In May 2019, we were invited to give short remarks on the impact of Janet Fulk and Peter Monge at the International Communication Association‘s annual meeting as part of a session called “Igniting a TON (Technology, Organizing, and Networks) of Insights: Recognizing the Contributions of Janet Fulk and Peter Monge in Shaping the Future of Communication Research.”
Youtube: Mako Hill @ Janet Fulk and Peter Monge Celebration at ICA 2019
Mako Hill gave a four-minute talk on Janet and Peter’s impact to the work of the Community Data Science Collective. Mako unpacked some of the cryptic acronyms on the CDSC-UW lab’s whiteboard as well as explaining that our group has a home in the academic field of communication, in no small part, because of the pioneering scholarship of Janet and Peter. You can view the talk in WebM or on Youtube.
Do online communities compete with each other over resources or niches? Do they co-evolve in symbiotic or even parasitic relationships? What insights can we gain by applying ecological models of collective behavior to the study of collaborative online groups?
A colorful pisaster ochraceus (a.k.a., pisaster), a sea star species whose presence or absence can radically alter the ecology of an intertidal community. Our research will adapt theories created to explain the population dymamics of organisms like the pisaster in the context of online communities and human organizations (photo: Multi-Agency Rocky Intertidal Network).
We are delighted to announce that a Community Data Science Collective (CDSC) team led by Nate TeBlunthuis and Jeremy Foote has just started work on a three-year grant from the U.S. National Science Foundation to study the ecological dynamics of online communities! Aaron Shaw and Benjamin Mako Hill are principal investigators for the grant.
The projects supported by the award will extend the study of peer production and online communities by analyzing how aspects of communities’ environments impact their growth, patterns of participation, and survival. The work draws on recent research on various biological systems, organizational ecology, and human computer interaction (HCI). In general, we adapt these approaches to inform quantitative and computational analysis of populations of peer production communities and other online organizations.
As a major goal, we want to explain the conditions under which certain ecological dynamics emerge versus when they do not. For example, prior work has suggested that communities interact in ways that are both competitive and mutalistic. But what leads two communities to become competitors and others to benefit each other? We aim to understand when these patterns to arise. We are also interested in how community leaders might pursue effective strategies for survival given circumstances in the surrounding environment.
The grant promises to support a number of projects within the CDSC. Nate and Jeremy led the proposal writing as well as two key pilot studies that informed the development of the proposal. Other group members are now involved in planning and developing multiple studies under the grant.
The grant was awarded by the NSF Cyber-Human Systems (CHS) program within the Directorate for Information and Intellligent Systems (IIS) and the award is shared by Northwestern and the University of Washington (award numbers IIS-1910202 and IIS-1908850).
We’ve published the description of the proposal that we submitted to the NSF, although some details will shift as we carry out the project. The best place to stay up-to-date about the work will be to follow [the CDSC Twitter account (@ComDataSci)or the CDSC blog.
It’s Ph.D. application season and the Community Data Science Collective is recruiting! As always, we are looking for talented people to join our research group. Applying to one of the Ph.D. programs that Aaron, Mako, Sayamindu, and Jeremy are affiliated with is a great way to do that.
This post provides a very brief run-down on the CDSC, the different universities and Ph.D. programs we’re affiliated with, and what we’re looking for when we review Ph.D. applications. It’s close to the deadline for some of our programs, but we hope this post will still be useful to prospective applicants now and in the future.
Members of the CDSC at a group retreat in Evanston, Illinois in September 2019. Clockwise from far right is: Salt, Jackie, Floor, Sejal, Nick, Kaylea, Sohyeon, Aaron, Nate, Jeremy, Mako, Jim, Charlie, and Regina. Sayamindu and Sneha are will us in spirit!
What are these different Ph.D. programs? Why would I choose one over the other?
The group currently includes four faculty principal investigators (PIs): Aaron Shaw (Northwestern University), Benjamin Mako Hill (University of Washington in Seattle), Sayamindu Dasgupta (University of North Carolina at Chapel Hill), and Jeremy Foote (Purdue University). The PIs advise Ph.D. students in Ph.D. programs at their respective universities. Our programs are each described below.
Although we often work together on research and serve as co-advisors to students in each others’ projects, each faculty person has specific areas of expertise and unique interests. The reasons you might choose to apply to one Ph.D. program or to work with a specific faculty member include factors like your previous training, career goals, and the alignment of your specific research interests with our respective skills.
At the same time, a great thing about the CDSC is that we all collaborate and regularly co-advise students across our respective campuses, so the choice to apply to or attend one program does not prevent you from accessing the expertise of our whole group. But please keep in mind that our different Ph.D. programs have different application deadlines, requirements, and procedures!
Benjamin Mako Hill is an Assistant Professor of Communication at the University of Washington. He is also an Adjunct Assistant Professor at UW’s Department of Human-Centered Design and Engineering (HCDE) and Computer Science and Engineering (CSE). Although most of Mako’s students are in the Department of Communication, he also advises students in the Department of Computer Science and Engineering and HCDE—although he typically has limited ability to admit students into those programs. Mako’s research focuses on population-level studies of peer production projects, computational social science, efforts to democratize data science, and informal learning.
Aaron Shaw is an Associate Professor in the Department of Communication Studies at Northwestern. In terms of Ph.D. programs, Aaron’s primary affiliations are with the Media, Technology and Society (MTS) and the Technology and Social Behavior (TSB) Ph.D. programs. Aaron also has a courtesy appointment in the Sociology Department at Northwestern, but he has not directly supervised any Ph.D. advisees in that department (yet). Aaron’s current research projects focus on comparative analysis of the organization of peer production communities and social computing projects, participation inequalities in online communities, and empirical research methods.
Jeremy Foote
Jeremy Foote is an Assistant Professor at the Brian Lamb School of Communication at Purdue University. He is affiliated with the Organizational Communication and Media, Technology, and Society programs. Jeremy’s current research focuses on how individuals decide when and in what ways to contribute to online communities, and how understanding those decision-making processes can help us to understand which things become popular and influential. Most of his research is done using data science methods and agent-based simulations.
What do you look for in Ph.D. applicants?
There’s no easy or singular answer to this. In general, we look for curious, intelligent people driven to develop original research projects that advance scientific and practical understanding of topics that intersect with any of our collective research interests.
To get an idea of the interests and experiences present in the group, read our respective bios and CVs (follow the links above to our personal websites). Specific skills that we and our students tend to use on a regular basis include experience consuming and producing social science and/or social computing (human-computer interaction) research; applied statistics and statistical computing, various empirical research methods, social theory and cultural studies, and more.
Formal qualifications that speak to similar skills and show up in your resume, transcripts, or work history are great, but we are much more interested in your capacity to learn, think, write, analyze, and/or code effectively than in your credentials, test scores, grades, or previous affiliations. It’s graduate school and we do not expect you to show up pre-certified in all the ways or knowing how to do all the things already.
Intellectual creativity, persistence, and a willingness to acquire new skills and problem-solve matter a lot. We think doctoral education is less about executing a task that someone else hands you and more about learning how to identify a new, important problem; develop an appropriate approach to solving it; and explain all of the above and why it matters so that other people can learn from you in the future. Evidence that you can or at least want to do these things is critical. Indications that you can also play well with others and would make a generous, friendly colleague are really important too.
All of this is to say, we do not have any one trait or skill set we look for in prospective students. We strive to be inclusive along every possible dimension. Each person who has joined our group has contributed unique skills and experiences as well as their own personal interests. We want our future students and colleagues to do the same.
Now what?
Still not sure whether or how your interests might fit with the group? Still have questions? Still reading and just don’t want to stop? Follow the links above for more information. Feel free to send at least one of us an email. We are happy to try to answer your questions and always eager to chat.
The conference marks the official publication of four papers by collective students and faculty. All four papers were published in the journal Proceedings of the ACM on Human-Computer Interaction: CSCW.
Information on the talks as well as links to the papers are available here (CSCW members are listed in italics):
Mon, Nov 11 14:30 – 16:00: A Forensic Qualitative Analysis of Contributions to Wikipedia from Anonymity-Seeking Users by Kaylea Champion (UW), Nora McDonald (Drexel), Stephanie E Bankes (Drexel), Joseph Zhang (Drexel), Rachel Greenstadt (NYU), Andrea Forte (Drexel), Benjamin Mako Hill (UW). Kaylea will present! [Paper]
Mon, Nov 11 14:30 – 16:00: Wikipedia and Wiki Research
Salt, Kaylea, Charlie, Regina, and Kaylea will all be at the conference as will affiliate Andrés Monroy-Hernández and tons of our social computing friends. Please come and say “Hello” to any of us, introduce yourself if you don’t already know us, and pick up a CDSC sticker!
Why learning some statistics and some data visualization matters. (Gif from Matejka and Fitzmaurice, “Same stats, different graphs”, CHI 2017: https://dl.acm.org/citation.cfm?id=3025912)
I taught a graduate-level introduction to applied statistics and statistical computing this past Spring. The course design iterated on a class Mako developed in 2017. Very nearly all of the course materials are available open access through the Community Data Science Collective wiki and I wanted to make sure to share them more widely with this post. I’ve also been reflecting a bit on how the course went and thought I’d share those thoughts here in case anyone wants to adopt the course in the future.
First off, the course uses the OpenIntro Statistics (3rd edition) textbook as the core of the course readings and assignments. If you’re not familiar with OpenIntro and you want to learn or teach applied statistics from a general, social scientific perspective, you should check it out! All of the data, code, and LaTeX used to produce the textbook is licensed freely for reuse and the site also hosts video lectures, lecture notes, homework assignments, a discussion forum and more.
Alongside the OpenIntro materials, I worked together with Jeremy Foote (who was the TA for the course before he left to be new faculty at Purdue) to develop a bunch of tutorials in RMarkdown to help students complete the problem set assignments. We also posted worked solutions to the problem sets (also in RMarkdown). These replicated and expanded on screencasts Mako had recorded for his course.
The classroom sessions focused on discussion and problem solving. Basically, students came to each session knowing that I expected them to have completed the problem sets. I then did my best to answer any questions people had and assigned individuals (in some cases using a randomization script in R to pick names!) to summarize their solutions and approaches to specific problems that seemed important to cover.
It was my first time teaching a course like this and I had a few reflections after completing the quarter and reading through the feedback from students.
A major challenge for a course like this is pitching the material to an appropriate level given that students (in the MTS and TSB programs here at Northwestern at least) arrive with such varied knowledge of the subject matter. I think I did okay on this front in some ways and not in others. It was especially challenging given the semi-flipped classroom approach.
In some weeks, there was just too much material to cover in adequate depth. In some others, I was insufficiently organized and concise to cover everything. Whatever the case, I would cut back a bit next time. (I’ve noticed that this is a common issue for me the first time I teach any class, but I still struggle to correct it.)
Whatever challenges and failures I may have introduced in the design or instruction of the course, the students produced a bunch of highly original and engaging final projects. I’m optimistic that some of these projects will wind up as published work soon. Nothing like brilliant, motivated students to help the professor feel better about his own shortcomings!
Nearly all of the course materials are available on the CDSC wiki. The exceptions are a few of the readings and supplementary materials that I didn’t have the rights or desire to post on the public web. If you’re looking for any of that, feel free to send me an email and I can see if it’s appropriate to share.
Also, OpenIntro just came out with the fourth edition of their statistics textbook! I haven’t had a chance to check it out yet, but I’m eager to see what kinds of changes they introduced.
Introducing new technology into a work place is often disruptive, but what if your work was also completely mediated by technology? This is exactly the case for the teams of volunteer moderatorswho work to regulate content and protect online communities from harm. What happens when the social media platforms these communities rely on change completely? How do moderation teams overcome the challenges caused by new technological environments? How do they do so while managing a “brand new” community with tens of thousands of users?
For a new study that will be published in CSCW in November, we interviewed 14 moderators of 8 “subreddit” communities from the social media aggregation and discussion platform Reddit to answer these questions. We chose these communities because each community had recently adopted the real-time chat platform Discord to support real-time chat in their community. This expansion into Discord introduced a range of challenges—especially for the moderation teams of large communities.
We found that moderation teams of large communities improvised their own creative solutions to challenges they faced by building bots on top of Discord’s API. This was not too shocking given that APIs and bots are frequently cited as tools that allow innovation and experimentation when scaling up digital work. What did surprise us, however, was how important moderators’ past experiences were in guiding the way they used bots. In the largest communities that faced the biggest challenges, moderators relied on bots to reproduce the tools they had used on Reddit. The moderators would often go so far as to give their bots the names of moderator tools available on Reddit. Our findings suggest that support for user-driven innovation is important not only in that it allows users to explore new technological possibilities but also in that it allows users to mine their past experiences to introduce old systems into new environments.
What Challenges Emerged in Discord?
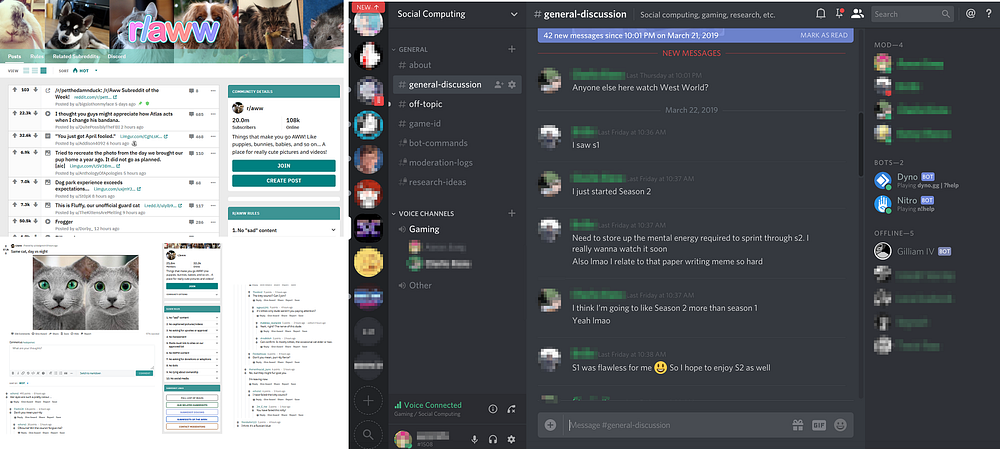
Left: A screenshot of the subreddit /r/aww. Right: A screenshot of a Discord server named “Social Computing”.
Discord’s text channels allow for more natural, in the moment conversations compared to Reddit. In Discord, this social aspect also made moderation work much more difficult. One moderator explained:
“It’s kind of rough because if you miss it, it’s really hard to go back to something that happened eight hours ago and the conversation moved on and be like ‘hey, don’t do that.’ ”
Moderators we spoke to found that the work of managing their communities was made even more difficult by their community’s size:
On the day to day of running 65,000 people, it’s literally like running a small city…We have people that are actively online and chatting that are larger than a city…So it’s like, that’s a lot to actually keep track of and run and manage.”
The moderators of large communities repeatedly told us that the tools provided to moderators on Discord were insufficient. For example, they pointed out tools like Discord’s Audit Log was inadequate for keeping track of the tens of thousands of members of their communities. Discord also lacks automated moderation tools like the Reddit’s Automoderator and Modmail leaving moderators on Discord with few tools to scale their work and manage communications with community members.
How Did Moderation Teams Overcome These Challenges?
The moderation teams we talked with adapted to these challenges through innovative uses of Discord’s API toolkit. Like many social media platforms, Discord offers a public API where users can develop apps that interact with the platform through a Discord “bot.” We found that these bots play a critical role in helping moderation teams manage Discord communities with large populations.
Guided by their experience with using tools like Automoderator on Reddit, moderators working on Discord built bots with similar functionality to solve the problems associated with scaled content and Discord’s fast-paced chat affordances. This bots would search for regular expressions and URLs that go against the community’s rules:
“It makes it so that rather than having to watch every single channel all of the time for this sort of thing or rely on users to tell us when someone is basically running amuck, posting derogatory terms and terrible things that Discord wouldn’t catch itself…so it makes it that we don’t have to watch every channel.”
Bots were also used to replace Discord’s Audit Log feature with what moderators referred to often as “Mod logs”—another term borrowed from Reddit. Moderators will send commands to a bot like “!warn username” to store information such as when a member of their community has been warned for breaking a rule and automatically store this information in a private text channel in Discord. This information helps organize information about community members, and it can be instantly recalled with another command to the bot to help inform future moderation actions against other community members.
Finally, moderators also used Discord’s API to develop bots that functioned virtually identically to Reddit’s Modmail tool. Moderators are limited in their availability to answer questions from members of their community, but tools like the “Modmail” helps moderation teams manage this problem by mediating communication to community members with a bot:
“So instead of having somebody DM a moderator specifically and then having to talk…indirectly with the team, a [text] channel is made for that specific question and everybody can see that and comment on that. And then whoever’s online responds to the community member through the bot, but everybody else is able to see what is being responded.”
The tools created with Discord’s API — customizable automated content moderation, Mod logs, and a Modmail system — all resembled moderation tools on Reddit. They even bear their names! Over and over, we found that moderation teams essentially created and used bots to transform aspects of Discord, like text channels into Mod logs and Mod Mail, to resemble the same tools they were using to moderate their communities on Reddit.
What Does This Mean for Online Communities?
We think that the experience of moderators we interviewed points to a potentially important underlooked source of value for groups navigating technological change: the potent combination of users’ past experience combined with their ability to redesign and reconfigure their technological environments. Our work suggests the value of innovation platforms like APIs and bots is not only that they allow the discovery of “new” things. Our work suggests that these systems value also flows from the fact that they allow the re-creation of the the things that communities already know can solve their problems and that they already know how to use.
Our work has several more specific takeaways as well. For moderators and community leaders:
Leaders of online communities planning to add an additional platform to host more discussion and social interactions for their community members should consider platforms with public APIs like Discord. You may run into challenges that the platform’s default tools are ineffective at solving, but public APIs allow for users to write software to solve their own problems.
For designers of online communities:
Designers of social media applications and platforms that host online communities should consider the effects of community growth and large population sizes on the work of moderation teams, who are often unpaid volunteers with limited time and resources to manage their communities.
Designers should also support a robust, public API for these applications and platforms. As our findings show, not every feature may be imagined in the creation of these platforms, but with a public API, users can drive the creation of custom solutions to unforeseen design problems. Our work suggests that these may be drawn from users unique knowledge of their problems as well as from their knowledge of existing solutions.
Paper Citation: Kiene, Charles, Jialun “Aaron” Jiang, and Benjamin Mako Hill. 2019. “Technological Frames and User Innovation: Exploring Technological Change in Community Moderation Teams.” Proceedings of the ACM: Human-Computer Interaction 3 (CSCW): 44:1-44:23.
Earlier this year, a team led by Kaylea Champion were announced as recipients of a generous grant from the Ford and Sloan Foundations to support research into into peer produced software infrastructure. Now that the project is moving forward in earnest, we’re thrilled to tell you about it.
Rapid Transit. Photo by Anthony Doudt, via flickr. CC BY-NC-ND 2.0
The project is motivated by the fact that peer production communities have produced awesome free (both as in freedom and beer) resources—sites like Wikipedia that gather the world’s knowledge, and software like Linux that enables innovation, connection, commerce, and discovery. Over the last two decades, these resources have become key elements of public digital infrastructure that many of us rely on every day. However, some pieces of digital infrastructure we rely on most remain relatively under-resourced—as security vulnerabilities like Heartbleed in OpenSSL reveal. The grant from Ford and Sloan aims will support a research effort to understand how and why some software packages that are heavily used receive relatively little community support and maintenance.
We’re tackling this challenge by seeking to measure and model patterns of usage, contribution, and quality in a population of free software projects. We’ll then try to identify causes and potential solutions to the challenges of relative underproduction. Throughout, we’ll draw on both insight from the research community and on-the-ground observations from developers and community managers. We aim to create practical guidance that communities and software developers can actually use as well as novel research contributions. Underproduction is, appropriately enough, a challenge that has not gotten much attention from researchers previously, so we’re excited to work on it.
Although Kaylea Champion is leading the project, the team working on the project includes Benjamin Mako Hill, Aaron Shaw, and collective affiliate Morten Warncke-Wang who did pioneering work on underproduction in Wikipedia.
In particular, we be presenting a new paper from the group led by Sneha Narayan titled “All Talk: How Increasing Interpersonal Communication on Wikis May Not Enhance Productivity.” The talk will be on Monday, May 27 in a session from 9:30 to 10:45 in Washington Hilton LL, Holmead as part of a session organized by the ICA Computational Methods section on “Computational Approaches to Health Communication.”
Additionally, Nate is co-organizing a pre-conference at ICA on “Expanding Computational Communication: Towards a Pipeline for Graduate Students and Early Career Scholars” along with Josephine Lukito (UW Madison) and Frederic Hopp (UC Santa Barbara). The pre-conference will be held at American University on Friday May 24th. As part of that workshop, Nate and Jeremy will be giving a presentation on approaches to the study organizational communication that use computational methods.
We look forward to sharing our research and socializing with you at ICA! Please be in touch if you’re around and want to meet up!
Informal online learning communities are one of the most exciting and successful ways to engage young people in technology. As the most successful example of the approach, over 40 million children from around the world have created accounts on the Scratch online community where they learn to code by creating interactive art, games, and stories. However, despite its enormous reach and its focus on inclusiveness, participation in Scratch is not as broad as one would hope. For example, reflecting a trend in the broader computing community, more boys have signed up on the Scratch website than girls.
In a recently published paper, I worked with several colleagues from the Community Data Science Collective to unpack the dynamics of unequal participation by gender in Scratch by looking at whether Scratch users choose to share the projects they create. Our analysis took advantage of the fact that less than a third of projects created in Scratch are ever shared publicly. By never sharing, creators never open themselves to the benefits associated with interaction, feedback, socialization, and learning—all things that research has shown participation in Scratch can support.
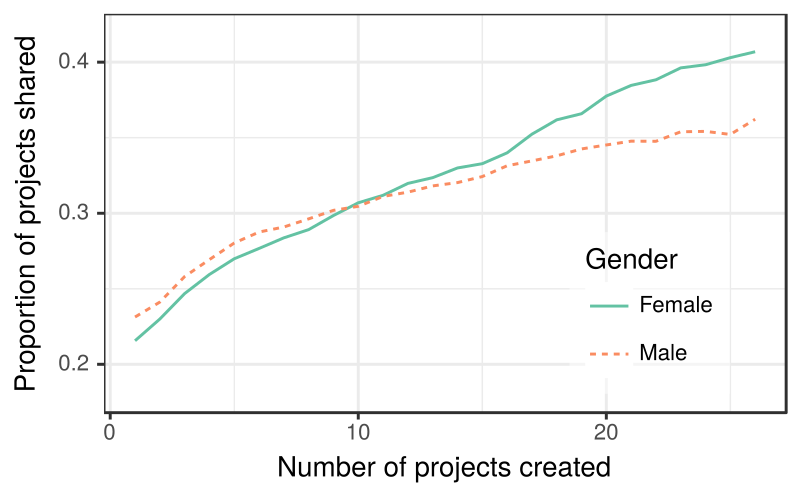
Overall, we found that boys on Scratch share their projects at a slightly higher rate than girls. Digging deeper, we found that this overall average hid an important dynamic that emerged over time. The graph below shows the proportion of Scratch projects shared for male and female Scratch users’ 1st created projects, 2nd created projects, 3rd created projects, and so on. It reflects the fact that although girls share less often initially, this trend flips over time. Experienced girls share much more than often than boys!
Proportion of projects shared by gender across experience levels, measured as the number of projects created, for 1.1 million Scratch users. Projects created by girls are less likely to be shared than those by boys until about the 9th project is created. The relationship is subsequently reversed.
We unpacked this dynamic using a series of statistical models estimated using data from over 5 million projects by over a million Scratch users. This set of analyses echoed our earlier preliminary finding—while girls were less likely to share initially, more experienced girls shared projects at consistently higher rates than boys. We further found that initial differences in sharing between boys and girls could be explained by controlling for differences in project complexity and in the social connectedness of the project creator.
Another surprising finding is that users who had received more positive peer feedback, at least as measured by receipt of “love its” (similar to “likes” on Facebook), were less likely to share their subsequent projects than users who had received less. This relation was especially strong for boys and for more experienced Scratch users. We speculate that this could be due to a phenomenon known in the music industry as “sophomore album syndrome” or “second album syndrome”—a term used to describe a musician who has had a successful first album but struggles to produce a second because of increased pressure and expectations caused by their previous success
Online anonymity often gets a bad rap and complaints about antisocial behavior from anonymous Internet users are as old as the Internet itself. On the other hand, research has shown that many Internet users seek out anonymity to protect their privacy while contributing things of value. Should people seeking to contribute to open collaboration projects like open source software and citizen science projects be required to give up identifying information in order to participate?
We conducted a two-part study to better understand how open collaboration projects balance the threats of bad behavior with the goal of respecting contributors’ expectations of privacy. First, we interviewed eleven people from five different open collaboration “service providers” to understand what threats they perceive to their projects’ mission and how these threats shape privacy and security decisions when it comes to anonymous contributions. Second, we analyzed discussions about anonymous contributors on publicly available logs of the English language Wikipedia mailing list from 2010 to 2017.
In the interview study, we identified three themes that pervaded discussions of perceived threats. These included threats to:
community norms, such as harrassment;
sustaining participation, such as loss of or failure to attract volunteers; and
contribution quality, low-quality contributions drain community resources.
We found that open collaboration providers were most concerned with lowering barriers to participation to attract new contributors. This makes sense given that newbies are the lifeblood of open collaboration communities. We also found that service providers thought of anonymous contributions as a way of offering low barriers to participation, not as a way of helping contributors manage their privacy. They imagined that anonymous contributors who wanted to remain in the community would eventually become full participants by registering for an account and creating an identity on the site. This assumption was evident in policies and technical features of collaboration platforms that barred anonymous contributors from participating in discussions, receiving customized suggestions, or from contributing at all in some circumstances. In our second study of the English language Wikipedia public email listserv, we discovered that the perspectives we encountered in interviews also dominated discussions of anonymity on Wikipedia. In both studies, we found that anonymous contributors were seen as “second-class citizens.”
This is not the way anonymous contributors see themselves. In a study we published two years ago, we interviewed people who sought out privacy when contributing to open collaboration projects. Our subjects expressed fears like being doxed, shot at, losing their job, or harassed. Some were worried about doing or viewing things online that violated censorship laws in their home country. The difference between the way that anonymity seekers see themselves and the way they are seen by service providers was striking.
One cause of this divergence in perceptions around anonymous contributors uncovered by our new paper is that people who seek out anonymity are not able to participate fully in the process of discussing and articulating norms and policies around anonymous contribution. People whose anonymity needs means they cannot participate in general cannot participate in the discussions that determine who can participate.
We conclude our paper with the observation that, although social norms have played an important role in HCI research, relying on them as a yardstick for measuring privacy expectations may leave out important minority experiences whose privacy concerns keep them from participating in the first place. In online communities like open collaboration projects, social norms may best reflect the most privileged and central users of a system while ignoring the most vulnerable
Both this blog post and the paper, Privacy, Anonymity, and Perceived Risk in Open Collaboration: A Study of Service Providers, was written by Nora McDonald, Benjamin Mako Hill, Rachel Greenstadt, and Andrea Forte and will be published in the Proceedings of the 2019 ACM CHI Conference on Human Factors in Computing Systems next week. The paper will be presented at the CHI conference in Glasgow, UK on Wednesday May 8, 2019. The work was supported by the National Science Foundation (awards CNS-1703736 and CNS-1703049).