Wiki Education (a.k.a., WikiEdu) is an independent non-profit organization that promotes the integration of Wikipedia into education and classrooms. In pursuit of this mission, WikiEdu has created incredible resources for students and instructors, including tools that facilitate classroom assignments where students create and improve Wikipedia articles.
Wiki Education is great! (And the feeling seems to be mutual based on their recent blogposts)
In courses at both Northwestern and the University of Washington, CDSC faculty and students have offered courses with Wikipedia assignments for over a decade. In the past two weeks, WikiEdu has featured the most recent instances of these courses on their blog.
The first WikiEdu post celebrated the work of a team of Northwestern students that included Carl Colglazier (TSB and CDSC Ph.D. student) and Hannah Yang (undergraduate Communication Studies major and former CDSC research assistant). The team, all members of the Online Communities & Crowds course I taught with CDSC Ph.D. student Sohyeon Hwang in Winter 2022, overhauled an article on Inclusive design in English Wikipedia. Since the article’s initial publication back in March, other Wikipedia editors have improved it further and it has attracted over 10,000 pageviews. Amazing work, team!
The second post celebrates UW Communication doctoral student Kaylea Champion, recipient of an Outstanding Teaching Award from the Communication Department on the strength of her work in another Winter 2022 undergraduate course on Online Communities (also taught by Benjamin Mako Hill) that features a Wikipedia assignment. Several of Kaylea’s students thought so highly of her work in the course that they collaborated in nominating her for the award. Kaylea enjoyed the experience enough that she’s about to offer the course again as the lead instructor at UW this upcoming Winter term. I should also note that Kaylea has been nominated for a university-wide award, but we won’t know the outcome of that process for a while yet. Congratulations, Kaylea!
The public recognition of CDSC students and teaching is gratifying and provides a great reminder of why assignments that ask students to edit Wikipedia are so valuable in the first place. Most fundamentally, editing Wikipedia engages students in the production of public, open access knowledge resources that serve a much greater and broader purpose than your typical term paper, pop quiz, or exam. When students develop encyclopedic materials on topics of their interest, motivated undergraduates like Hannah Yang can directly connect coursework with practical, real-world concerns in ways that build on the expertise of graduate students like Carl Colglazier. This kind of school work creates unusually high impact products. Kaylea Champion puts the idea eloquently in that WikiEdu post: “Instead of locking away my synthesis efforts in a paper no one but my instructors would read, the Wikipedia assignment pushed me to address the public.”
Just think, how many people ever read a word of most college (or high school or graduate school) term papers? By contrast, the Wikipedia articles created by our students have routinely been viewed over 100,000 times in aggregate by the end of the term in which we offer the course. Extrapolate this out over a decade and our students’ work has likely been read millions of times by now. As with other content on Wikipedia, this work will shape public discourse, including judicial decisions, scientific research, search engine results, and more. There’s absolutely nothing academic about that!
We had another Science of Community Dialogue! This most recent one was themed around informal learning, talking about communities as informal learning spaces and the sorts of tools and habits communities can adopt to help learners, mentors, and newcomers. We had presentations from Ruijia (Regina) Cheng (University of Washington, CDSC) and Dr. Denae Ford Robinson (Microsoft, University of Washington).
Regina Cheng covered three related research projects and relevant findings:
Ruijia Cheng and Benjamin Mako Hill. 2022. “Many Destinations, Many Pathways: A Quantitative Analysis of Legitimate Peripheral Participation in Scratch.” https://doi.org/10.1145/3555106
Ruijia Cheng, Sayamindu Dasgupta, and Benjamin Mako Hill. 2022. “How Interest-Driven Content Creation Shapes Opportunities for Informal Learning in Scratch: A Case Study on Novices’ Use of Data Structures.” https://doi.org/10.1145/3491102.3502124
Ruijia Cheng and Jenna Frens. 2022. “Feedback Exchange and Online Affinity: A Case Study of Online Fanfiction Writers.” https://doi.org/10.1145/3555127
Participants collaboratively put together three takeaways from Regina Cheng’s presentation.
We often talk about wanting to support “learning” in some general sense, but a critically important question to ask is “learning about what.” Let’s say we want people to learn three things A, B, and C. The kinds of actions or behaviors that support learning goal A often have no effect on B, and C. And sometimes they actively hurt it. We need to be more specific about what we want people to learn because there are tradeoffs.
Social support is wonderful in that users create examples and resources and answer questions. But it also has this narrowing effect. There’s a piling-on effect that makes it easier and easier (and more likely!) to learn the things that folks have learned before and less likely that people learn anything else.
Feedback is not about information transfer, it’s about relationships. To best promote learning, we should create rich, legitimate, inclusive social environment. These are perhaps good things to do anyway.
Dr. Denae Ford Robinson focused on free and open source software (FOSS) communities as a case study of learning communities. She covered theory, needs, and demonstrated tools designed to help with the mentorship and the learning process.
Community-driven settings like FOSS (and social-good oriented projects in particular) rely enormously on volunteers and/or people opting into participation in ways that create huge challenges related to promoting project sustainability: the most active participants are overloaded in a way that is a recipe for burnout.
The path to sustainability involves attracting, retaining, and then sustaining contributions and understanding these processes as both (a) part of the lifecycle of a user and (b) part of a set of dynamics and lifecycle within the community (e.g., dynamics of community growth).
Approach 1 involves providing new information to help maintainers understand how things are going in their communities. A lack of insight and easy access to data is a cause of inefficiency and burnout.
Approach 2 involves making specific, structured recommendations to maintainers based on the experience of others in the past to do things like add tags and to shape behavior.
Approach 3 involves automating aspects of identifying and recognizing work (and perhaps other tasks) as a way of promoting newcomer experiences and reducing the load on maintainers for doing that.
This event and some of the research presented in it were supported by multiple awards from the National Science Foundation (DGE-1842165; IIS-2045055; IIS-1908850; IIS-1910202), Northwestern University, the University of Washington, and Purdue University.
Thousands of widely used online communities are designed to promote learning. Although some rely on formal educational approaches like lesson plans, curriculum, and tests, many of the most successful learning communities online are structured as what scholars call a community of practice (CoP). In CoPs, members mentor and apprentice with each other (both formally and informally) while working toward a common interest or goal. For example, the Scratch online community is a CoP where millions of young people share and collaborate on programming projects.
Despite an enormous amount of attention paid to online CoPs, there is still a lot of disagreement about the best ways to promote learning in them. One source of disagreement stems from the fact that participants in CoPs are learning a number of different kinds of things and designers are often trying to support many types of learning at once. In a new paper that I’ve published—and that I will be presenting at CSCW this week—I conduct quantitative analyses on data from Scratch to show that there is a complex set of learning pathways at play in CoPs like Scratch. Types of participation that are associated with some important kinds of learning are often unrelated to, or even negatively associated with, other important types of learning outcomes.
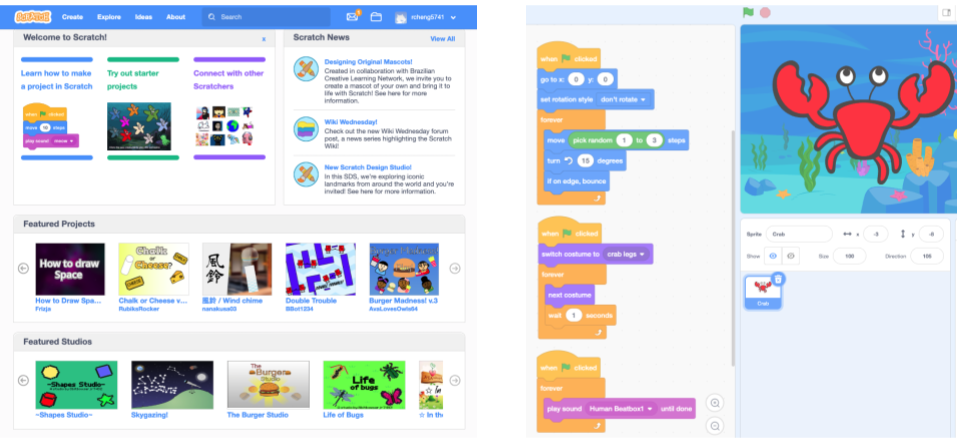
The Scratch online community (left) and an example of a programming project in Scratch (right).
So what exactly are people learning in CoPs? We dug into the CoP literature and identified three major types of learning outcomes:
Learning about the domain, which refers to learning knowledge and skills for the core tasks necessary for achieving the explicit goal in the community. In Scratch, this is learning to code.
Learning about the community, which means the development of identity as a community member, forming relationships, affinities, and a sense of belonging. In Scratch, this involves learning to interact with others users and developing an identity as a community member.
Learning about the practice, which means adopting community specific values, such as the style of contribution that will be accepted and appreciated by its members. In Scratch, this means becoming a valued and respected contributor to the community.
So what types of participation might contribute to learning in a CoP? We identified several different types of newcomers’ participation that may support learning:
Contribution to core tasks which involves direct work towards the community’s explicit goal. In Scratch, this often involves making original programming projects.
Engagement with practice proxies which involves observing and participating in others’ work practices. In Scratch, this might mean remixing others’ projects by making changes and building on existing code.
Feedback exchange with community members about their contributions. In Scratch, this often involves writing comments on others’ projects.
Social bonding with community members. In Scratch, this can involve “friending” others, which allows a user to follow others’ projects and updates.
A visual representation of our study design.
We conducted a quantitative analysis on how the different types of newcomer participation contribute to the different learning outcomes. In other words, we tested for the presence/absence and the direction of the relationships (shown as the orange arrows) between each of the learning outcomes on the top of the figure and each of the types of newcomer participation on the bottom. To conduct these tests, we used data from Scratch to construct a user level dataset with proxy measures for each type of learning and type of newcomer participation as well as a series of important control variables. All the technical details about the measures and models are in the paper.
Overall, what we found was a series of complex trade-offs that suggest the kinds of things that support one type of learning frequently do not support others. For example, we found that contribution to core tasks as a newcomer is positively associated with learning about the domain in the long term, but negatively associated with learning about the community and its practices. We found that engagement with practice proxies as a newcomer is negatively associated with long-term learning about the domain and the community. Engaging in feedback exchange and social bonding as a newcomer, on the other hand, are positively associated with learning about the community and its practice.
Our findings indicate that there are no easy solutions: different types of newcomer participation provide varying support for different learning outcomes. What is productive for some types of learning outcomes can be unhelpful for others, and vice versa. For example, although social features like feedback mechanisms and systems for creating social bonds may not be a primary focus of many learning systems, they could be implemented to help users develop a sense of belonging in the community and learn about community specific values. At the same time, while contributing to core tasks may help with domain learning, direct contribution may often be too difficult and might discourage newcomers from staying in the community and learn about its values.
The paper and this blog post are collaborative work between Ruijia “Regina” Cheng and Benjamin Mako Hill. The paper is being published this month(open access) in the Proceedings of the ACM on Human-Computer Interaction The full citation for this paper is: Ruijia Cheng and Benjamin Mako Hill. 2022. Many Destinations, Many Pathways: A Quantitative Analysis of Legitimate Peripheral Participation in Scratch. Proc. ACM Hum.-Comput. Interact. 6, CSCW2, Article 381 (November 2022), 26 pages https://doi.org/10.1145/3555106
The paper is also available as an arXiv preprint and in the ACM Digital Library. The paper is being presented several times at the Virtual CSCW conference taking place in November 2022. Both Regina and Mako are happy to answer questions over email, in the comments on this blog post, or at the one remaining presentation slot at the CSCW conference on November 16th at 8-9pm Pacific Time.
CDSC members Molly deBlanc and Kaylea Champion will be presenting at this year’s Aaron Swartz Day and International Hackathon. Molly will speak at 2:50 p.m. Pacific (talk title: My (Extended) Body, My Choice). Kaylea will speak at 3:15 p.m. Pacific (talk title: The Value of Anonymity: Evidence from Wikipedia). Registration and live stream details are available here: https://www.aaronswartzday.org/
If you’re attending ACM-CSCW this year, you are warmly invited to join CDSC members during our talks and other scheduled events. CSCW is not only virtual but spread across multiple weeks and offering sessions multiple times to accommodate timezones. We hope to see you there — we are eager to discuss our work with you!
Tuesday, November 8
6pm-7pm Pacific, “No Community Can Do Everything: Why People Participate in Similar Online Communities” Details at: https://programs.sigchi.org/cscw/2022/index/content/87413 By: Nathan Te Blunthuis, Charles Kiene, Isabella Brown, Nicole McGinnis, Laura Levi, Benjamin Mako Hill
3am-4am Pacific “The Risks, Benefits, and Consequences of Prepublication Moderation: Evidence from 17 Wikipedia Language Editions” Details at: https://programs.sigchi.org/cscw/2022/index/content/87945 By:Chau Tran, Kaylea Champion, Benjamin Mako Hill, Rachel Greenstadt
Friday, November 11
8am-9am Pacific. Many Destinations, Many Pathways: A Quantitative Analysis of Legitimate Peripheral Participation in Scratch. Details at: https://programs.sigchi.org/cscw/2022/index/content/87487 By: Ruijia Cheng, Benjamin Mako Hill
3pm-4pm Pacific “The Risks, Benefits, and Consequences of Prepublication Moderation: Evidence from 17 Wikipedia Language Editions” Details at: https://programs.sigchi.org/cscw/2022/index/content/87945 By: Chau Tran, Kaylea Champion, Benjamin Mako Hill, Rachel Greenstadt
8pm-9pm Pacific. Many Destinations, Many Pathways: A Quantitative Analysis of Legitimate Peripheral Participation in Scratch. Details at: https://programs.sigchi.org/cscw/2022/index/content/87487 By: Ruijia Cheng, Benjamin Mako Hill
Friday, November 18
6am-7am Pacific, “No Community Can Do Everything: Why People Participate in Similar Online Communities” Details at: https://programs.sigchi.org/cscw/2022/index/content/87413 By: Nathan Te Blunthuis, Charles Kiene, Isabella Brown, Nicole McGinnis, Laura Levi, Benjamin Mako Hill
And there’s more…
CDSC members and affiliates are involved in CSCW beyond these public presentations. Nicholas Vincent, Sohyeon Hwang, and Sneha Narayan are part of the organizing team for the “Ethical Tensions, Norms, and Directions in the Extraction of Online Volunteer Work” workshop, where Molly de Blanc is scheduled to present and Kaylea Champion will be giving a lightning talk. Katherina Kloppenborg and Kaylea Champion are presenting in the Doctoral Consortium.
It’s Ph.D. application season and the Community Data Science Collective is recruiting! As always, we are looking for talented people to join our research group. Applying to one of the Ph.D. programs that the CDSC faculty members are affiliated with is a great way to get involved in research on communities, collaboration, and peer production.
Because we know that you may have questions for us that are not answered in this webpage, we will be hosting a panel discussion and Q&A about the CDSC and Ph.D. opportunities on October 20 at 7:30pm UTC (3:30pm US Eastern, 2:30pm US Central, 12:30pm US Pacific). You can register online.
This post provides a very brief run-down on the CDSC, the different universities and Ph.D. programs our faculty members are affiliated with, and some general ideas about what we’re looking for when we review Ph.D. applications.
Group photo of the collective at a recent virtual retreat.
What are these different Ph.D. programs? Why would I choose one over the other?
This year the group includes three faculty principal investigators (PIs) who are actively recruiting PhD students: Aaron Shaw (Northwestern University), Benjamin Mako Hill (University of Washington in Seattle), and Jeremy Foote (Purdue University). Each of these PIs advise Ph.D. students in Ph.D. programs at their respective universities. Our programs are each described below.
Although we often work together on research and serve as co-advisors to students in each others’ projects, each faculty person has specific areas of expertise and interests. The reasons you might choose to apply to one Ph.D. program or to work with a specific faculty member could include factors like your previous training, career goals, and the alignment of your specific research interests with our respective skills.
At the same time, a great thing about the CDSC is that we all collaborate and regularly co-advise students across our respective campuses, so the choice to apply to or attend one program does not prevent you from accessing the expertise of our whole group. But please keep in mind that our different Ph.D. programs have different application deadlines, requirements, and procedures!
Who is actively recruiting this year?
If you are interested in applying to any of the programs, we strongly encourage you to reach out the specific faculty in that program before submitting an application.
Ph.D. Advisors
Benjamin Mako Hill
Benjamin Mako Hill is an Associate Professor of Communication at the University of Washington. He is also an Adjunct Assistant Professor at UW’s Department of Human-Centered Design and Engineering (HCDE), Computer Science and Engineering (CSE) and Information School. Although many of Mako’s students are in the Department of Communication, he has also advised students in all three other departments—although he typically has more limited ability to admit students into those programs on his own and usually does so with a co-advisor in those departments. Mako’s research focuses on population-level studies of peer production projects, computational social science, efforts to democratize data science, and informal learning. Mako has also put together a webpage for prospective graduate students with some useful links and information..
AaronShaw is an Associate Professor in the Department of Communication Studies at Northwestern. This year, he’s also the “Scholar in Residence” for King County, Washington. In terms of Ph.D. programs, Aaron’s primary affiliations are with the Media, Technology and Society (MTS) and the Technology and Social Behavior (TSB) Ph.D. programs (please note: the TSB program is a joint degree between Communication and Computer Science). Aaron also has a courtesy appointment in the Sociology Department at Northwestern, but he has not directly supervised any Ph.D. advisees in that department (yet). Aaron’s current projects focus on comparative analysis of the organization of peer production communities and social computing projects, participation inequalities in online communities, and collaborative organizing in pursuit of public goods.
Jeremy Foote
Jeremy Foote is an Assistant Professor at the Brian Lamb School of Communication at Purdue University. He is affiliated with the Organizational Communication and Media, Technology, and Society programs. Jeremy’s current research focuses on how individuals decide when and in what ways to contribute to online communities, how communities change the people who participate in them, and how both of those processes can help us to understand which things become popular and influential. Most of his research is done using data science methods and agent-based simulations.
What do you look for in Ph.D. applicants?
There’s no easy or singular answer to this. In general, we look for curious, intelligent people driven to develop original research projects that advance scientific and practical understanding of topics that intersect with any of our collective research interests.
To get an idea of the interests and experiences present in the group, read our respective bios and CVs (follow the links above to our personal websites). Specific skills that we and our students tend to use on a regular basis include consuming and producing social science and/or social computing (human-computer interaction) research; applied statistics and statistical computing, various empirical research methods, social theory and cultural studies, and more.
Formal qualifications that speak to similar skills and show up in your resume, transcripts, or work history are great, but we are much more interested in your capacity to learn, think, write, analyze, and/or code effectively than in your credentials, test scores, grades, or previous affiliations. It’s graduate school and we do not expect you to show up knowing how to do all the things already.
Intellectual creativity, persistence, and a willingness to acquire new skills and problem-solve matter a lot. We think doctoral education is less about executing tasks that someone else hands you and more about learning how to identify a new, important problem; develop an appropriate approach to solving it; and explain all of the above and why it matters so that other people can learn from you in the future. Evidence that you can or at least want to do these things is critical. Indications that you can also play well with others and would make a generous, friendly colleague are really important too.
All of this is to say, we do not have any one trait or skill set we look for in prospective students. We strive to be inclusive along every possible dimension. Each person who has joined our group has contributed unique skills and experiences as well as their own personal interests. We want our future students and colleagues to do the same.
Now what?
Still not sure whether or how your interests might fit with the group? Still have questions? Still reading and just don’t want to stop? Follow the links above for more information. Feel free to send at least one of us an email. We are happy to try to answer your questions and always eager to chat. You can also join our panel discussion on October 20 at 3:30pm ET (UTC-5).
CSCW 2021 introduced Lab Speed Dating wherein labs were matched and given an hour to get to know each other. Sohyeon Hwang organized our first lab date. It was so much fun we decided to go on more in order to meet other groups. I wanted to share a bit about this and our process in case you are interested in trying it out or want to have a meetup with us.
After the initial CSCW Lab Date we made a very long list of other labs we want to meet and have (slowly) been inviting them to come by. We also included individual researchers, people who collaborate in smaller, informal groups, co-authors, and corporate research teams.
We use our “softblock” to schedule meetings, rather than finding a new time for each meeting. The CDSC maintains a softblock, which is a block of time for whatever comes up, one-off meetings we need to schedule, and co-working sessions. (Today I am using the softblock to write this blog post!)
We are pretty open to different structures for our lab dates. So far the ones with full labs have been divided into two parts: 1) everyone introduces themselves as briefly as we can manage and then 2) we break out into small groups for short periods of time to talk. We try to cycle through 2-3 of these breakouts, depending on how many people are in attendance. When meeting with individuals, our guests typically present a piece of work that we workshop or discussed their interests in a more general sense and we talk about them as a whole group. We are open to other models, but nothing has come up yet.
Blocks have focused around networking and getting to know other researchers on a professional level. Because we have been attending fewer in-person events, we have had fewer chances to meet new people. Even at events it can be hard to connect with the people you want to meet and it is very hard (for us) to have everyone from the CDSC in a space together with another group.
If you are interested in going on a lab date with us, you can message me on IRC or email me (details here). We have a lot of open spots for the rest of the quarter and one of them could be yours!
We recently held our second Community Dialogue around the theme of anonymity and privacy. Kaylea Champion presented on the role of anonymity in peer-contribution communities. Dr. Shruti Sannon joined us from the University of Michigan and talked about privacy in the gig economy.
What’s Anonymity Worth (Kaylea Champion)
Anonymity can protect and empower contributors in communities. Anonymity can make people feel safer or actually be safer. For example: Wikipedia editors who are working on controversial pages within contested geographies may be safer when they are able to contribute anonymously. Anonymous contribution is not without problems, as it can also empower trolls, harassers, and other bad actors. For more details, and actions you can take or policies to recommend within your communities, watch the video of Kaylea Champion’s presentation below.
Privacy and Surveillance in the Gig Economy (Dr. Shruti Sannon)
Gig workers can be asked or coerced to give up privacy in exchange for money through the design of the gig platforms they are using or by request of customers. Gig workers also use surveillance tools as a means of protecting themselves — some ride share drivers have cameras in their cars for this purpose. Dr. Sannon shared the broader implications of this situation, and what it can mean outside of the gig economy. To learn more, watch the video below.
Join us!
You can subscribe to our mailing list! We’ll be making announcements about future events there. It is a low volume mailing list.
Acknowledgements
Thanks to speakers Kaylea Champion and Shruti Sannon. The vision for this event borrows from the User and Open Innovation workshops organized by Eric von Hippel and colleagues, as well as others. This event and the research presented in it were supported by multiple awards from the National Science Foundation (DGE-1842165; IIS-2045055; IIS-1908850; IIS-1910202), Northwestern University, the University of Washington, and Purdue University.
Systems theory is a broad and multidisciplinary scientific approach that studies how things (molecules or cells or organs or people or companies) interact with each other. It argues that understanding how something works requires understanding its relationships and interdependencies.
For example, if we want to predict whether a new online community will grow, an individual perspective might focus on who the founder is, what software it is running on, how well it is designed, etc. A systems approach would argue that it is at least as important to understand things like how many similar communities there are, how active they are, and whether the platform is growing or shrinking.
In a paper just published in Media and Communication, I (Jeremy) argue that 1) it is particularly important to use a systems lens to study online communities, 2) that online communities provide ideal data for taking these approaches, and 3) that there is already really neat research in this area and there should be more of it.
The role of platforms
So, why is it so important to study online communities as interdependent “systems”? The first reason is that many online communities have a really important interdependence with the platforms that they run on. Platforms like Reddit or Facebook provide the servers and software for millions of communities, which are run mostly independently by the community managers and moderators.
However, this is an ambivalent relationship and often the goals and desires of at least some moderators are at odds with those of the platform, and things like community bans from the platform side or protests from the community side are not uncommon. The ways that platform decisions influence communities and how communities can work together to influence platforms are inherently systems questions.
Low barriers to entry and exit
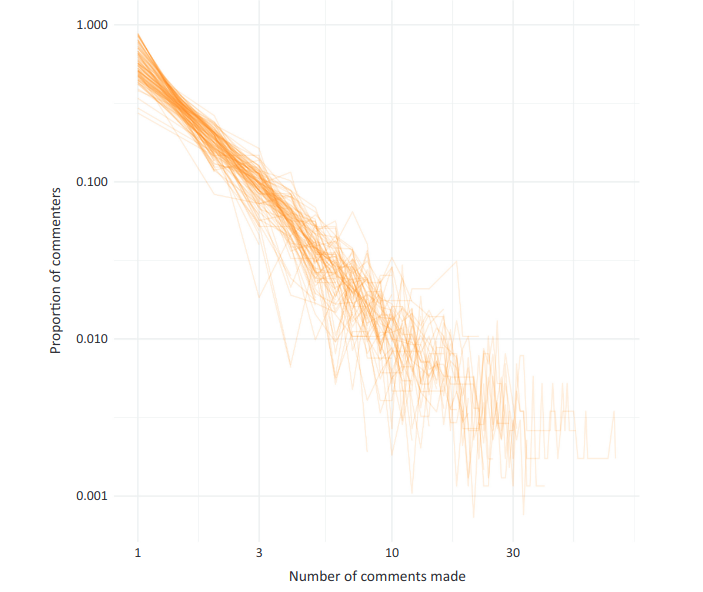
A second feature of online communities is the relative ease with which people can join or leave them. Unlike offline groups, which at least require participants to get dressed, do their hair, and show up somewhere, online community participants can participate in an online community literally within seconds of knowing that it exists.
Similarly, people can leave incredibly easily, and most people do. This figure shows the number of comments made per person across 100 randomly selected subreddits (each line represents a subreddit; axes are both log-scaled). In every case, the vast majority of people only commented once while a few people made many comments.
Fuzzy boundaries
Finally, it’s often really difficult to draw clear boundaries around where one online community ends and another begins. For example, is all of Wikipedia one “community”? It might make sense to think of a language edition, a WikiProject, or even a single page as a community, and researchers have done all of the above. Even on platforms like Reddit, where there is a clearl delineation between communities, there are dependencies, with people and conversations moving across and between communities on similar topics.
In other words, online communities are semi-autonomous, interdependent, contingent organizations, deeply influenced by their environments. Online community scholars have often ignored this larger context, but systems theory gives us a rich set of tools for studying these interdependencies. One reason that it is so ideal is because online communities provide ideal data.
Data from Online Communities
Systems theory is not new – many of the main concepts were developed in the 1950s and 1960s or earlier. Organizational communication researchers saw how applicable these ideas were, and manyresearchersproposed treating organizations as systems.
However, it was really tough to get the data needed to do systems-based research. To study a group or organization as a system, you need to know about not only the internal workings of the group, but how it relates to other groups, how it is influenced by and influences its environment, etc. Gathering data about even one group was difficult and expensive; getting the data to study many groups and how they interact with each other over time was impossible.
The internet has entered the chat
Online communities provide the kind of data that these earlier researchers could have only dreamed of. Instead of data about one organization, platforms store data about thousands of organizations. And this is not just high-level data about activity levels or participation; on the contrary, we often have longitudinal, full-text conversations of millions of people as they interact within and move between communities.
Systems Approaches
In part, this article is a call for researchers to think more explicitly about online communities as systems, and to apply systems theory as a way of understanding how online communities work and how we can design research projects to understand them better. It is also an attempt to highlight strands of research that are already doing this. In the paper, I talk about four: Community Comparisons and Interactions, Individual Trajectories, Cross-level Mechanisms, and Simulating Emergent Behavior. Here, I’ll focus on just two.
Individual Trajectories
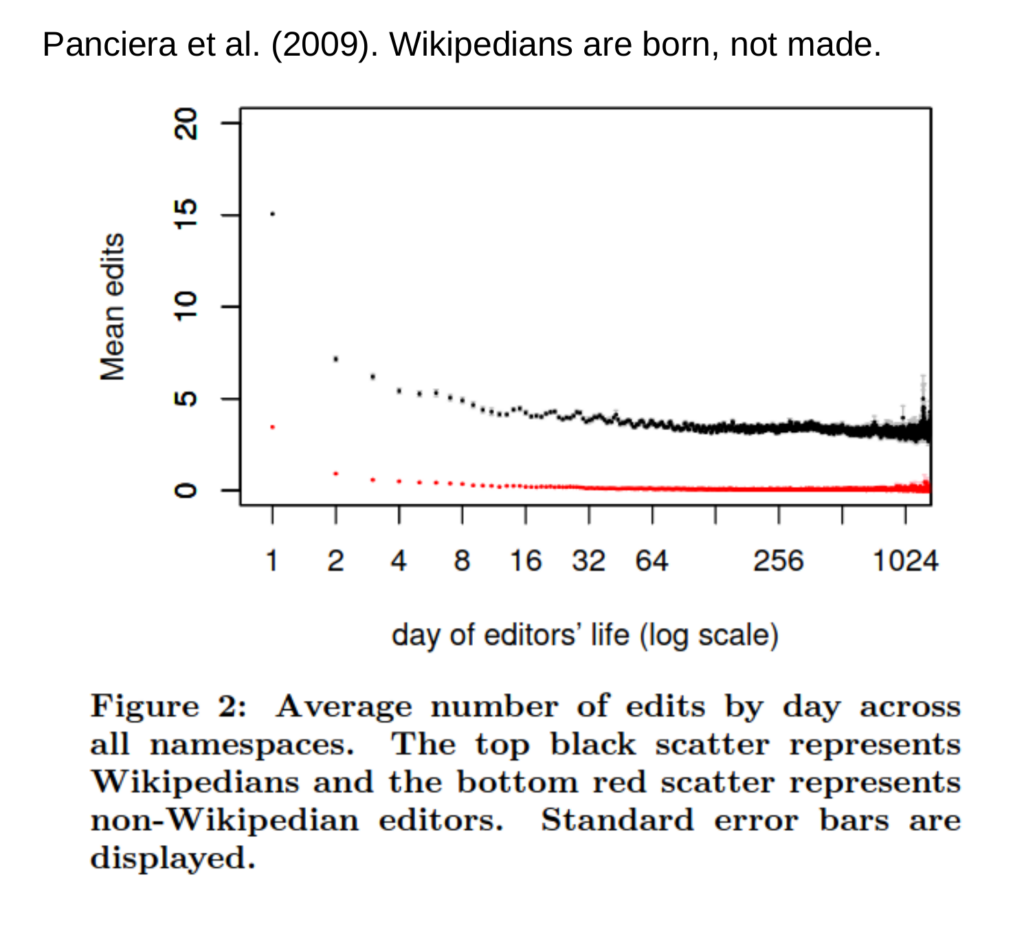
Figure from Panciera, K., Halfaker, A., & Terveen, L. (2009). Wikipedians are born, not made: A study of power editors on Wikipedia. Proceedings of the ACM 2009 International Conference on Supporting Group Work, 51–60. https://doi.org/10.1145/1531674.1531682
The first is what I call “Individual Trajectories”. In this approach, researchers can look at how individual people behave across a platform. One of the neat things about having longitudinal, unobtrusively collected data is that we can identify something interesting about users and go “back in time” to look for differences in earlier behavior. For example, in the plot above, Panciera et al. identified people who became active Wikipedia editors; they then went back and looked at how their behavior differed from typical editors from their early days on the site.
Researchers could and should do more work that looks at how people move between communities, and how communities influence the behavior of their members.
Simulating Emergent Behavior
The second approach is to use simulations to study emergent behaviors. Agent-based modeling software like NetLogo or Mesa allows researchers to create virtual worlds, where computational “agents” act according to theories of how the world works. Many communication theories make predictions about how individual‐level behavior produces higher‐level patterns, often through feedback loops (e.g., the Spiral of Silence theory). If agent-based models don’t produce those patterns, then we know that something about the theory—or its computational representation—is wrong.
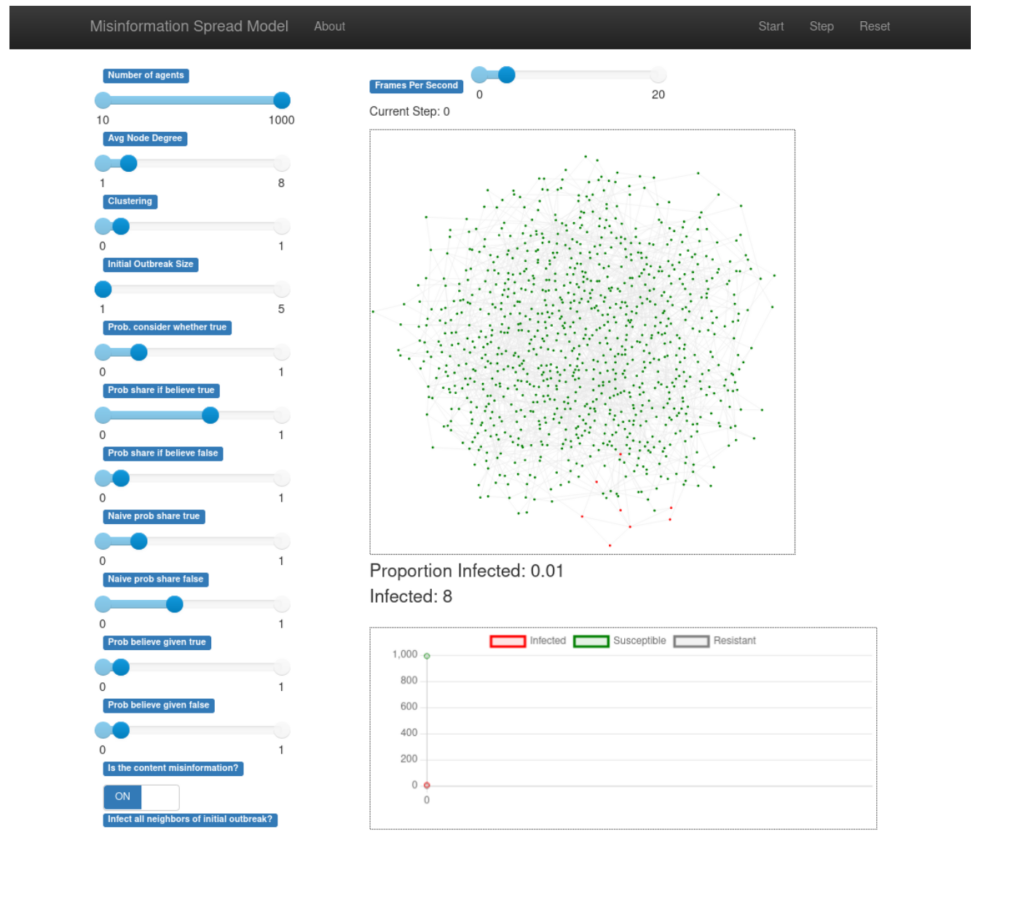
Model of misinformation spread, from Hu et al. (under review)
Agent-based modeling has received some attention from communication researchers lately, including a wonderful special issue was recently published in Communication Methods and Measures; the editorial article makes some great arguments for the promise and benefits of simulations for communication research.
New Opportunities
It is a really exciting time to be a computational social scientist, especially one that is interested in online organizations and organizing. We have only scratched the surface of what we can learn from the data that is pouring down around us, especially when it comes to systems theory questions. Tools, methods, and computational advances are constantly evolving and opening up new avenues of research.
Of course, taking advantage of these data sources and computational advances requires a different set of skills than Communication departments have traditionally focused on, and complicated, large-scale analyses require the use of supercomputers and extensive computational expertise.
However, there are many approaches like agent-based modeling or simple web scraping that can be taught to graduate students in one or two semesters, and open up lots of possibilities for doing this kind of research.
I’d love to talk more about these ideas—please reach out, or if you are coming to ICA, come talk to me!
The International Communication Association (ICA)’s 72nd annual conference is coming up in just a couple of weeks. This year, the conference takes place in Paris and a subset of our collective is flying out to present work in person. We are looking forward to meeting up, talking research, and eating croissants. À bientôt!
ICA takes place from Thursday, May 26th to Monday, May 30th, and we are presenting a total of ten (!!) times. All presentations given by members of the collective are scheduled between Friday and Sunday.
Friday
We start off with a presentation by Nathan TeBlunthuis on Friday at 11.00 AM, in Room 351 M (Palais des Congres). In a high-density paper session on Computational Approaches to Online Communities, Nate will present a paper entitled “Dynamics of Ecological Adaptation in Online Communities.”
Later that same day, at 3.30 PM in the Amphitheatre Havana (level 3; Palais des Congres), Carl Colglazier will discuss a paper that he collaborated on with Nick Diakopoulos: “Predictive Models in News Coverage of the COVID-19 Pandemic in the U.S.” This paper session is part of the ICA division Journalism Studies.
Saturday
On Saturday, Floor Fiers will present in the paper session “Impression Management Online: FabriCATing An Image.” Their project, which they wrote with Nathan Walter, discusses “Comments on Airbnb and the Potential for Racial Bias” at 2.00 PM in Regency 1 (Hyatt).
Shortly after, that same afternoon, you’ll find two of our poster presentations at 5.00 PM in the Exhibit Hall (Havana; Palais des Congres, level 3). In one of them, Jeremy Foote will discuss his take on “a systems approach to studying online communities.”
The other poster, presented at the same time and place, is by Kaylea Champion and Benjamin Mako Hill on “Resisting Taboo in the Collaborative Production of Knowledge: Evidence from Wikipedia.”
Sunday
Most of our presentations are on the fourth day of the conference. At 9.30 AM, we’ll be presenting in three locations at the same time! First, Floor will discuss their paper “Inequality and Discrimination in the Online Labor Market: a Scoping Review” in Room 311+312 (Palais des Congres). This presentation is part of the paper session “All Things Are Not Equal: CompliCATions From Digital Inequalities.”
Second, Carl will present work on behalf of himself, Aaron Shaw, and Benjamin Mako Hill during a high-density paper session in Room 242A (Palais des Congres). The title of their project is “Extended Abstract: Exhaustive Longitudinal Trace Data From Over 70,000 Wiki.”
Lastly, at the same time in Room 352B (Palais des Congres), Jeremy will present an interview study entitled “What Communication Supports Multifunctional Public Goods in Organizations? Using Agent-Based Modeling to Explore Differential Uses of Enterprise Social Media.” Jeremy’s co-authors on this paper are Jeffrey Treem and Bart van den Hooff.
On Sunday afternoon, at 3.30 PM in Room 311+312 (Palais des Congres), Tiwaladeoluwa Adekunle will talk about a qualitative project she collaborated on with Jeremy, Nate, and Laura Nelson: “Co-Creating Risk Online: Exploring Conceptualizations of COVID-19 Risk in Ideologically Distinct Online Communities.”
We will finish off our ICA 2022 presentations at 5.00 PM in Room 313+314 (Palais des Congres), where Kaylea will present on behalf of Isabella Brown, Lucy Bao, Jacinta Harshe, and Mako. The title of their paper is “Making Sense of Covid-19: Search Results and Information Providers”.
We look forward to sharing our research and connecting with you at ICA!