CSCW 2021 introduced Lab Speed Dating wherein labs were matched and given an hour to get to know each other. Sohyeon Hwang organized our first lab date. It was so much fun we decided to go on more in order to meet other groups. I wanted to share a bit about this and our process in case you are interested in trying it out or want to have a meetup with us.
After the initial CSCW Lab Date we made a very long list of other labs we want to meet and have (slowly) been inviting them to come by. We also included individual researchers, people who collaborate in smaller, informal groups, co-authors, and corporate research teams.
We use our “softblock” to schedule meetings, rather than finding a new time for each meeting. The CDSC maintains a softblock, which is a block of time for whatever comes up, one-off meetings we need to schedule, and co-working sessions. (Today I am using the softblock to write this blog post!)
We are pretty open to different structures for our lab dates. So far the ones with full labs have been divided into two parts: 1) everyone introduces themselves as briefly as we can manage and then 2) we break out into small groups for short periods of time to talk. We try to cycle through 2-3 of these breakouts, depending on how many people are in attendance. When meeting with individuals, our guests typically present a piece of work that we workshop or discussed their interests in a more general sense and we talk about them as a whole group. We are open to other models, but nothing has come up yet.
Blocks have focused around networking and getting to know other researchers on a professional level. Because we have been attending fewer in-person events, we have had fewer chances to meet new people. Even at events it can be hard to connect with the people you want to meet and it is very hard (for us) to have everyone from the CDSC in a space together with another group.
If you are interested in going on a lab date with us, you can message me on IRC or email me (details here). We have a lot of open spots for the rest of the quarter and one of them could be yours!
We recently held our second Community Dialogue around the theme of anonymity and privacy. Kaylea Champion presented on the role of anonymity in peer-contribution communities. Dr. Shruti Sannon joined us from the University of Michigan and talked about privacy in the gig economy.
What’s Anonymity Worth (Kaylea Champion)
Anonymity can protect and empower contributors in communities. Anonymity can make people feel safer or actually be safer. For example: Wikipedia editors who are working on controversial pages within contested geographies may be safer when they are able to contribute anonymously. Anonymous contribution is not without problems, as it can also empower trolls, harassers, and other bad actors. For more details, and actions you can take or policies to recommend within your communities, watch the video of Kaylea Champion’s presentation below.
Privacy and Surveillance in the Gig Economy (Dr. Shruti Sannon)
Gig workers can be asked or coerced to give up privacy in exchange for money through the design of the gig platforms they are using or by request of customers. Gig workers also use surveillance tools as a means of protecting themselves — some ride share drivers have cameras in their cars for this purpose. Dr. Sannon shared the broader implications of this situation, and what it can mean outside of the gig economy. To learn more, watch the video below.
Join us!
You can subscribe to our mailing list! We’ll be making announcements about future events there. It is a low volume mailing list.
Acknowledgements
Thanks to speakers Kaylea Champion and Shruti Sannon. The vision for this event borrows from the User and Open Innovation workshops organized by Eric von Hippel and colleagues, as well as others. This event and the research presented in it were supported by multiple awards from the National Science Foundation (DGE-1842165; IIS-2045055; IIS-1908850; IIS-1910202), Northwestern University, the University of Washington, and Purdue University.
Systems theory is a broad and multidisciplinary scientific approach that studies how things (molecules or cells or organs or people or companies) interact with each other. It argues that understanding how something works requires understanding its relationships and interdependencies.
For example, if we want to predict whether a new online community will grow, an individual perspective might focus on who the founder is, what software it is running on, how well it is designed, etc. A systems approach would argue that it is at least as important to understand things like how many similar communities there are, how active they are, and whether the platform is growing or shrinking.
In a paper just published in Media and Communication, I (Jeremy) argue that 1) it is particularly important to use a systems lens to study online communities, 2) that online communities provide ideal data for taking these approaches, and 3) that there is already really neat research in this area and there should be more of it.
The role of platforms
So, why is it so important to study online communities as interdependent “systems”? The first reason is that many online communities have a really important interdependence with the platforms that they run on. Platforms like Reddit or Facebook provide the servers and software for millions of communities, which are run mostly independently by the community managers and moderators.
However, this is an ambivalent relationship and often the goals and desires of at least some moderators are at odds with those of the platform, and things like community bans from the platform side or protests from the community side are not uncommon. The ways that platform decisions influence communities and how communities can work together to influence platforms are inherently systems questions.
Low barriers to entry and exit
A second feature of online communities is the relative ease with which people can join or leave them. Unlike offline groups, which at least require participants to get dressed, do their hair, and show up somewhere, online community participants can participate in an online community literally within seconds of knowing that it exists.
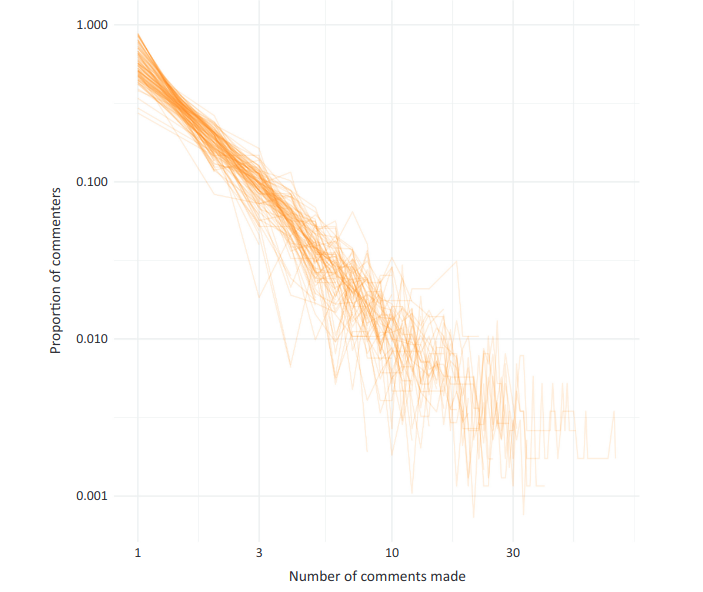
Similarly, people can leave incredibly easily, and most people do. This figure shows the number of comments made per person across 100 randomly selected subreddits (each line represents a subreddit; axes are both log-scaled). In every case, the vast majority of people only commented once while a few people made many comments.
Fuzzy boundaries
Finally, it’s often really difficult to draw clear boundaries around where one online community ends and another begins. For example, is all of Wikipedia one “community”? It might make sense to think of a language edition, a WikiProject, or even a single page as a community, and researchers have done all of the above. Even on platforms like Reddit, where there is a clearl delineation between communities, there are dependencies, with people and conversations moving across and between communities on similar topics.
In other words, online communities are semi-autonomous, interdependent, contingent organizations, deeply influenced by their environments. Online community scholars have often ignored this larger context, but systems theory gives us a rich set of tools for studying these interdependencies. One reason that it is so ideal is because online communities provide ideal data.
Data from Online Communities
Systems theory is not new – many of the main concepts were developed in the 1950s and 1960s or earlier. Organizational communication researchers saw how applicable these ideas were, and manyresearchersproposed treating organizations as systems.
However, it was really tough to get the data needed to do systems-based research. To study a group or organization as a system, you need to know about not only the internal workings of the group, but how it relates to other groups, how it is influenced by and influences its environment, etc. Gathering data about even one group was difficult and expensive; getting the data to study many groups and how they interact with each other over time was impossible.
The internet has entered the chat
Online communities provide the kind of data that these earlier researchers could have only dreamed of. Instead of data about one organization, platforms store data about thousands of organizations. And this is not just high-level data about activity levels or participation; on the contrary, we often have longitudinal, full-text conversations of millions of people as they interact within and move between communities.
Systems Approaches
In part, this article is a call for researchers to think more explicitly about online communities as systems, and to apply systems theory as a way of understanding how online communities work and how we can design research projects to understand them better. It is also an attempt to highlight strands of research that are already doing this. In the paper, I talk about four: Community Comparisons and Interactions, Individual Trajectories, Cross-level Mechanisms, and Simulating Emergent Behavior. Here, I’ll focus on just two.
Individual Trajectories
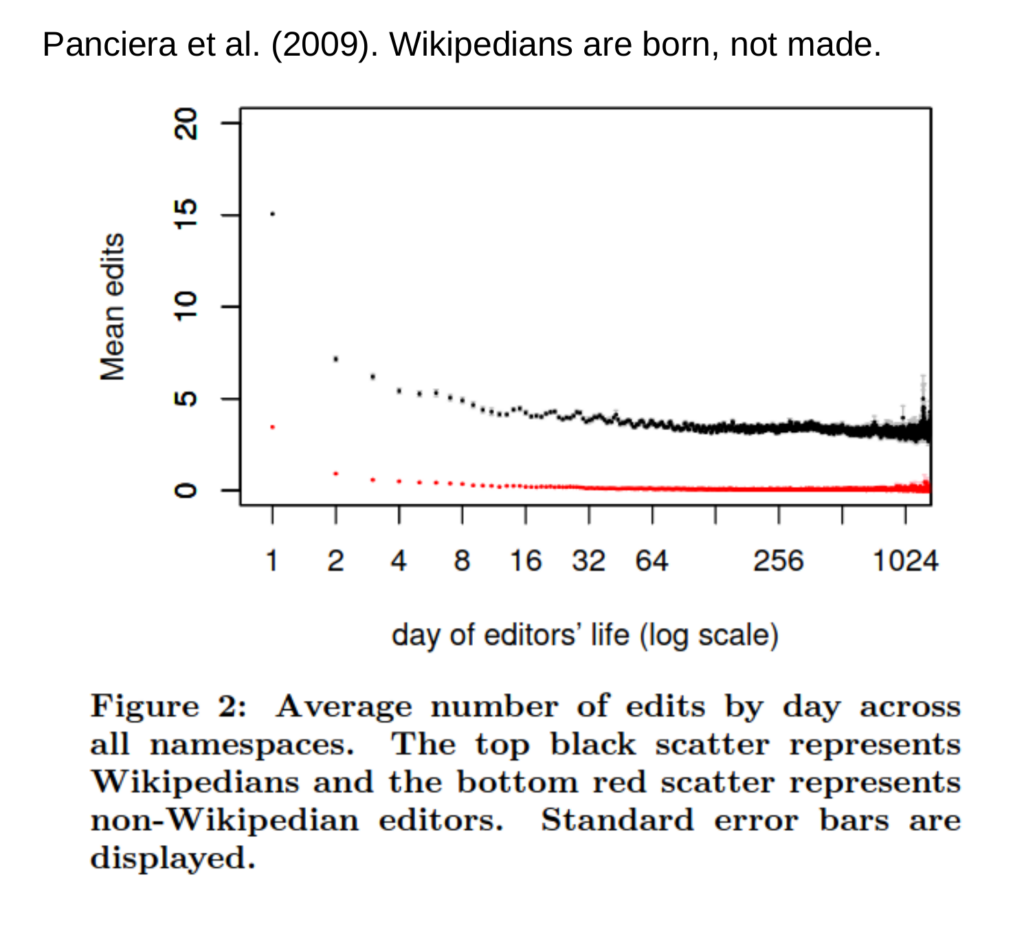
Figure from Panciera, K., Halfaker, A., & Terveen, L. (2009). Wikipedians are born, not made: A study of power editors on Wikipedia. Proceedings of the ACM 2009 International Conference on Supporting Group Work, 51–60. https://doi.org/10.1145/1531674.1531682
The first is what I call “Individual Trajectories”. In this approach, researchers can look at how individual people behave across a platform. One of the neat things about having longitudinal, unobtrusively collected data is that we can identify something interesting about users and go “back in time” to look for differences in earlier behavior. For example, in the plot above, Panciera et al. identified people who became active Wikipedia editors; they then went back and looked at how their behavior differed from typical editors from their early days on the site.
Researchers could and should do more work that looks at how people move between communities, and how communities influence the behavior of their members.
Simulating Emergent Behavior
The second approach is to use simulations to study emergent behaviors. Agent-based modeling software like NetLogo or Mesa allows researchers to create virtual worlds, where computational “agents” act according to theories of how the world works. Many communication theories make predictions about how individual‐level behavior produces higher‐level patterns, often through feedback loops (e.g., the Spiral of Silence theory). If agent-based models don’t produce those patterns, then we know that something about the theory—or its computational representation—is wrong.
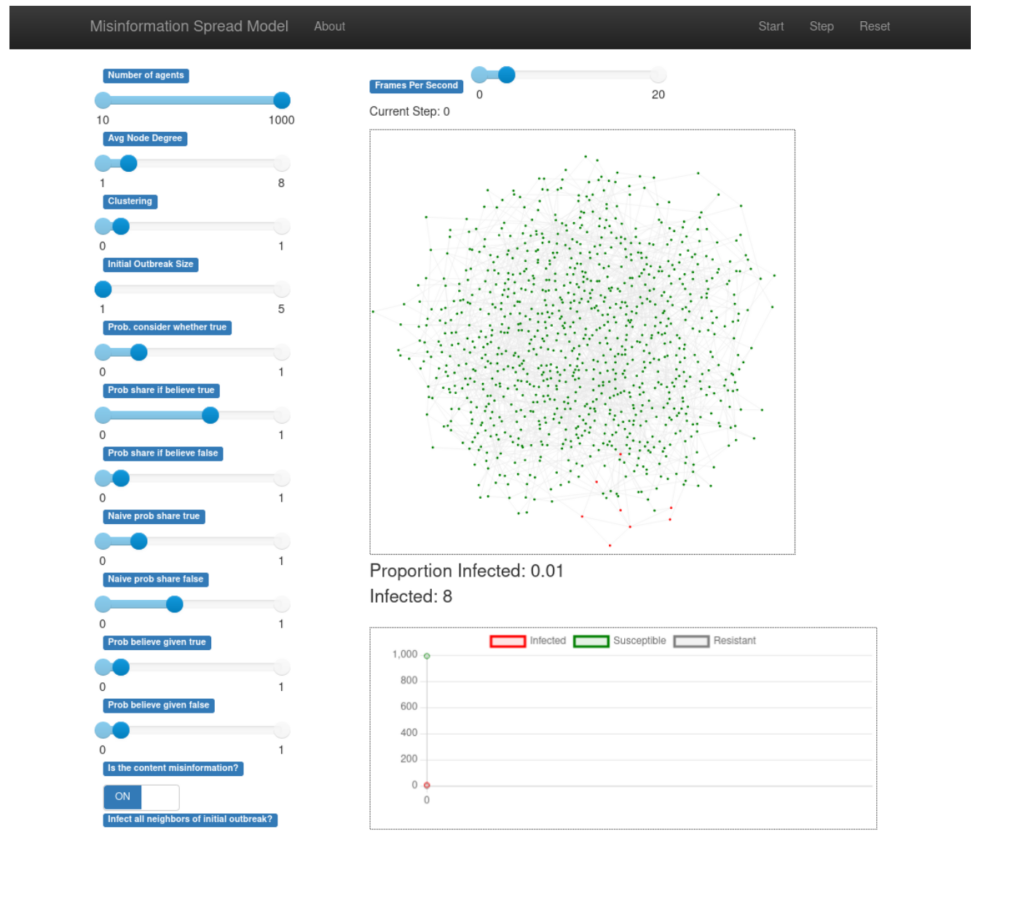
Model of misinformation spread, from Hu et al. (under review)
Agent-based modeling has received some attention from communication researchers lately, including a wonderful special issue was recently published in Communication Methods and Measures; the editorial article makes some great arguments for the promise and benefits of simulations for communication research.
New Opportunities
It is a really exciting time to be a computational social scientist, especially one that is interested in online organizations and organizing. We have only scratched the surface of what we can learn from the data that is pouring down around us, especially when it comes to systems theory questions. Tools, methods, and computational advances are constantly evolving and opening up new avenues of research.
Of course, taking advantage of these data sources and computational advances requires a different set of skills than Communication departments have traditionally focused on, and complicated, large-scale analyses require the use of supercomputers and extensive computational expertise.
However, there are many approaches like agent-based modeling or simple web scraping that can be taught to graduate students in one or two semesters, and open up lots of possibilities for doing this kind of research.
I’d love to talk more about these ideas—please reach out, or if you are coming to ICA, come talk to me!
The International Communication Association (ICA)’s 72nd annual conference is coming up in just a couple of weeks. This year, the conference takes place in Paris and a subset of our collective is flying out to present work in person. We are looking forward to meeting up, talking research, and eating croissants. À bientôt!
ICA takes place from Thursday, May 26th to Monday, May 30th, and we are presenting a total of ten (!!) times. All presentations given by members of the collective are scheduled between Friday and Sunday.
Friday
We start off with a presentation by Nathan TeBlunthuis on Friday at 11.00 AM, in Room 351 M (Palais des Congres). In a high-density paper session on Computational Approaches to Online Communities, Nate will present a paper entitled “Dynamics of Ecological Adaptation in Online Communities.”
Later that same day, at 3.30 PM in the Amphitheatre Havana (level 3; Palais des Congres), Carl Colglazier will discuss a paper that he collaborated on with Nick Diakopoulos: “Predictive Models in News Coverage of the COVID-19 Pandemic in the U.S.” This paper session is part of the ICA division Journalism Studies.
Saturday
On Saturday, Floor Fiers will present in the paper session “Impression Management Online: FabriCATing An Image.” Their project, which they wrote with Nathan Walter, discusses “Comments on Airbnb and the Potential for Racial Bias” at 2.00 PM in Regency 1 (Hyatt).
Shortly after, that same afternoon, you’ll find two of our poster presentations at 5.00 PM in the Exhibit Hall (Havana; Palais des Congres, level 3). In one of them, Jeremy Foote will discuss his take on “a systems approach to studying online communities.”
The other poster, presented at the same time and place, is by Kaylea Champion and Benjamin Mako Hill on “Resisting Taboo in the Collaborative Production of Knowledge: Evidence from Wikipedia.”
Sunday
Most of our presentations are on the fourth day of the conference. At 9.30 AM, we’ll be presenting in three locations at the same time! First, Floor will discuss their paper “Inequality and Discrimination in the Online Labor Market: a Scoping Review” in Room 311+312 (Palais des Congres). This presentation is part of the paper session “All Things Are Not Equal: CompliCATions From Digital Inequalities.”
Second, Carl will present work on behalf of himself, Aaron Shaw, and Benjamin Mako Hill during a high-density paper session in Room 242A (Palais des Congres). The title of their project is “Extended Abstract: Exhaustive Longitudinal Trace Data From Over 70,000 Wiki.”
Lastly, at the same time in Room 352B (Palais des Congres), Jeremy will present an interview study entitled “What Communication Supports Multifunctional Public Goods in Organizations? Using Agent-Based Modeling to Explore Differential Uses of Enterprise Social Media.” Jeremy’s co-authors on this paper are Jeffrey Treem and Bart van den Hooff.
On Sunday afternoon, at 3.30 PM in Room 311+312 (Palais des Congres), Tiwaladeoluwa Adekunle will talk about a qualitative project she collaborated on with Jeremy, Nate, and Laura Nelson: “Co-Creating Risk Online: Exploring Conceptualizations of COVID-19 Risk in Ideologically Distinct Online Communities.”
We will finish off our ICA 2022 presentations at 5.00 PM in Room 313+314 (Palais des Congres), where Kaylea will present on behalf of Isabella Brown, Lucy Bao, Jacinta Harshe, and Mako. The title of their paper is “Making Sense of Covid-19: Search Results and Information Providers”.
We look forward to sharing our research and connecting with you at ICA!
We’re going to be at CHI! The Community Data Science Collective will be presenting three papers. You can find us there in person in New Orleans, Louisiana, April 30 – May 5. If you’ve ever wanted a super cool CDSC sticker, this is your chance!
More than a billion people visit Wikipedia each month and millions have contributed as volunteers. Although Wikipedia exists in 300+ language editions, more than 90% of Wikipedia language editions have fewer than one hundred thousand articles. Many small editions are in languages spoken by small numbers of people, but the relationship between the size of a Wikipedia language edition and that language’s number of speakers—or even the number of viewers of the Wikipedia language editions—varies enormously. Why do some Wikipedias engage more potential contributors than others? We attempted to answer this question in a study of three Indian language Wikipedias that will be published and presented at the ACM Conference on Human Factors in Computing (CHI 2022).
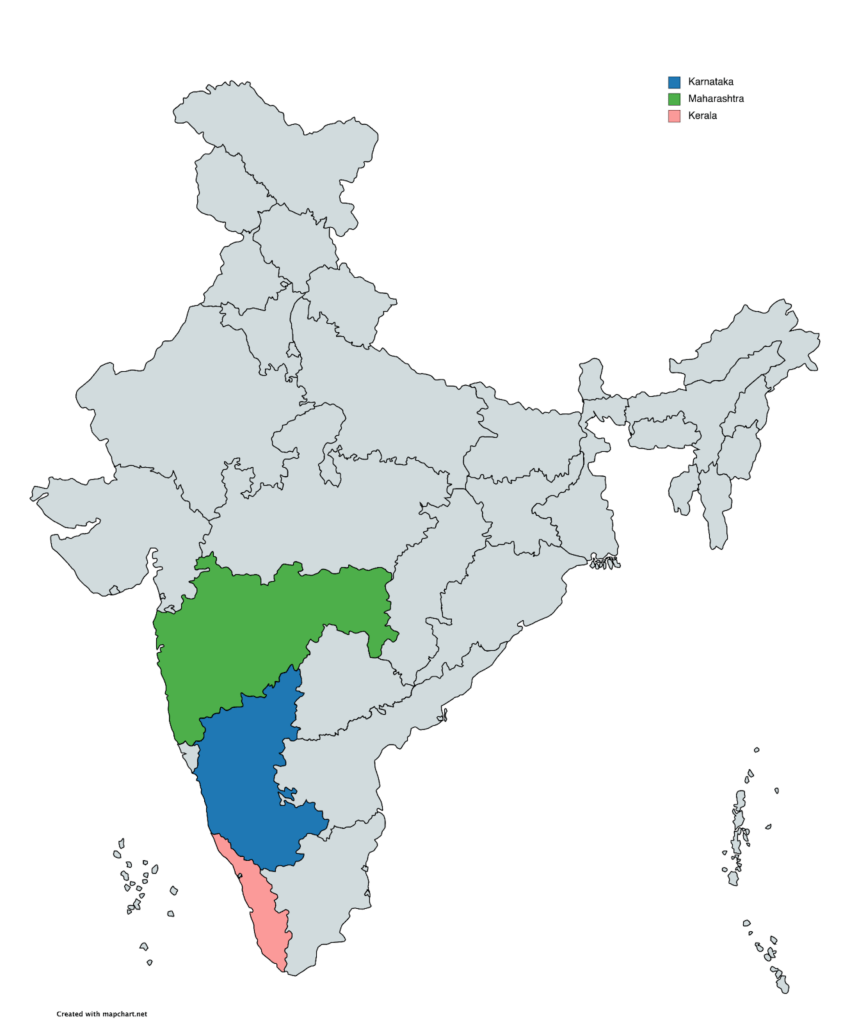
To conduct our study, we selected 3 Wikipedia language communities that correspond to the official languages of 3 neighboring states of India: Marathi (MR) from the state of Maharashtra, Kannada (KN) from the state of Karnataka, and Malayalam (ML) from the state of Kerala (see the map in right panel of the figure above). While the three projects share goals, technological infrastructure, and a similar set of challenges, Malayalam Wikipedia’s community engaged its language speakers in contributing to Wikipedia at a much higher rate than the others. The graph above (left panel) shows that although MR Wikipedia has twice as many viewers as ML Wikipedia, ML has more than double the number of articles on MR.
Our study focused on identifying differentiating factors between the three Wikipedias that could explain these differences. Through a grounded theory analysis of interviews with 18 community participants from the three projects, we identified two broad explanations of a “positive participation cycle” in Malayalam Wikipedia and a “negative participation cycle” in Marathi and Kannada Wikipedias.
As the first step of our study, we conducted semistructured interviews with active participants of all three projects to understand their personal experiences and motivation; their perceptions of dynamics, challenges, and goals within their primary language community; and their perceptions of other language Wikipedia.
We found that MR and KN contributors experience more day-to-day barriers to participation than ML, and that these barriers hinder contributors’ day-to-day activity and impede engagement. For example, both MR and KN members reported a large number of content disputes that they felt reduced their desire to contribute.
But why do some Wikipedias like MR or KN have more day-to-day barriers to contribution like content disputes and low social support than others? Our interviews pointed to a series of higher-level explanations. For example, our interviewees reported important differences in the norms and rules used within each community as well as higher levels of territoriality and concentrated power structures in MR and KN.
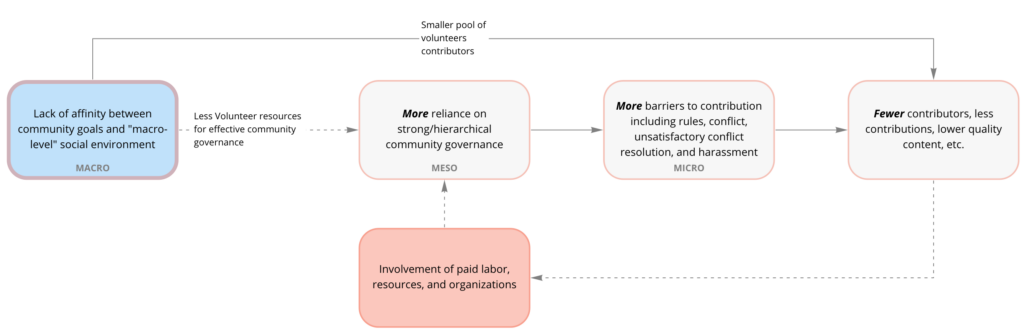
Once again, though: why do the MR and KN Wikipedias have these issues with territoriality and centralized authority structures? Here we identify a third, even higher-level set of differences in the social and cultural contexts of the three language-speaking communities. For example, MR and KN community members attributed low engagement to broad cultural attitudes toward volunteerism and differences in their language community’s engagement with free software and free culture.
The two flow charts above visualize the explanatory mapping of divergent feedback loops we describe. The top part of the figure illustrates how the relatively supportive macro-level social environment in Kerala led to a larger group of potential contributors to ML as well as a chain reaction of processes that led to a Wikipedia better able to engage potential contributors. The process is an example of a positive feedback cycle. The second, bottom part of the figure shows the parallel, negative feedback cycle that emerged in MR and KN Wikipedias. In these settings, features of the macro-level social environment led to a reliance on a relatively small group of people for community leadership and governance. This led, in turn, to barriers to entry that reduced contributions.
One final difference between the three Wikipedias was the role that paid labor from NGOs played. Because the MR and KN Wikipedias struggled to recruit and engage volunteers, NGOs and foundations deployed financial resources to support the development of content in Marathi and Kannada, but not in ML to the same degree. Our work suggested this tended to further concentrate power among a small group of paid editors in ways that aggravated the meso-level community struggles. This is shown in the red box in the second (bottom) row of the figure.
The results from our study provide a conceptual framework for understanding how the embeddedness of social computing systems within particular social and cultural contexts shape various aspects of the systems. We found that experience with participatory governance and free/open-source software in the Malayalam community supported high engagement of contributors. Counterintuitively, we found that financial resources intended to increase participation in the Marathi and Kannada communities hindered the growth of these communities. Our findings underscore the importance of social and cultural context in the trajectories of peer production communities. These contextual factors help explain patterns of knowledge inequity and engagement on the internet.
Please refer to the preprint of the paper for more details on the study and our design suggestions for localized peer production projects. We’re excited that this paper has been accepted to CHI 2022 and received the Best Paper Honorable Mention Award! It will be published in the Proceedings of the ACM on Human-Computer Interaction and presented at the conference in May. The full citation for this paper is:
Sejal Khatri, Aaron Shaw, Sayamindu Dasgupta, and Benjamin Mako Hill. 2022. The social embeddedness of peer production: A comparative qualitative analysis of three Indian language Wikipedia editions. In CHI Conference on Human Factors in Computing Systems (CHI ’22), April 29-May 5, 2022, New Orleans, LA, USA. ACM, New York, NY, USA, 18 pages. https://doi.org/10.1145/3491102.3501832
Attending the conference in New Orleans? Come attend our live presentation on May 3 at 3 pm at the CHI program venue, where you can discuss the paper with all the authors.
Online communities are frequently described as promising sites for computing education. Advocates of online communities as contexts for learning argue that they can help novices learn concrete programming skills through self-directed and interest-driven work. Of course, it is not always clear how well this plays out in practice—especially when it comes to learning challenging programming concepts. We sought to understand this process through a mixed-method case study of the Scratch online community that will be published and presented at the ACM Conference on Human Factors in Computing (CHI 2022) in several weeks.
Scratch is the largest online interest-driven programming community for novices. In Scratch, users can create programming projects using the visual-block based Scratch programming language. Scratch users can choose to share their projects—and many do—so that they can be seen, interacted with, and remixed by other Scratch community members. Our study focused on understanding how Scratch users learn to program with data structures (i.e., variables and lists)—a challenging programming concept for novices—by using community-produced learning resources such as discussion threads and curated project examples. Through a qualitative analysis on Scratch forum discussion threads, we identified a social feedback loop where participation in the community raises the visibility of some particular ways of using variables and lists in ways that shaped the nature and diversity of community-produced learning resources. In a follow-up quantitative analysis on a large collection of Scratch projects, we find statistical support for this social process.
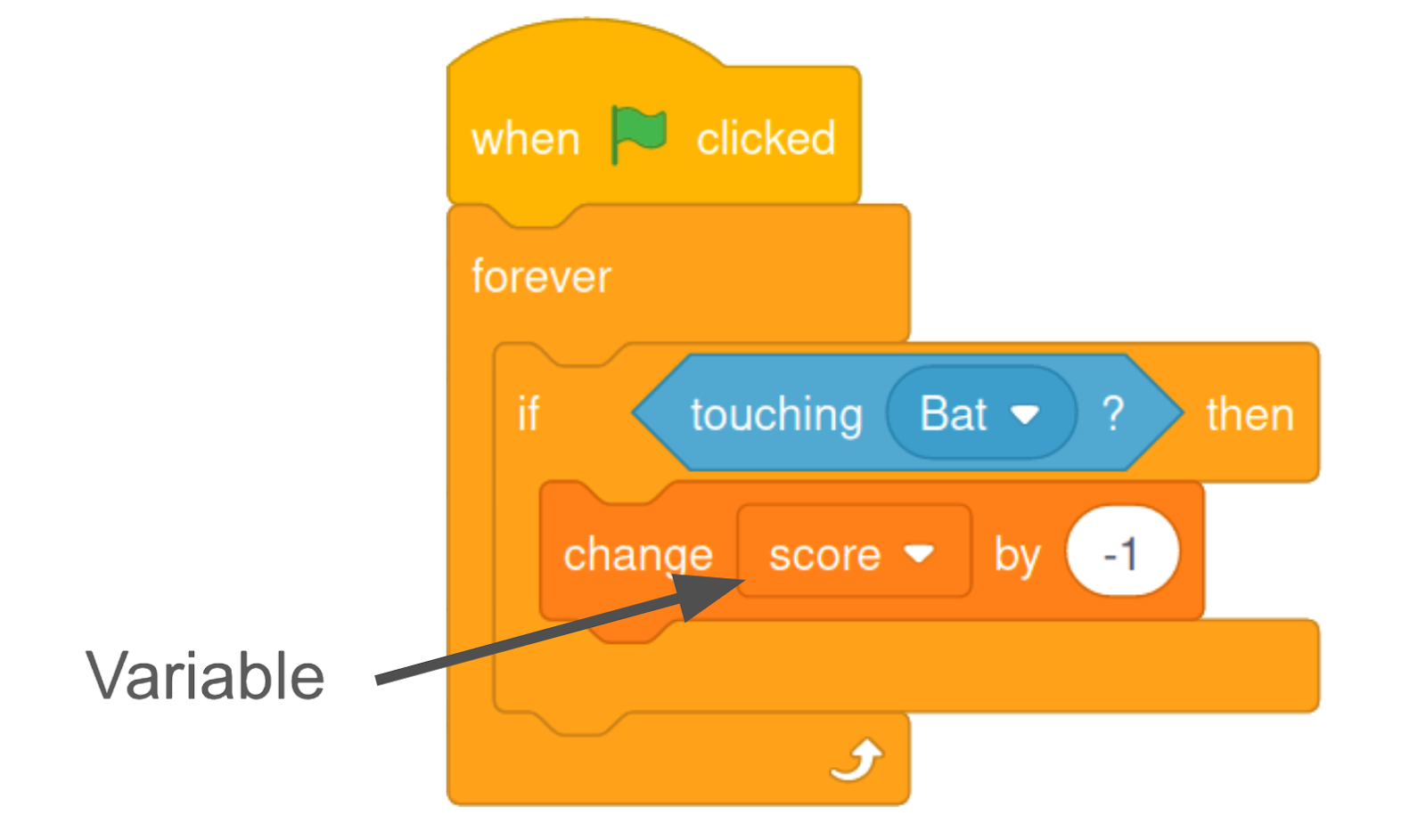
A Scratch project code of a score counter in a game.
As the first step of our study, we collected and qualitatively analyzed 400 discussion threads about variables and lists in the Scratch Q&A forums. Our key finding was that Scratch users use specific, concrete examples to teach each other about variables and lists. These examples are commonly framed in terms of elements in the projects that they are making, often specific to games.
For instance, we observed users teach each other how to make a score counter in a game using variables. In another example, we saw users sharing tips on creating an item inventory in a game using lists. As a result of this focus on specific game elements, user-generated examples and tutorials are often framed in the specifics of these game-making scenarios. For example, a lot of sample Scratch code on variables and lists were from games with popular elements like scores and inventories. While these community-produced learning resources offers valuable concrete examples, not everybody is interested in making games. We some some evidence that users who are not interested in making games involving scores and inventories were less likely to get effective support when they sought to learn about variables. We argue that repeated over time, this dynamic can lead to a social feedback loop where reliance on community-generated resources can place innovative forms of creative coding at a disadvantage compared to historically common forms.
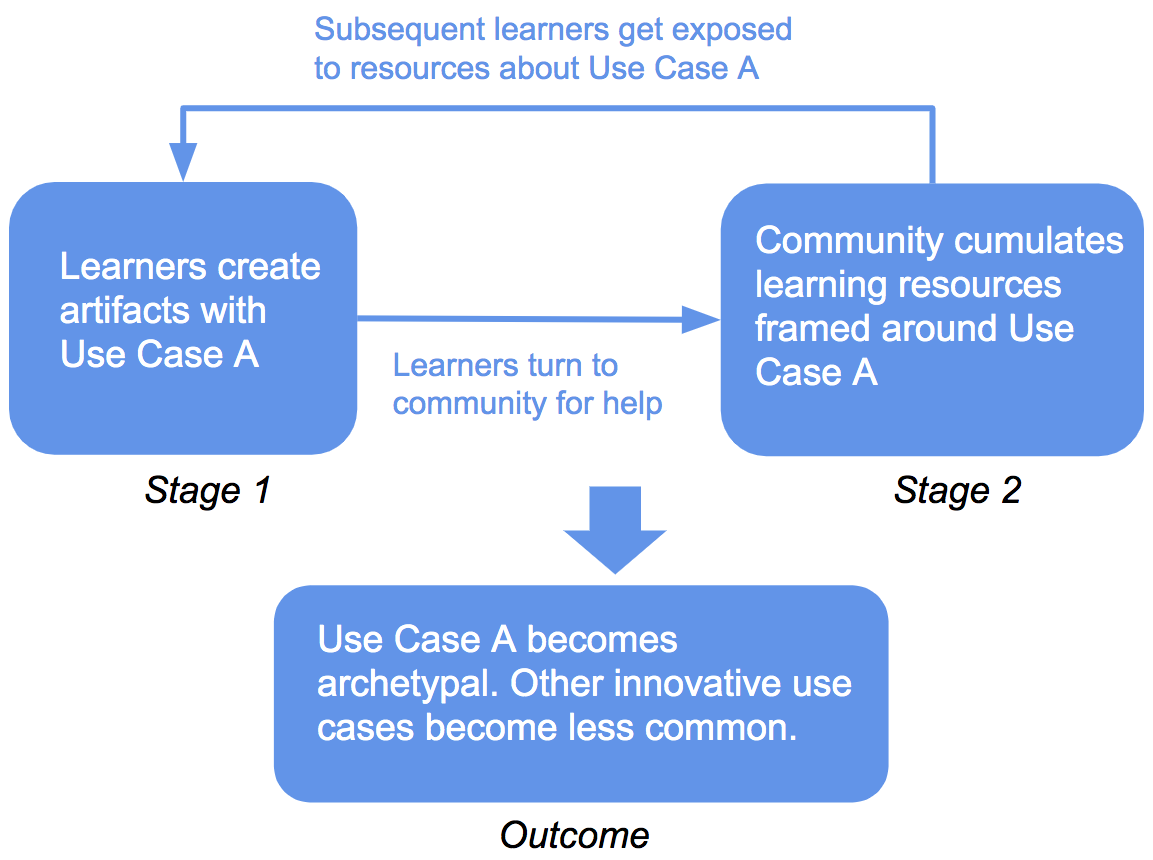
Our proposed hypothetical social feedback loop of how community-generated resources may constrain innovative computational participation.
The graph here is a visualization of the social feedback loop theory that we proposed. Stage 1 suggests that, in an online interest-driven learning community, some specific applications of a concept (“Use Case A”) will be more popular than others. This might be due to random chance or any number of reasons. When seeking community support, learners will tend to ask questions framed specifically around Use Case A and use community resources framed in terms of the same use case. Stage 2 shows the results of this process. As learners receive support, they produce new artifacts with Use Case A that can serve as learning resources for others. Then, learners in the future can use these learning resources, becoming even more likely to create the same specific application. The outcome of the feedback loop is that, as certain applications of a concept become more popular over time, the community’s learning resources are increasingly focused on the same applications.
We tested our social feedback loop theory using 5 years of Scratch data including 241,634 projects created by 75,911 users. We tested both the mechanism and the outcome of the loop from multiple angles in terms of three hypotheses that we believe will be true if our the feedback loop we describe is shaping behavior:
More projects involving variables and lists will be games over time.
The type of project elements that users make with variables and lists (we defined it as the names that they gave to variables and lists) will be more homogenous.
Users who have been exposed to popular variable and list names will be more likely to use those names in their own projects. We found at least some support for all of our hypotheses.
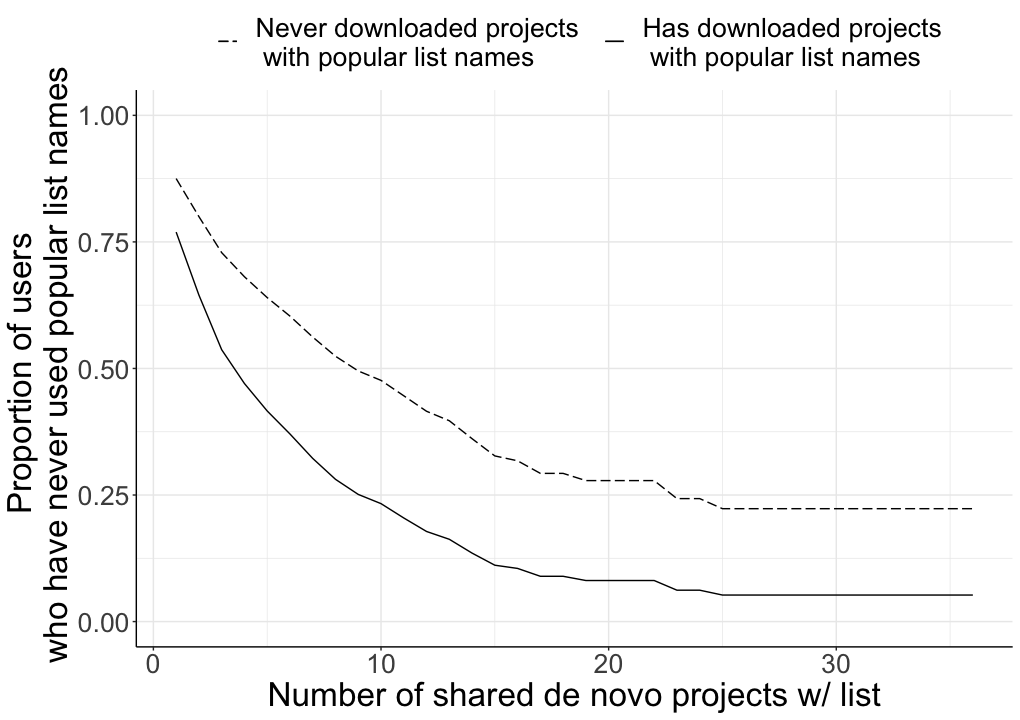
Our results provide broad (if imperfect) support for our social feedback loop theory. For example, the graph below illustrates one of our findings: users who have been exposed to popular list names (solid line) will be more likely to use (in other words, less likely to never use) popular names in their projects, compared to users who have never downloaded projects with popular list names (dashed line).
Plots from our cox proportional survival analysis on the difference between users who have previously downloaded projects with popular list names versus those who have never done so.
The results from our study describe an important trade-off that designers of online communities in computational learning need to be aware of. On the one hand, learners can learn advanced computational concepts by building their own explanation and understanding on specific use cases that are popular in the community. On the other, such learning can be superficial and not conceptual or generalizable: learners’ preference for peer-generated learning resources around specific interests can restrict the exploration of broader and more innovative uses, which can potentially limit sources of inspiration, pose barriers to broadening participation, and confine learners’ understanding of general concepts. We conclude our paper suggesting several design strategies that might be effective in countering this effect.
Please refer to the preprint of the paper for more details on the study and our design suggestions for future online interest-driven learning communities. We’re excited that this paper has been accepted to CHI 2022 and received the Best Paper Honorable Mention Award! It will be published in the Proceedings of the ACM on Human-Computer Interaction and presented at the conference in May. The full citation for this paper is:
Ruijia Cheng, Sayamindu Dasgupta, and Benjamin Mako Hill. 2022. How Interest-Driven Content Creation Shapes Opportunities for Informal Learning in Scratch: A Case Study on Novices’ Use of Data Structures. In CHI Conference on Human Factors in Computing Systems (CHI ’22), April 29-May 5, 2022, New Orleans, LA, USA. ACM, New York, NY, USA, 16 pages. https://doi.org/10.1145/3491102.3502124
This winter, the Community Data Science Collective launched a Community Dialogues series. These are meetings in which we invite community experts, organizers, and researchers to get together to share their knowledge of community practices and challenges, recent research, and how that research can be applied to support communities. We had our first meeting in February, with presentations from Jeremy Foot and Sohyeon Hwang on small communities and Nate TeBlunthius and Charlie Keine on overlapping communities.
Here are some quick summaries of the presentations. After the presentations, we formed small groups to discuss how what we learned related to our own experiences and knowledge of communities.
Finding Success in Small Communities
Small communities often stay small, medium stay medium, and big stay big. Meteoric growth is uncommon. User control and content curation improves user experience. Small communities help people define their expectations. Participation in small communities is often very salient and help participants build group identity, but not personal relationships. Growth doesn’t mean success, and we need to move beyond that and solely using quantitative metrics to judge our success. Being small can be a feature, not a bug!
We built a list of discussion questions collaboratively. It included:
Are you actively trying to attract new members to your community? Why or why not?
How do you approach scale/size in your community/communities?
Do you experience pressure to grow? From where? Towards what end?
What kinds of connections do people seek in the community/communities you are a part of?
Can you imagine designs/interventions to draw benefits from small communities or sub-communities within larger projects/communities?
How to understand/set community members’ expectations regarding community size?
“Small communities promote group identity but not interpersonal relationships.” This seems counterintuitive.
How do you managing challenges around growth incentives/pressures?
Why People Join Multiple Communities
People join topical clusters of communities, which have more mutualistic relationships than competitive ones. There is a trilemma (like a dilemma) between large audience, specific content, and homophily (likemindness). No community can do everything, and it may be better for participants and communities to have multiple, overlapping spaces. This can be more engaging, generative, fulfilling, and productive. People develop portfolios of communities, which can involve many small communities..
Questions we had for each other:
Do members of your community also participate in similar communities?
What other communities are your members most often involved in?
Are they “competing” with you? Or “mutualistic” in some way?
In what other ways do they relate to your community?
There is a “trilemma” between the largest possible audience, specific content, and homophilous (likeminded/similar folks) community. Where does your community sit inside this trilemma?
You can subscribe to our mailing list! We’ll be making announcements about future events there. It will be a low volume mailing list.
Acknowledgements
Thanks to speakers Charlie Kiene, Jeremy Foote, Nate TeBlunthius, and Sohyeon Hwang! Kaylea Champion was heavily involved in planning and decision making. The vision for the event borrows from the User and Open Innovation workshops organized by Eric von Hippel and colleagues, as well as others. This event and the research presented in it were supported by multiple awards from the National Science Foundation (DGE-1842165; IIS-2045055; IIS-1908850; IIS-1910202), Northwestern University, the University of Washington, and Purdue University.
Session summaries and questions above were created collaboratively by event attendees.
This year was packed with things we’re excited about and want to celebrate and share. Great things happened to Community Data Science Collective members within our schools and the wider research community.
Charlie Kiene and Regina Cheng completed their comprehensive exams and are now PhD candidates!
Nate TeBlunthuis defended his dissertation and started a post-doctoral fellowship at Northwestern. Jim Maddock defended his dissertation on December 16th.
Regina was a teaching assistant for senior undergraduate students on their capstone projects. Regina’s mentees won Best Design and Best Engineering awards.
Salt was interviewed on the FOSS and Crafts podcast. His conference presentations included Linux App Summit, SeaGL and DebConf. Kaylea Champion spoke at SeaGL and DebConf. Kaylea’s DebConf present was on her research on detecting at-risk projects in Debian.
Champion, Kaylea. 2021. “Underproduction: An approach for measuring risk in open source software.” 28th IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). pp. 388-399, doi: 10.1109/SANER50967.2021.00043.
Fiers, Floor , Aaron Shaw , and Eszter Hargittai. 2021. “Generous Attitudes and Online Participation.” Journal of Quantitative Description: Digital Media, 1. https://doi.org/10.51685/jqd.2021.008
Hill, Benjamin Mako , and Aaron Shaw , 2021. “The hidden costs of requiring accounts: Quasi-experimental evidence from peer production.” Communication Research 48(6): 771-795. https://doi.org/10.1177%2F0093650220910345.
Hwang, Sohyeon and Jeremy Foote . 2021. “Why do people participate in small online communities?”. Proceedings of the ACM on Human-Computer Interaction, 5(CSCW2), 462:1-462:25. https://doi.org/10.1145/3479606
Shaw, Aaron and Eszter Hargittai. 2021. “Do the Online Activities of Amazon Mechanical Turk Workers Mirror Those of the General Population? A Comparison of Two Survey Samples.” International Journal of Communication 15: 4383–4398. https://ijoc.org/index.php/ijoc/article/view/16942
TeBlunthuis, Nathan , Benjamin Mako Hill , and Aaron Halfaker. 2021. “Effects of Algorithmic Flagging on Fairness: Quasi-experimental Evidence from Wikipedia.” Proc. ACM Hum.-Comput. Interact. 5, CSCW1, Article 56 (April 2021), 27 pages. https://doi.org/10.1145/3449130
TeBlunthuis, Nathan. 2021 “Measuring Wikipedia Article Quality in One Dimension.” In Proceedings of the 17th International Symposium on Open Collaboration (OpenSym ’21). Online: ACM Press. https://doi.org/10.1145/3479986.3479991.
The OG Mechanical Turk (public domain via Wikimedia Commons). It probably was not useful for unbiased survey research sampling either.
When it comes to research about participation in social media, sampling and bias are topics that often get ignored or politely buried in the “limitations” sections of papers. This is even true in survey research using samples recruited through idiosyncratic sites like Amazon’s Mechanical Turk. Together with Eszter Hargittai, I (Aaron) have a new paper (pdf) out in the International Journal of Communication (IJOC) that illustrates why ignoring sampling and bias in online survey research about online participation can be a particularly bad idea.
Surveys remain a workhorse method of social science, policy, and market research. But high-quality survey research that produces generalizable insights into big (e.g., national) populations is expensive, time-consuming, and difficult. Online surveys conducted through sites like Amazon Mechanical Turk (AMT), Qualtrics, and others offer a popular alternative for researchers looking to reduce the costs and increase the speed of their work. Some people even go so far as to claim that AMT has “ushered in a golden age in survey research” (and focus their critical energies on other important issues with AMT, like research ethics!).
Despite the hype, the quality of the online samples recruited through AMT and other sites often remains poorly or incompletely documented. Sampling bias online is especially important for research that studies online behaviors, such as social media use. Even with complex survey weighting schemes and sophisticated techniques like multilevel regression with post-stratification (MRP), surveys gathered online may incorporate subtle sources of bias because the people who complete the surveys online are also more likely to engage in other kinds of activities online.
Surprisingly little research has investigated these concerns directly. Eszter and I do so by using a survey instrument administered concurrently on AMT and a national sample of U.S. adults recruited through NORC at the University of Chicago (note that we published another paper in Socius using parts of the same dataset last year). The results suggest that AMT survey respondents are significantly more likely to use numerous social media, from Twitter to Pinterest and Reddit, as well as have significantly more experiences contributing their own online content, from posting videos to participating in various online forums and signing online petitions.
Such findings may not be shocking, but prevalent research practices often overlook the implications: you cannot rely on a sample recruited from an online platform like AMT to map directly to a general population when it comes to online behaviors. Whether AMT has created a survey research “golden age” or not, analysis conducted on a biased sample produces results that are less valuable than they seem.








{kind=link}