Millions of young people from around the world are learning to code. Often, during their learning experiences, these youth are using visual block-based programming languages like Scratch, App Inventor, and Code.org Studio. In block-based programming languages, coders manipulate visual, snap-together blocks that represent code constructs instead of textual symbols and commands that are found in more traditional programming languages.
The textual symbols used in nearly all non-block-based programming languages are drawn from English—consider “if” statements and “for” loops for common examples. Keywords in block-based languages, on the other hand, are often translated into different human languages. For example, depending on the language preference of the user, an identical set of computing instructions in Scratch can be represented in many different human languages:
![]()
Although my research with Benjamin Mako Hill focuses on learning, both Mako and I worked on local language technologies before coming back to academia. As a result, we were both interested in how the increasing translation of programming languages might be making it easier for non-English speaking kids to learn to code.
After all, a large body of education research has shown that early-stage education is more effective when instruction is in the language that the learner speaks at home. Based on this research, we hypothesized that children learning to code with block-based programming languages translated to their mother-tongues will have better learning outcomes than children using the blocks in English.
We sought to test this hypothesis in Scratch, an informal learning community built around a block-based programming language. We were helped by the fact that Scratch is translated into many languages and has a large number of learners from around the world.
To measure learning, we built on some of our our own previous work and looked at learners’ cumulative block repertoires—similar to a code vocabulary. By observing a learner’s cumulative block repertoire over time, we can measure how quickly their code vocabulary is growing.
Using this data, we compared the rate of growth of cumulative block repertoire between learners from non-English speaking countries using Scratch in English to learners from the same countries using Scratch in their local language. To identify non-English speakers, we considered Scratch users who reported themselves as coming from five primarily non-English speaking countries: Portugal, Italy, Brazil, Germany, and Norway. We chose these five countries because they each have one very widely spoken language that is not English and because Scratch is almost fully translated into that language.
Even after controlling for a number of factors like social engagement on the Scratch website, user productivity, and time spent on projects, we found that learners from these countries who use Scratch in their local language have a higher rate of cumulative block repertoire growth than their counterparts using Scratch in English. This faster growth was despite having a lower initial block repertoire. The graph below visualizes our results for two “prototypical” learners who start with the same initial block repertoire: one learner who uses the English interface, and a second learner who uses their native language.
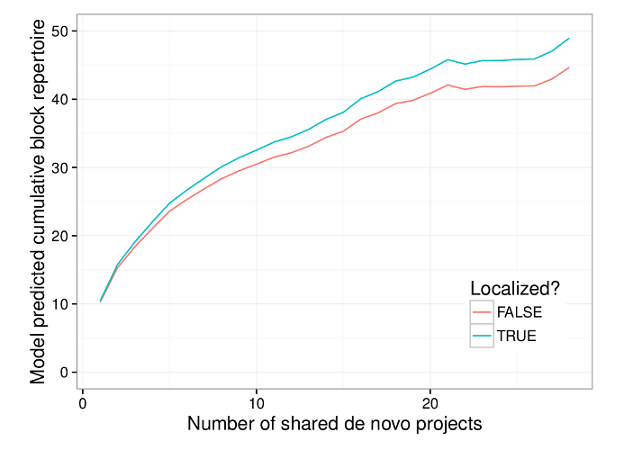
Our results are in line with what theories of education have to say about learning in one’s own language. Our findings also represent good news for designers of block-based programming languages who have spent considerable amounts of effort in making their programming languages translatable. It’s also good news for the volunteers who have spent many hours translating blocks and user interfaces.
Although we find support for our hypothesis, we should stress that our findings are both limited and incomplete. For example, because we focus on estimating the differences between Scratch learners, our comparisons are between kids who all managed to successfully use Scratch. Before Scratch was translated, kids with little working knowledge of English or the Latin script might not have been able to use Scratch at all. Because of translation, many of these children are now able to learn to code.
This blog-post and the work that it describes is a collaborative project with Benjamin Mako Hill. You can read our paper here. The paper was published in the ACM Learning @ Scale Conference. We also recently gave a talk about this work at the International Communication Association’s annual conference. We have received support and feedback from members of the Scratch team at MIT (especially Mitch Resnick and Natalie Rusk), as well as from Nathan TeBlunthuis at the University of Washington. Financial support came from the US National Science Foundation.
Discover more from Community Data Science Collective
Subscribe to get the latest posts sent to your email.