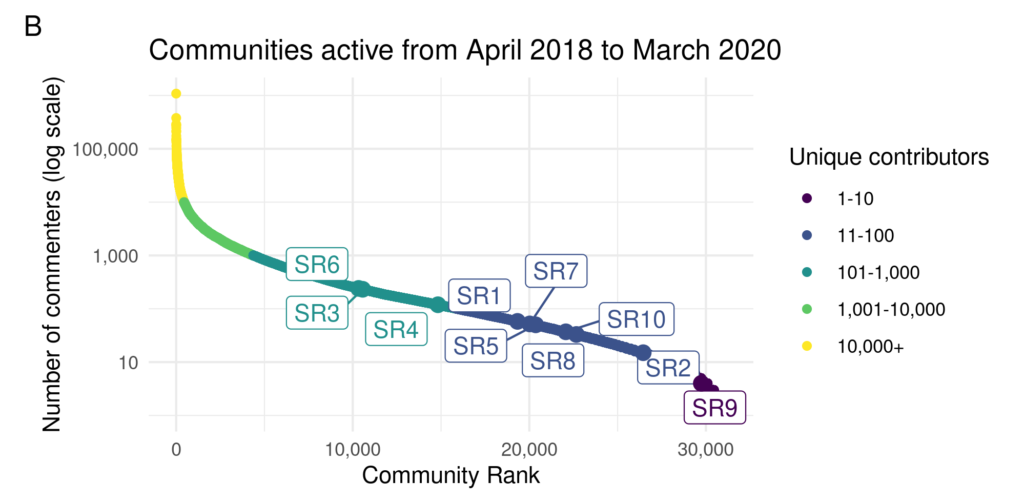
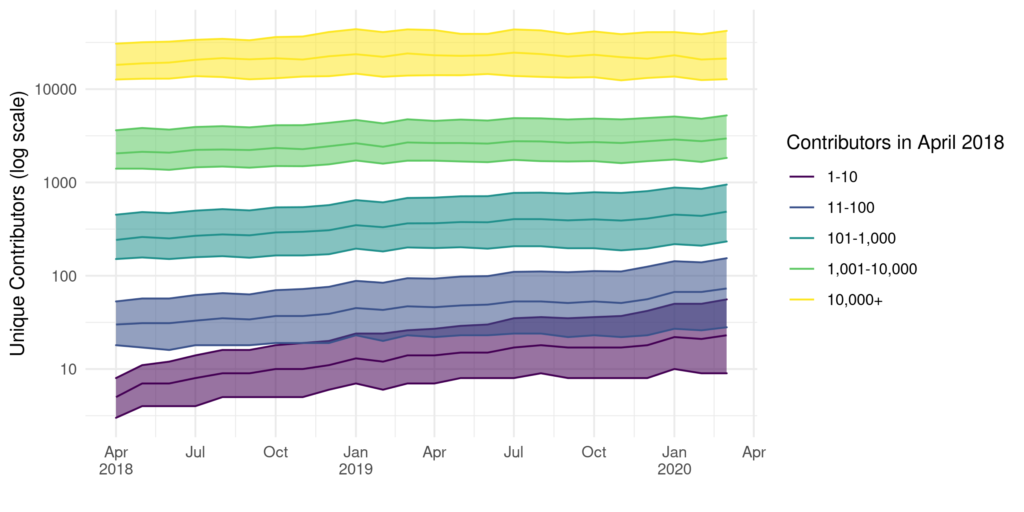
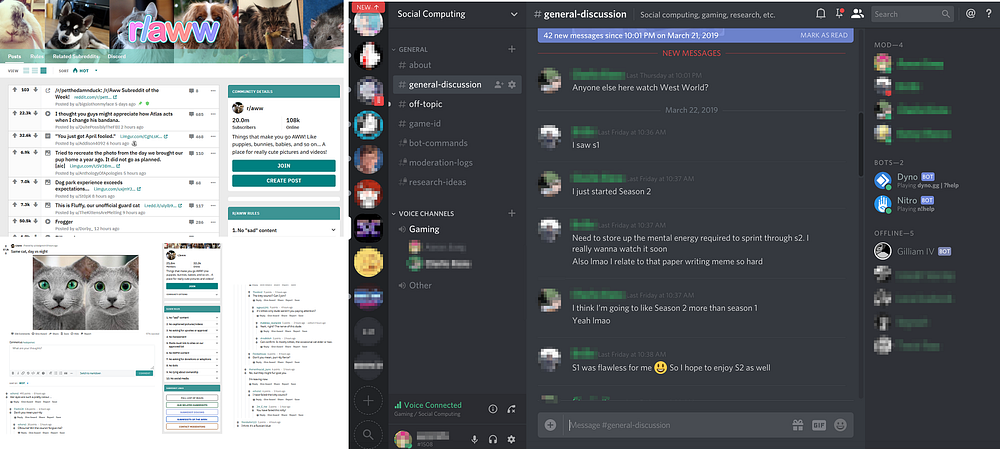
When it comes to online communities, we often assume that bigger is better. Large communities can create robust interactions, have access to broad and extensive body of experiences, and provide many opportunities for connections. As a result, small communities are often thought as failed attempts to build big ones. In reality, most online communities are very small and most small communities remain small throughout their lives. If growth and a large number of members are so advantageous, why do small communities not only exist but persist in their smallness?
In a recent research study, we investigated why individuals participate in these persistently small online communities by interviewing twenty participants of small subreddits on Reddit. We asked people about their motivations and explicitly tried to get them to compare their experiences in small subreddits with their experience in larger subreddits. Below we present three of the main things that we discovered through analyzing our conversations.
Informational niches
First, we found that participants saw their small communities as unique spaces for information and interaction. Frequently, small communities are narrower versions or direct offshoots of larger communities. For example, the r/python community is about the programming language Python while the r/learnpython community is a smaller community explicitly for newcomers to the language.
By being in a smaller, more specific community, our participants described being able to better anticipate the content, audience, and norms: a specific type of content, people who cared about the narrow topic just like them, and expectations of how to behave online. For example, one participant said:
[…] I can probably make a safe assumption that people there more often than not know what they’re talking about. I’ll definitely be much more specific and not try to water questions down with like, my broader scheme of things—I can get as technical as possible, right? If I were to ask like the same question over at [the larger parent community], I might want to give a little bit background on what I’m trying to do, why I’m trying to do it, you know, other things that I’m using, but [in small community], I can just be like, hey, look, I’m trying to use this algorithm for this one thing. Why should I? Or should I not do it for this?
Curating online experiences
More broadly, participants explained their participation in these small communities as part of an ongoing strategy of curating their online experience. Participants described a complex ecosystem of interrelated communities that the small communities sat within, and how the small communities gave them the ability to select very specific topics, decide who to interact with, and manage content consumption.
In this sense, small communities give individuals a semblance of control on the internet. Given the scale of the internet—and a widespread sense of malaise with online hate, toxicity, and harassment—it is possible that controlling the online experience is more important to users than ever. Because of their small size, these small communities were largely free of the vandals and trolls that plague large online communities, and several participants described their online communities as special spaces to get away from the negativity on the rest of the internet.
Relationships
Finally, one surprise from our research was what we didn’t find. Previous research led us to predict that people would participate in small communities because they would make it easier to develop friendships with other people. Our participants described being interested in the personal experiences of other group members, but not in building individual relationships with them.
Conclusions
Our research shows that small online communities play an important and underappreciated role. At the individual level, online communities help people to have control over their experiences, curating a set of content and users that is predictable and navigable. At the platform level, small communities seem to have a symbiotic relationship with large communities. By breaking up broader topical niches, small communities likely help to keep a larger set of users engaged.
We hope that this paper will encourage others to take seriously the role of small online communities. They are qualitatively different from large communities, and more empirical and theoretical research is needed in order to understand how communities of different sizes operate and interact in community ecosystems.
A preprint of the paper is available here. We’re excited that this paper has been accepted to CSCW2021 and will be published in the Proceedings of the ACM on Human-Computer Interaction and presented at the conference in November. If you have any questions about this research, please feel free to reach out to one of the authors: Sohyeon Hwang or Jeremy Foote.





{kind=link}