Systems theory is a broad and multidisciplinary scientific approach that studies how things (molecules or cells or organs or people or companies) interact with each other. It argues that understanding how something works requires understanding its relationships and interdependencies.
For example, if we want to predict whether a new online community will grow, an individual perspective might focus on who the founder is, what software it is running on, how well it is designed, etc. A systems approach would argue that it is at least as important to understand things like how many similar communities there are, how active they are, and whether the platform is growing or shrinking.
In a paper just published in Media and Communication, I (Jeremy) argue that 1) it is particularly important to use a systems lens to study online communities, 2) that online communities provide ideal data for taking these approaches, and 3) that there is already really neat research in this area and there should be more of it.
The role of platforms
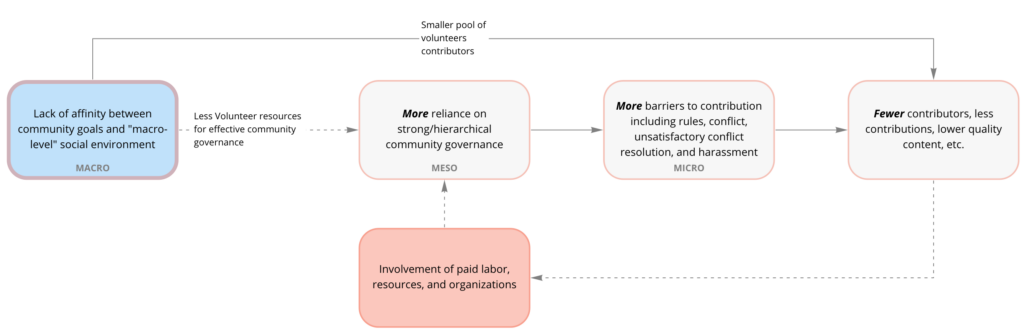
So, why is it so important to study online communities as interdependent “systems”? The first reason is that many online communities have a really important interdependence with the platforms that they run on. Platforms like Reddit or Facebook provide the servers and software for millions of communities, which are run mostly independently by the community managers and moderators.
However, this is an ambivalent relationship and often the goals and desires of at least some moderators are at odds with those of the platform, and things like community bans from the platform side or protests from the community side are not uncommon. The ways that platform decisions influence communities and how communities can work together to influence platforms are inherently systems questions.
Low barriers to entry and exit
A second feature of online communities is the relative ease with which people can join or leave them. Unlike offline groups, which at least require participants to get dressed, do their hair, and show up somewhere, online community participants can participate in an online community literally within seconds of knowing that it exists.
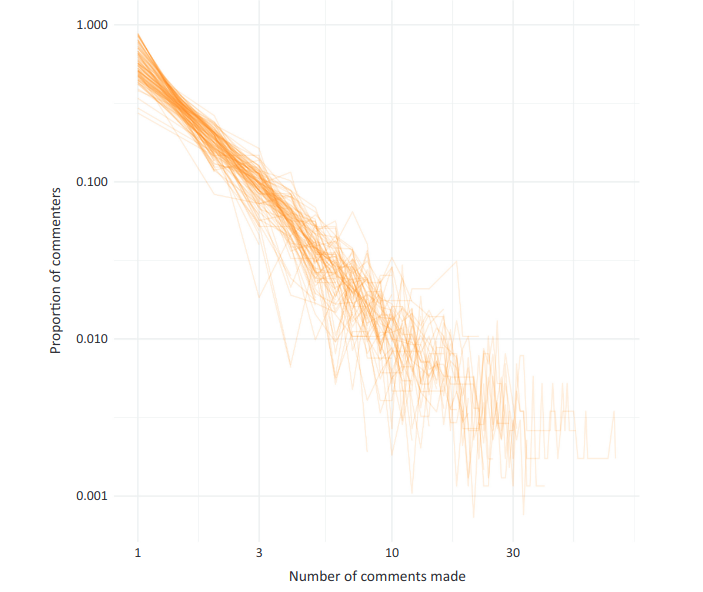
Similarly, people can leave incredibly easily, and most people do. This figure shows the number of comments made per person across 100 randomly selected subreddits (each line represents a subreddit; axes are both log-scaled). In every case, the vast majority of people only commented once while a few people made many comments.
Fuzzy boundaries
Finally, it’s often really difficult to draw clear boundaries around where one online community ends and another begins. For example, is all of Wikipedia one “community”? It might make sense to think of a language edition, a WikiProject, or even a single page as a community, and researchers have done all of the above. Even on platforms like Reddit, where there is a clearl delineation between communities, there are dependencies, with people and conversations moving across and between communities on similar topics.
In other words, online communities are semi-autonomous, interdependent, contingent organizations, deeply influenced by their environments. Online community scholars have often ignored this larger context, but systems theory gives us a rich set of tools for studying these interdependencies. One reason that it is so ideal is because online communities provide ideal data.
Data from Online Communities
Systems theory is not new – many of the main concepts were developed in the 1950s and 1960s or earlier. Organizational communication researchers saw how applicable these ideas were, and many researchers proposed treating organizations as systems.
However, it was really tough to get the data needed to do systems-based research. To study a group or organization as a system, you need to know about not only the internal workings of the group, but how it relates to other groups, how it is influenced by and influences its environment, etc. Gathering data about even one group was difficult and expensive; getting the data to study many groups and how they interact with each other over time was impossible.
The internet has entered the chat
Online communities provide the kind of data that these earlier researchers could have only dreamed of. Instead of data about one organization, platforms store data about thousands of organizations. And this is not just high-level data about activity levels or participation; on the contrary, we often have longitudinal, full-text conversations of millions of people as they interact within and move between communities.
Systems Approaches
In part, this article is a call for researchers to think more explicitly about online communities as systems, and to apply systems theory as a way of understanding how online communities work and how we can design research projects to understand them better. It is also an attempt to highlight strands of research that are already doing this. In the paper, I talk about four: Community Comparisons and Interactions, Individual Trajectories, Cross-level Mechanisms, and Simulating Emergent Behavior. Here, I’ll focus on just two.
Individual Trajectories
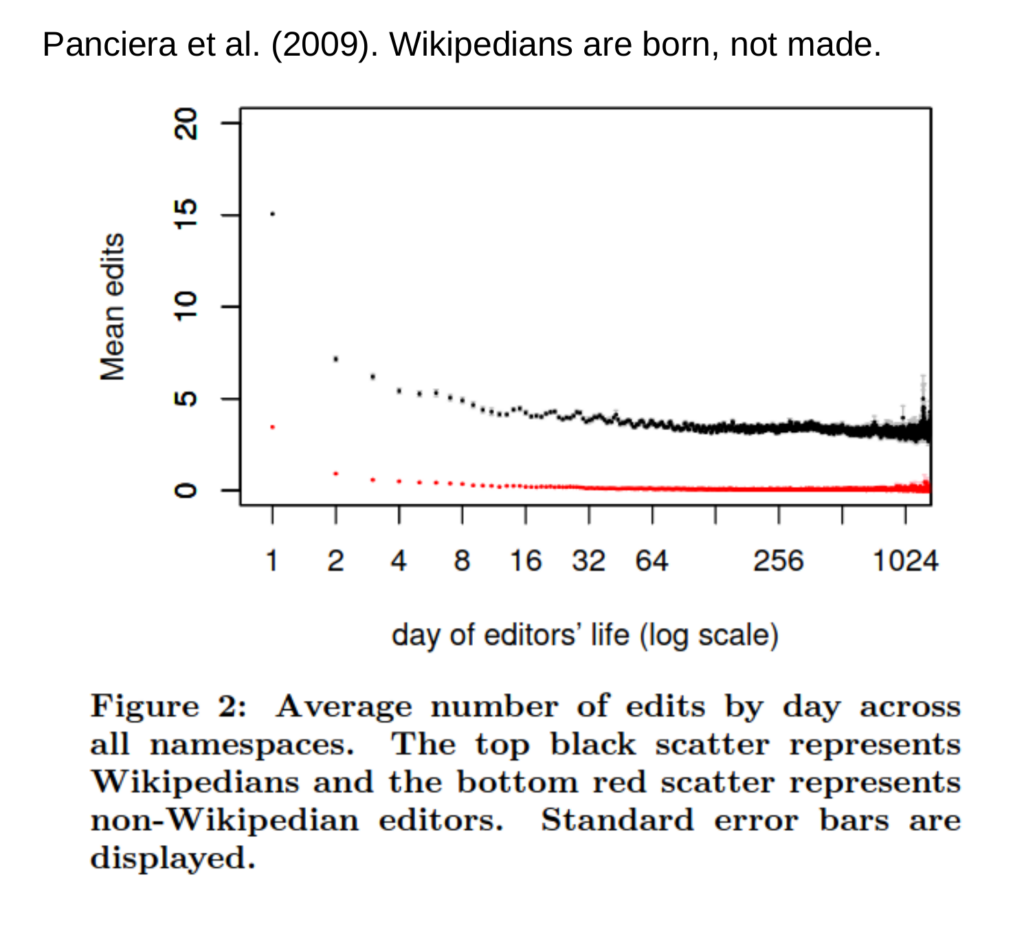
The first is what I call “Individual Trajectories”. In this approach, researchers can look at how individual people behave across a platform. One of the neat things about having longitudinal, unobtrusively collected data is that we can identify something interesting about users and go “back in time” to look for differences in earlier behavior. For example, in the plot above, Panciera et al. identified people who became active Wikipedia editors; they then went back and looked at how their behavior differed from typical editors from their early days on the site.
Researchers could and should do more work that looks at how people move between communities, and how communities influence the behavior of their members.
Simulating Emergent Behavior
The second approach is to use simulations to study emergent behaviors. Agent-based modeling software like NetLogo or Mesa allows researchers to create virtual worlds, where computational “agents” act according to theories of how the world works. Many communication theories make predictions about how individual‐level behavior produces higher‐level patterns, often through feedback loops (e.g., the Spiral of Silence theory). If agent-based models don’t produce those patterns, then we know that something about the theory—or its computational representation—is wrong.
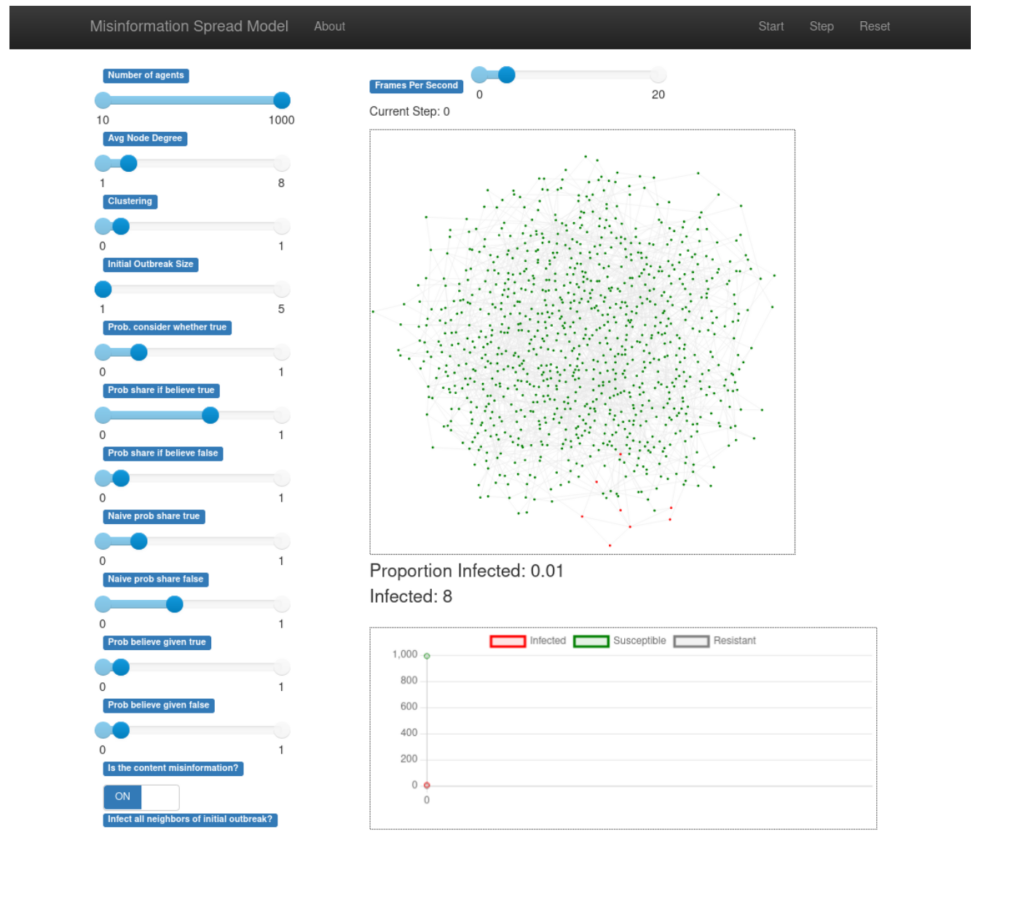
Agent-based modeling has received some attention from communication researchers lately, including a wonderful special issue was recently published in Communication Methods and Measures; the editorial article makes some great arguments for the promise and benefits of simulations for communication research.
New Opportunities
It is a really exciting time to be a computational social scientist, especially one that is interested in online organizations and organizing. We have only scratched the surface of what we can learn from the data that is pouring down around us, especially when it comes to systems theory questions. Tools, methods, and computational advances are constantly evolving and opening up new avenues of research.
Of course, taking advantage of these data sources and computational advances requires a different set of skills than Communication departments have traditionally focused on, and complicated, large-scale analyses require the use of supercomputers and extensive computational expertise.
However, there are many approaches like agent-based modeling or simple web scraping that can be taught to graduate students in one or two semesters, and open up lots of possibilities for doing this kind of research.
I’d love to talk more about these ideas—please reach out, or if you are coming to ICA, come talk to me!







{kind=link}