the Scratch online community and created the first version for his masters thesis project. Because I was at MIT and because I knew the right people, I was able to get added to the IRB protocols and jump through the hoops necessary to get access to the database.
Over the years, Andrés and I have heard over and over, in conversation and in reviews of our papers, that we were privileged to have access to such a rich dataset. More than three years ago, Andrés and I began trying to figure out how we might broaden this access. Andrés had the idea of taking advantage of the launch of Scratch 2.0 in 2013 to focus on trying to release the first five years of Scratch 1.x online community data (March 2007 through March 2012) — most of the period that the codebase he had written ran the site.
After more work than I have put into any single research paper or project, Andrés and I have published a data descriptor in Nature’s new journal Scientific Data. This means that the data is now accessible to other researchers. The data includes five years of detailed longitudinal data organized in 32 tables with information drawn from more than 1 million Scratch users, nearly 2 million Scratch projects, more than 10 million comments, more than 30 million visits to Scratch projects, and much more. The dataset includes metadata on user behavior as well the full source code for every project. Alongside the data is the source code for all of the software that ran the website and that users used to create the projects as well as the code used to produce the dataset we’ve released.
Releasing the dataset was a complicated process. First, we had navigate important ethical concerns about the the impact that a release of any data might have on Scratch’s users. Toward that end, we worked closely with the Scratch team and the the ethics board at MIT to design a protocol for the release that balanced these risks with the benefit of a release. The most important features of our approach in this regard is that the dataset we’re releasing is limited to only public data. Although the data is public, we understand that computational access to data is different in important ways to access via a browser or API. As a result, we’re requiring anybody interested in the data to tell us who they are and agree to a detailed usage agreement. The Scratch team will vet these applicants. Although we’re worried that this creates a barrier to access, we think this approach strikes a reasonable balance.
Beyond the the social and ethical issues, creating the dataset was an enormous task. Andrés and I spent Sunday afternoons over much of the last three years going column-by-column through the MySQL database that ran Scratch. We looked through the source code and the version control system to figure out how the data was created. We spent an enormous amount of time trying to figure out which columns and rows were public. Most of our work went into creating detailed codebooks and documentation that we hope makes the process of using this data much easier for others (the data descriptor is just a brief overview of what’s available). Serializing some of the larger tables took days of computer time.
In this process, we had a huge amount of help from many others including an enormous amount of time and support from Mitch Resnick, Natalie Rusk, Sayamindu Dasgupta, and Benjamin Berg at MIT as well as from many other on the Scratch Team. We also had an enormous amount of feedback from a group of a couple dozen researchers who tested the release as well as others who helped us work through through the technical, social, and ethical challenges. The National Science Foundation funded both my work on the project and the creation of Scratch itself.
Because access to data has been limited, there has been less research on Scratch than the importance of the system warrants. We hope our work will change this. We can imagine studies using the dataset by scholars in communication, computer science, education, sociology, network science, and beyond. We’re hoping that by opening up this dataset to others, scholars with different interests, different questions, and in different fields can benefit in the way that Andrés and I have. I suspect that there are other careers waiting to be made with this dataset and I’m excited by the prospect of watching those careers develop.
The paper and work this post describes is collaborative work with Andrés Monroy-Hernández. The paper is released as open access so anyone can read the entire paper here. This blog post was also posted on Benjamin Mako Hill’s blog.
As children use digital media to learn and socialize, others are collecting and analyzing data about these activities. In school and at play, these children find that they are the subjects of data science. As believers in the power of data analysis, we believe that this approach falls short of data science’s potential to promote innovation, learning, and power.
Motivated by this fact, we have been working over the last three years as part of a team at the MIT Media Lab and the University of Washington to design and build a system that attempts to support an alternative vision: children as data scientists. The system we have built is described in a new paper—Scratch Community Blocks: Supporting Children as Data Scientists—that will be published in the proceedings of CHI 2017.
Our system is built on top of Scratch, a visual, block-based programming language designed for children and youth. Scratch is also an online community with over 15 million registered members who share their Scratch projects, remix each others’ work, have conversations, provide feedback, bookmark or “love” projects they like, follow other users, and more. Over the last decade, researchers—including us—have used the Scratch online community’s database to study the youth using Scratch. With Scratch Community Blocks, we attempt to put the power to programmatically analyze these data into the hands of the users themselves.
To do so, our new system adds a set of new programming primitives (blocks) to Scratch so that users can access public data from the Scratch website from inside Scratch. Blocks in the new system gives users access to project and user metadata, information about social interaction, and data about what types of code are used in projects. The full palette of blocks to access different categories of data is shown below.
Project metadataUser metadataSite-wide statistics
The new blocks allow users to programmatically access, filter, and analyze data about their own participation in the community. For example, with the simple script below, we can find whether we have followers in Scratch who report themselves to be from Spain, and what their usernames are.
Simple demonstration of Scratch Community Blocks
In designing the system, we had two primary motivations. First, we wanted to support avenues through which children can engage in curiosity-driven, creative explorations of public Scratch data. Second, we wanted to foster self-reflection with data. As children looked back upon their own participation and coding activity in Scratch through the project they and their peers made, we wanted them to reflect on their own behavior and learning in ways that shaped their future behavior and promoted exploration.
After designing and building the system over 2014 and 2015, we invited a group of active Scratch users to beta test the system in early 2016. Over four months, 700 users created more than 1,600 projects. The diversity and depth of users creativity with the new blocks surprised us. Children created projects that gave the viewer of the project a personalized doughnut-chart visualization of their coding vocabulary on Scratch, rendered the viewer’s number of followers as scoops of ice-cream on a cone, attempted to find whether “love-its” for projects are more common on Scratch than “favorites”, and told users how “talkative” they were by counting the cumulative string-length of project titles and descriptions.
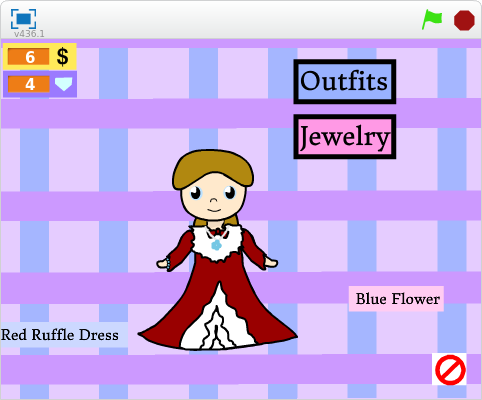
We found that children, rather than making canonical visualizations such as pie-charts or bar-graphs, frequently made information representations that spoke to their own identities and aesthetic sensibilities. A 13-year-old girl had made a virtual doll dress-up game where the player’s ability to buy virtual clothes and accessories for the doll was determined by the level of their activity in the Scratch community. When we asked about her motivation for making such a project, she said:
I was trying to think of something that somebody hadn’t done yet, and I didn’t see that. And also I really like to do art on Scratch and that was a good opportunity to use that and mix the two [art and data] together.
We also found at least some evidence that the system supported self-reflection with data. For example, after seeing a project that showed its viewers a visualization of their past coding vocabulary, a 15-year-old realized that he does not do much programming with the pen-related primitives in Scratch, and wrote in a comment, “epic! looks like we need to use more pen blocks. :D.”
Doughnut visualizationIce-cream visualizationData-driven doll dress up
Additionally, we noted that that as children made and interacted with projects made with Scratch Community Blocks, they started to critically think about the implications of data collection and analysis. These conversations are the subject of another paper (also being published in CHI 2017).
In a 1971 article called “Teaching Children to be Mathematicians vs. Teaching About Mathematics”, Seymour Papert argued for the need for children doing mathematics vs. learning about it. He showed how Logo, the programming language he was developing at that time with his colleagues, could offer children a space to use and engage with mathematical ideas in creative and personally motivated ways. This, he argued, enabled children to go beyond knowing about mathematics to “doing” mathematics, as a mathematician would.
Scratch Community Blocks has not yet been launched for all Scratch users and has several important limitations we discuss in the paper. That said, we feel that the projects created by children in our the beta test demonstrate the real potential for children to do data science, and not just know about it, provide data for it, and to have their behavior nudged and shaped by it.
This blog-post and the work that it describes is a collaborative project between Sayamindu Dasgupta and Benjamin Mako Hill. We have also received support and feedback from members of the Scratch team at MIT (especially Mitch Resnick and Natalie Rusk), as well as from Hal Abelson from MITCSAIL. Financial support came from the US National Science Foundation. We will be presenting this paper at CHI in May, and will be thrilled to talk more about our work and about future directions.
With more than 10 million users, the Scratch online community is the largest online community where kids learn to program. Since it was created, a central goal of the community has been to promote “remixing” — the reworking and recombination of existing creative artifacts. As the video above shows, remixing programming projects in the current web-based version of Scratch is as easy is as clicking on the “see inside” button in a project web-page, and then clicking on the “remix” button in the web-based code editor. Today, close to 30% of projects on Scratch are remixes.
Remixing plays such a central role in Scratch because its designers believed that remixing can play an important role in learning. After all, Scratch was designed first and foremost as a learning community with its roots in the Constructionist framework developed at MIT by Seymour Papert and his colleagues. The design of the Scratch online community was inspired by Papert’s vision of a learning community similar to Brazilian Samba schools (Henry Jenkins writes about his experience of Samba schools in the context of Papert’s vision here), and a comment Marvin Minsky made in 1984:
Adults worry a lot these days. Especially, they worry about how to make other people learn more about computers. They want to make us all “computer-literate.” Literacy means both reading and writing, but most books and courses about computers only tell you about writing programs. Worse, they only tell about commands and instructions and programming-language grammar rules. They hardly ever give examples. But real languages are more than words and grammar rules. There’s also literature – what people use the language for. No one ever learns a language from being told its grammar rules. We always start with stories about things that interest us.
Of course, because Scratch is an informal environment with no set path for users, no lesson plan, and no quizzes, measuring learning is an open problem. In our study, we built on two different approaches to measure learning in Scratch. The first approach considers the number of distinct types of programming blocks available in Scratch that a user has used over her lifetime in Scratch (there are 120 in total) — something that can be thought of as a block repertoire or vocabulary. This measure has been used to model informal learning in Scratch in an earlier study. Using this approach, we hypothesized that users who remix more will have a faster rate of growth for their code vocabulary.
Controlling for a number of factors (e.g. age of user, the general level of activity) we found evidence of a small, but positive relationship between the number of remixes a user has shared and her block vocabulary as measured by the unique blocks she used in her non-remix projects. Intriguingly, we also found a strong association between the number of downloads by a user and her vocabulary growth. One interpretation is that this learning might also be associated with less active forms of appropriation, like the process of reading source code described by Minksy.
The second approach we used considered specific concepts in programming, such as loops, or event-handling. To measure this, we utilized a mapping of Scratch blocks to key programming concepts found in this paper by Karen Brennan and Mitchel Resnick. For example, in the image below are all the Scratch blocks mapped to the concept of “loop”.
We looked at six concepts in total (conditionals, data, events, loops, operators, and parallelism). In each case, we hypothesized that if someone has had never used a given concept before, they would be more likely to use that concept after encountering it while remixing an existing project.
Using this second approach, we found that users who had never used a concept were more likely to do so if they had been exposed to the concept through remixing. Although some concepts were more widely used than others, we found a positive relationship between concept use and exposure through remixing for each of the six concepts. We found that this relationship was true even if we ignored obvious examples of cutting and pasting of blocks of code. In all of these models, we found what we believe is evidence of learning through remixing.
Of course, there are many limitations in this work. What we found are all positive correlations — we do not know if these relationships are causal. Moreover, our measures do not really tell us whether someone has “understood” the usage of a given block or programming concept.However, even with these limitations, we are excited by the results of our work, and we plan to build on what we have. Our next steps include developing and utilizing better measures of learning, as well as looking at other methods of appropriation like viewing the source code of a project.
In wikis, redirects are special pages that silently take readers from the page they are visiting to another page. Although their presence is noted in tiny gray text (see the image below) most people use them all the time and never know they exist. Redirects exist to make linking between pages easier, they populate Wikipedia’s search autocomplete list, and are generally helpful in organizing information. In the English Wikipedia, redirects make up more than half of all article pages.
Over the years, I’ve spent some time contributing to to Redirects for Discussion (RfD). I think of RfD as like an ultra-low stakes version of Articles for Deletion where Wikipedians decide whether to delete or keep articles. If a redirect is deleted, viewers are taken to a search results page and almost nobody notices. That said, because redirects are almost never viewed directly, almost nobody notices if a redirect is kept either!
I’ve told people that if they want to understand the soul of a Wikipedian, they should spend time participating in RfD. When you understand why arguing about and working hard to come to consensus solutions for how Wikipedia should handle individual redirects is an enjoyable way to spend your spare time — where any outcome is invisible — you understand what it means to be a Wikipedian.
That said, wiki researchers rarely take redirects into account. For years, I’ve suspected that accounting for redirects was important for Wikipedia research and that several classes of findings were noisy or misleading because most people haven’t done so. As a result, I worked with my colleague Aaron Shaw at Northwestern earlier this year to build a longitudinal dataset of redirects that can capture the dynamic nature of redirects. Our work was published as a short paper at OpenSym several months ago.
It turns out, taking redirects into account correctly (especially if you are looking at activity over time) is tricky because redirects are stored as normal pages by MediaWiki except that they happen to start with special redirect text. Like other pages, redirects can be updated and changed over time are frequently are. As a result, taking redirects into account for any study that looks at activity over time requires looking at the text of every revision of every page.
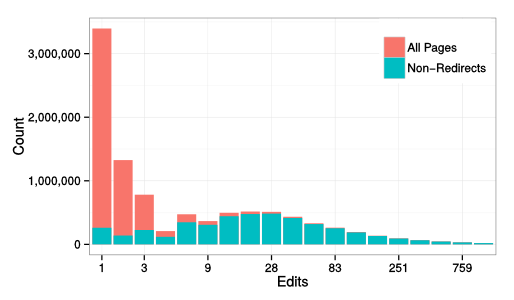
Using our dataset, Aaron and I showed that the distribution of edits across pages in English Wikipedia (a relationships that is used in many research projects) looks pretty close to log normal when we remove redirects and very different when you don’t. After all, half of articles are really just redirects and, and because they are just redirects, these “articles” are almost never edited.
Another puzzling finding that’s been reported in a few places — and that I repeated myself several times — is that edits and views are surprisingly uncorrelated. I’ll write more about this later but the short version is that we found that a big chunk of this can, in fact, be explained by considering redirects.