Throughout their lifecycles, the online communities that steward public information goods can face a range of threats to their sustainability. Over the course of its existence, Wikipedia, one of the most visible online knowledge commons, has battled the following challenges:
Strategic degradation and pollution, through the introduction of misinformation and vandalism affecting its article base;
Governance capture of some language projects by small groups of ideologically motivated editors;
Commercial appropriation and disintermediation of its knowledge base by generative AI companies; and
Escalating legitimacy attacks by partisan actors seeking to undermine the online encyclopedia’s perceived credibility as an information resource.
At our 11th Science of Community Dialogue on April 4th, which featured a conversation with Zarine Kharazian (University of Washington) and Professor Paul Gowder (Northwestern University), we discussed the role of online community governance in responding to these threats. Following up on this discussion, we are excited to share a research brief that both outlines some of the evolving threats that public information goods face as they mature and offers strategies that community leaders can adopt to address them. We hope that this synthesis inspires reflection and discussion on the nature of the public information goods various online communities maintain and the role of community governance institutions in defending the goods at stake and building public trust and legitimacy.
Community decay and abandonment are persistent risks to free/libre and open source software (FLOSS) projects. As such, large institutions such as GitHub or Mozilla offer advice to FLOSS projects on how to organize their work for sustainability and community-building. Guides recommend the production of README files and CONTRIBUTING guides as useful tools in recruiting new project contributors and driving activity. Yet though the development of these documents is widely-suggested, there is little empirical study of how projects use these files and what happens when documents are introduced to projects.
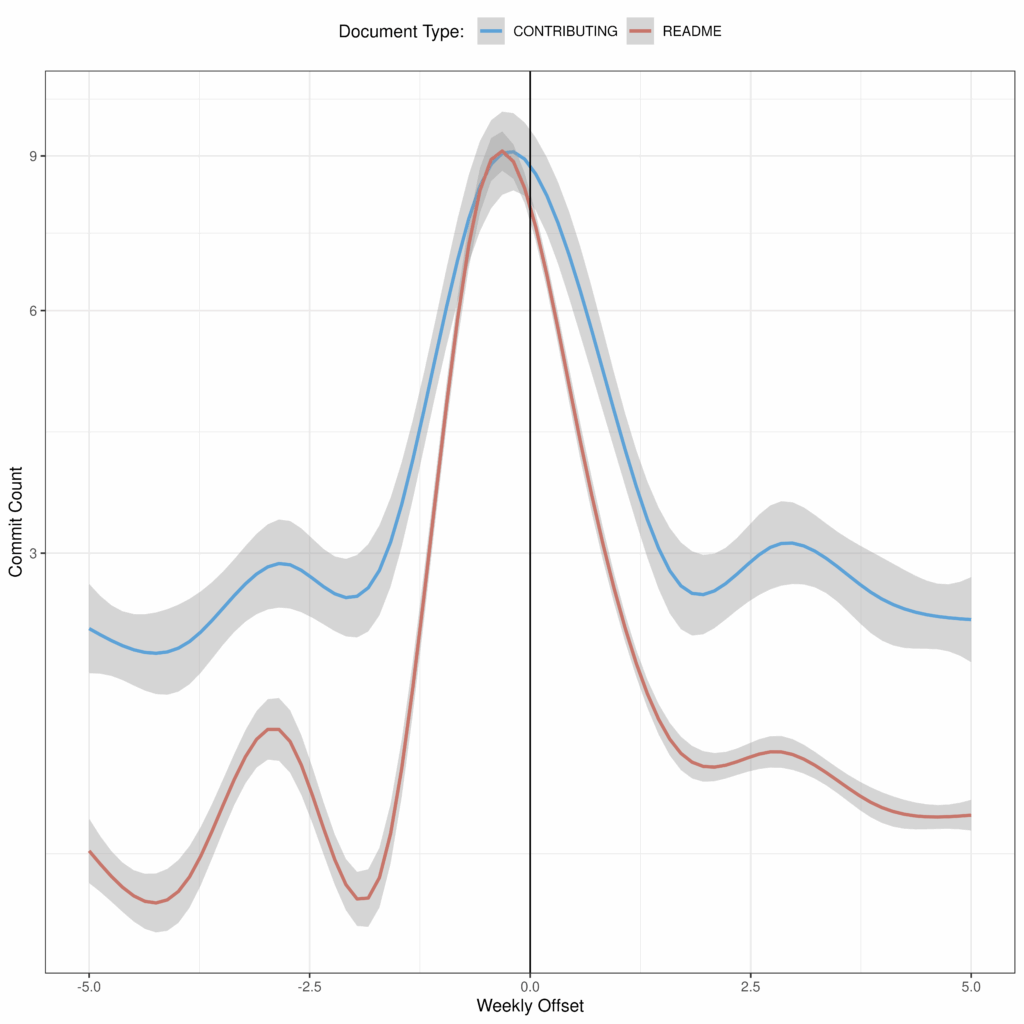
Plot of average (log-transformed) weekly contribution counts over time around the point of document introduction (weeks offset from document publication date) for README (red) and CONTRIBUTING (blue) files. The Y-axis has been scaled to real count values.
In one of the first empirical studies of the initial publication of documentation files, our findings suggest a disconnect between institutional recommendations and FLOSS projects’ actual use the documents. Instead of being proactively developed and community-oriented, first-version files are published following an increase of activity and focus on the functional details of using or contributing to the library. Often, documents are published with hardly any content at all, with projects publishing empty or minimal files. We found no support for any causal claims around the nature of a document’s depth or focus and subsequent project activity.
Our results suggest that projects may use these documents to perform a norm. The publication of empty documentation files implies that an empty file in their home directory was more important to projects than any benefits of document contents. Our results also suggest that projects may use these documents to ‘get their house in order’ after an influx of activity.
The guides and recommendations that we examined did not specify when projects should take what actions to grow sustainably. This lack of specificity limits the utility for projects trying to figure out how to sustain themselves in ever-changing environments. The work necessary to develop meticulous, community-oriented files may not be a good time investment for early-stage projects with only a handful of contributors. More research is necessary to develop useful context-situated recommendations to support FLOSS projects adaptation.
This paper was presented a few weeks ago in Ottawa at the International Conference on Cooperative and Human Aspects of Software Engineering (CHASE) 2025. A pre-print of the paper can be found here; the data and code for the project can be found here.
This research wouldn’t be possible without the work of the volunteers producing FLOSS who have made their work available for inspection. We also gratefully acknowledge support from the Ford/Sloan Digital Infrastructure Initiative (Sloan Award 2018-113560) and the National Science Foundation (Grant IIS-2045055). This work was conducted using the Hyak supercomputer at the University of Washington as well as research computing resources at Northwestern University.
Does your work touch open source, communities, technology, or cooperation? Do you want to help bridge the gaps between research and practice? Join us at FOSSY! The Free and Open Source Software Yearly conference (FOSSY) is back this summer and the call for proposals is open!
“I always enjoy the blend of researcher and contributor perspectives in the Science of Community track. The presentations are always great, surpassed only by the follow up conversations in the hall afterwards!” – Matt Gaughan, CDSC member and PhD student
We’ll be running the Science of Community track, and are looking for presenters to speak to an audience of FOSS practitioners, developers, community organizers, contributors, and people just generally into and curious about FOSS.
The Science of Community track is inspired by the CDSC Science of Community Dialogues, which bring together practitioners and researchers to discuss scholarly work that is relevant to the efforts of practitioners. As researchers, we benefit so much from the communities we work with and study and we want them to also learn from the research they so generously take part in. While the Dialogues cover a broad range of topics and communities, FOSSY presentations will focus on how that work relates to free and open source software communities, projects, and practitioners.
FOSSY is a low-stress opportunity to talk to people who your work can benefit. For topics, consider presenting implications from past papers, synthesizing work from your field overall, or floating ideas and problems (lightning talks! long talks! short talks!). A full track description and answers to common questions is available on our wiki.
The CFP deadline is April 28th and uses this form.
We held our 11th Science of Community Dialogue on April 4th, with Zarine Kharazian (University of Washington) and Professor Paul Gowder (Northwestern University) sharing their research on misinformation and propaganda in online communities, limitations of approaches that neglect community governance, and insights on democratizing platforms and society.
Zarine kicked off the conversation by highlighting recent events regarding allegations and attacks on Wikipedia, and how these legitimacy attacks affect communities engagement with encyclopedic knowledge and collective sense-making infrastructures. She explored organizational and institutional approaches that could enable communities to effectively steward information commons in the face of these attacks.
In his book The Networked Leviathan, Paul advocated for more participatory and multi-level governance as a corrective to the “democratic deficit” and lack of accountability of social media platforms. In this dialogue, he discussed threats and updates to this framework in light of recent developments.
Thank you to everyone who joined us and participated in this insightful and timely conversation. We greatly appreciate Zarine and Paul taking the time to share their views and research on community governance.
We all wear a lot of hats as researchers. Cowboy hats as we lasso and wrangle data. Noir-style fedoras when we are pinning post-it’s to a wall and stringing together our evidence. Berets when we ponder over the perfect artistic metaphor to describe our results. Sitting dusty in the corner is the tocque, the baker’s cap. We don the tocque, the billowing white like a cloth mushroom, when we’re kneading our ideas and getting ready to bake them. Too often, we don’t really linger in that role, our ideas need to move forward: there are deadlines to meet and papers to publish! However, once a year, the CDSC invites its members to become bakers and play around with our half-baked ideas together in the Great Half Bake-Off.
One of the hallmark’s of the CDSC’s annual retreat, in which our distributed collective gathers at one of the member universities to be merry (and work) together in meat space for a few days, is the annual Great Half Bake-Off (GHBO). The Great Half Bake-Off is an opportunity for members of the group to present an idea in a rapid-fire way that they’re interested in. They might not know where to start with the idea, or the idea seems too big or out there to seem feasible.
The half-bake off, being a part of our retreat at the beginning of the academic year does a lot to glue the group together. With an intention of sharing an idea that we actually care about, but might in other instances be too afraid to share because it feels too undercooked, we become comfortable sharing our ideas with each other, no matter what the stage of thought we’ve put into the project idea.
The exercise helps us learn about each other as it reveals the gulf between what we all work on and what some of the projects we only dream about are. It helps us become more comfortable with airing out our inspirations and ideals. It overall encourages a moment of playfulness and camaraderie.
How Do We Bake (Or, How You Can Host Your Own Great Half Bake-Off)
The logistics for the GHBO are relatively simple. Notify your bakers at least a few weeks before your event to think about what half-baked ideas they want to bring to the table. Provide a collaborative slide deck for them to include a slide if they’d like to organize their half-baked thoughts in that way. We give our bakers 2-3 minutes (but no more!) to present their ideas, and a minute or two to field questions. Then, at the end, for the grand prize of a Silly Little Trophy, we all vote for who had the most half-baked idea. This is a key element to the process: voting on the merits not of the idea’s potential success or creativity, but the vague, unreliable measure of “half-bakedness.”
This is the slide template we give in advance, should people want to use it! Sometimes it’s nice to bake with a recipe. :’)
Some Half-Baked Categories to Prepare Your Bakers:
Long Shots – Maybe there’s a project within your repertoire, but you’re not sure how you would find the time, money, or energy to see it through. Sound’s half-baked!
Mysteries – Have a research question that you’re just not sure where even to begin to answer? Perfect!
New Flavors – Perhaps you have a project that you’re thinking about but it uses a method that you’ve never used (or even seen someone else use!)
Something Silly – We all have burning questions that might … not add a lot to the public good if we were to answer them. Now’s your chance to talk about those!
Literally anything else – by now, hopefully you get the idea. As long as it is mushy and half-baked – with enough room for your colleagues to poke at its spongy undoneness, it’s worthy of being called half-baked.
Winner of GHBO 2024, Emily Zou’s, half-baked idea!
What Comes Out of the Half-Baked Off
As we’ve discussed, the main benefits of the Great Half Bake-Off come not necessarily from the immaculate pastries that we pull out of the oven at the end of the ordeal, the goodness of the half bake off exists in the way we get to have a good time with each other, and see deeper into how we each begin to craft our doughs. In fact, more often than not, our ideas from the event many moons later remain just as half-baked as when we presented them. Sohyeon, the 2022 GHBO champion, in a 2024 update on the status of her winning project proposal gleefully remarked that “the idea remains half-baked.”
As I’m sure many before me can relate to… after a class here, a conversation with someone there, and a hop, skip, and a jump later, somehow I tumbled my way into grad school!
When I began graduate school, I knew I was interested in the intersection of health communication and online communities, but beyond that, I wasn’t entirely sure what direction I wanted to go in! Fortunately, UW is home to two labs dedicated to these areas and I have been rotating between them throughout my first year in the Communication department.
Last quarter, I started my rotation with the CDSC and began developing my first research project (!!) focused on health-related stigma trends on Reddit. I’ve always been interested in how online communities offer supplementary support for individuals dealing with health-related issues, and I knew I wanted to do something that explored how stigma impacts health-related discussion trends. Various research has been done on stigma communication in online communities. For example, Brown and colleagues (2023) investigated types of stigma tweets associated with different types of health-related stigma on X (formerly known as Twitter) and found that although stigma was prevalent for each condition they studied, anti-stigma messages were more common than the various types of stigma communication. I want to expand on this research area by diving deeper into the motivations and reasoning participants have for joining and contributing to health-related communities online!
This quarter, while I have continued working on my health-related stigma project I also have rotated into the Health Equity Action Lab (HEAL). Given my interest in online communities, I was brought onto a project examining correlates of online support in women experiencing postpartum depression.
I have since taken the lead on a subset of the data related to Internet use as a form of support. Within the HEAL study, 83% of women who sought information or support online met the criteria for postpartum depression. Research done by Stellefson and colleagues (2018) suggest that greater use of the Internet may be a result of knowledge gaps created by poor patient-provider communication. Our goal is to identify the factors that increase the likelihood of women within this population to seek out support!
Currently, I am categorizing and coding open-ended survey responses to determine whether eHealth literacy is linked to specific apps or websites as resources for information or support among women experiencing postpartum depression. So far, I have found survey participants often turn to WebMD, Reddit, and Facebook as sources of information and support.
Both my project examining health-related stigma on Reddit and my project identifying online destinations for support-seekers demonstrate how the Internet and online communities offer valuable resources for those seeking help, and foster connections with others who share similar experiences. Have you ever turned to an online community to seek out support?
Join the Community Data Science Collective (CDSC) for our 11th Science of Community Dialogue! This Community Dialogue will take place on April 4th at 12:00 pm CT. This Dialogue focuses on resisting online information manipulation and the role of community governance. Professor Paul Gowder (Northwestern University) will join Zarine Kharazian (University of Washington) to present recent research on topics including:
Exploring threats like misinformation and propaganda in online communities.
Limitations of approaches that neglect community governance.
Tradeoffs in governance models, such as those of Facebook, Bluesky, and Wikipedia.
The Community Data Science Collective (CDSC) is an interdisciplinary research group made of up of faculty and students at the University of Washington Department of Communication, the Northwestern University Department of Communication Studies, the Carleton College Computer Science Department, the School of Information at UT Austin, and the Purdue University School of Communication.
Learn more
If you’d like to learn more or get future updates about the Science of Community Dialogues, please join the low volume announcement list.
A question that’s been bugging me for the past months is how a digital medium can amplify remnants of traditional pre-modern life.
I’m only a recent addition to the Collective and, despite thinking a lot about digitality and how it affects social processes, I’ve only marginally been part of online communities myself.
However, living back and forth, in a perpetual state of limbo, between Greece and the US for the past two and a half years pursuing graduate school, I’ve inevitably become more active online.
That is when I noticed all these Facebook groups popping up in my feed (yes, I am one of those people who find comfort in the platform’s slower mechanics and less engaging feed).
Groups about life in one’s Greek village, groups about homemade traditional delicacies (as grotesque as lamb intestines and brains), groups about tsipouro (the Greek eau de vie, rakı, grappa, moonshine, …).
Those groups seem to be composed by active middle aged members, who barely know how to use the medium in socially acceptable ways devised by my generation (one of the first one’s in Greece to go online), yet spent hours posting facts about how to make cheese or definitions for words no more used, commenting on each other’s drinking habits, discussing about the “proper” way to make moussaka or arguing about the “proper” meze (small dishes, appetizers, tapas, antipasti, …) for tsipouro. On top of that, youngsters invade them as bystanders, looking, smiling, laughing, making fun of the surreal discussions, uppercase comments, text-to-speech mistakes; chaos.
I’m afraid that these groups are part of the general Zeitgeist in the country: dissapointment and longing for long-lost glory, calmness, or simplicity. It is evident in parts of its cultural production. Books about 19th century Greece, movies and TV series about times of old. A remaining obsession with ancient times. Music referring to the country’s folk traditions.
Relatedly and perhaps subconsciously associated, I recently found myself in a concert by the promising Themos Skandamis. Skandamis produces neo-folk (might I say avantgardish [?] songs) which he writes himself. During his concert, comedic elements imitating the local Cretan accent entered his performance. By the end, as a farewell he beautifully sang a capella a traditional song I’ve never heard before.
It’s lyrics follow (original sourced from here, and freely translated by myself with the benevolent help and suggestions of GPT-4):
Για δες περβό… για δες περβόλιν όμορφο, για δες κατάκρυα βρύση το περιβόλι μας για δες κατάκρυα βρύση το περβό… τ’ όριο περβόλι μας τ’ όμορφο.
Κι όσα δέντρα κι όσα δέντρα ‘πεμψεν ο Θιος, μέσα είναι φυτεμένα το περιβόλι μας μέσα είναι φυτεμένα το περβό… τ’ όριο περβόλι μας τ’ όμορφο.
Κι όσα πουλιά κι όσα πουλιά πετούμενα, μέσα είναι φωλεμένά το περιβόλι μας μέσα είναι φωλεμένα το περβό… τ’ όριο περβόλι μας τ’ όμορφο.
Μέσα σε ‘κεί… μέσα σε ‘κείνα (ν)τα πουλιά, εβρέθη ένα παγώνι το παγωνάκι μας εβρέθη ένα παγώνι το παγώ… τ’ όριο παγώνι μας τ’ όμορφο.
Και χτίζει τη και χτίζει τη φωλίτσα του, σε μιας μηλιάς κλωνάρί το παγωνάκι μας σε μιας μηλιάς κλωνάρι το παγώ… τ’ όριο παγώνι μας τ’ όμορφο.
Behold the garden… behold our garden’s beauty, behold the cool spring, our garden behold the cool spring, our gard… our garden’s beauty.
And all the trees, all the trees God has sent, are planted in, our garden are planted in, our gard… our garden’s beauty.
And all the bird and all the birds that roam the skies, have nested in, our garden have nested in, our gard… our garden’s beauty.
Among those birds… among those birds, a peacock found, our little peacock, a peacock found, the pea… our peacock’s beauty.
And it builds its… and it builds its nest, on the apple tree’s branch, our peacock on the apple tree’s branch, the pea… our peacock’s beauty.
I kept wondering, what does it mean, and most importantly why a traditional folk song would mark the end of the concert.
And then it strike me, there is this clear metaphor and parallelism between the peacock and digitality. The peacock appears out of context, yet builds its nest in the garden. Digital media invade our analog lives and impose themselves; they become addictively habitual and naturalized.
What is interesting though here is the reversal of roles. The digital sphere, now established, turned into a garden, leaves room for trad life to invade post-modernity; whether it is a cause or an effect of the world’s turmoil remains to be seen.
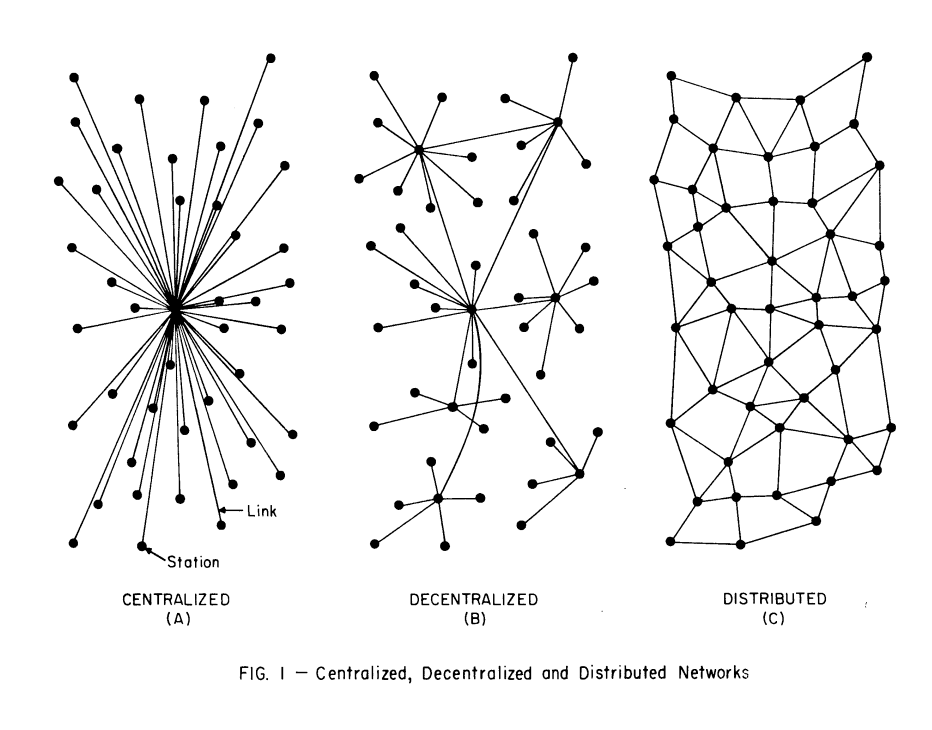
Figure from Paul Baran’s 1964 article “On distributed communications networks” (https://doi.org/10.1109/TCOM.1964.1088883) and referenced by Christine Lemmer-Webber.
Afterwards, two of the eponymous “thought-leaders” who headlined that session, Christine Lemmer-Webber and Bryan Newbold followed up with each other in a series of blogposts about decentralization, Bluesky, and the Fediverse.
I recently re-read these while preparing for a guest lecture in an undergraduate class here at NU. Fair warning: Despite the subtext of a debate about systems mainly used for micro-blogging, the posts are very long. That said, if you care about these topics (or are maybe just curious to learn more), all three are pure gold.
It helps to understand a bit about exactly who Christine and Bryan are, or more specifically, why they have among the very most informed and interesting perspectives on the topic. Christine helped to create the ActivityPub protocol and standard that is at the heart of the Fediverse (Mastodon, Lemmy, Pixelfed, PeerTube). She currently leads the Spritely Institute pursuing the design and implementation of the next generation of decentralized communication tech. Bryan is the protocol engineer at Bluesky and, as such, one of the leaders building out the AT Protocol, which powers Bluesky and a whole other small-but-seemingly-growing ecosystem of applications.
The crux of their conversation revolves around the competing visions for the future of the social web being pursued within the respective ActivityPub and AT Protocol “universes.” The posts underscore some of the more profound differences between the two, in particular the questions around “shared heap” vs. “message passing” architectures, the relative degree of (de)centralization each system affords (this is where the diagram originally created by Paul Baran and reproduced at the top of this post comes in), and (more implicitly) the theories of change motivating the design and implementation choices prioritized in their respective work.
It’s worth nothing that both Bryan and Christine are very careful and intentional to call out the overlaps between ActivityPub and AT Proto as well. I also appreciate how respectful and thoughtful they each are given that there are some substantive and high stakes areas of disagreement being addressed in their conversation.
If you read the posts (and I hope you do!) and want to share your responses, please do so in the comments, via email, Toot, Skeet, or sundry other means. There are several of us in the lab pursuing work in these areas and I’m eager to understand perspectives on the topic.
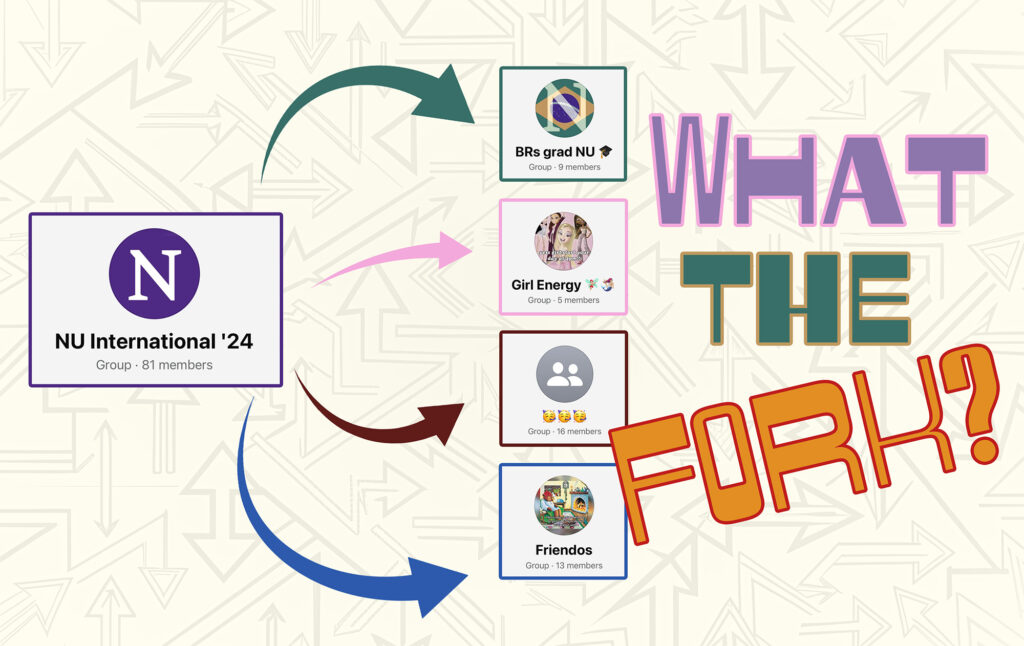
Everyone knows that making friends can be a bit daunting as a new student (especially international or if you’re not from the area). With that in mind, a while after I arrived in Chicago to begin my PhD program last Fall, a Brazilian friend and I made a Northwestern WhatsApp group for international graduate students! Since the point of the group was to make friends, we were pretty laid back in there (still are!), and people mostly shared events across campus and the city of Evanston and Chicago – especially those offering free food.
At some point, the group started to grow fast, and my friend and I lost track of people who were joining. It reached 81(!) members. Eventually, we started to make sub-groups. First, we made a group for the Brazilian grad students; then another group was made for the women called “Girl Energy”; later, one of my friends made a group only for Latinos (the name is interestingly only “🥳🥳🥳”). Lastly, the group “Friendos” emerged, including our guy friends this time!
After a while, activity on the all international grad students group died down. It goes weeks without a message. People have basically spread out into smaller groups. Now… Why is that?
I went to my advisor (Aaron Shaw) and we basically started geeking out. I didn’t plan on doing some random experiment, but I accidentally observed what is called a “fork” of online communities!
To better explain this, let’s go back to the 1970s. Albert O. Hirschman published the influential book Exit, Voice, and Loyalty: Responses to Decline in Firms, Organizations, and States. In the book, Hirschman makes the argument that consumers can show their dissatisfaction in two ways: they can either exit (stop using that service or buying that product) or they can use voice (communicate a complaint and try to suggest a change). The simplicity of this argument makes it applicable in a range of different fields, such as “personal relationships, emigration, workplace relations, political parties, as well as public policy” (Dowding, 2016). And, more recently, online communities!
There are a lot of works based on Hirschman’s book, and mostly recently the idea of “fork” has also been added as a concept together with exit and voice:
“Forking is a form of group secession (exit) that takes an existing set of institutions and creates a new ‘society’ with a shared history but divergent futures.” (Berg and Berg, 2020)
The term originally comes from open source software communities, where developers are allowed to copy a code repository, work on it separately, modify it, and release it in different forms. Seeing it this way, it makes a lot of sense that it could be applied to online communities as well. In fact, studies related to online community migration keep growing. For example, Fiesler and Dym (2020) explored how transformative fandom communities migrate across platforms over a period of 20 years. Migration was driven by changes in platform policies, user needs, or technical issues. Their work highlights how these migrations can lead to social fragmentation, the loss of shared cultural artifacts, and the reformation of communities in new spaces.
In our case, the international graduate students’ group provided the foundation for forming meaningful connections. However, as people developed closer friendships and found more specific communities of interest (e.g., Brazilian grad students or Girl Energy), the need for the larger, general group diminished. This isn’t necessarily a sign of failure for the original community but rather an indication of its success in fulfilling its initial purpose!
It’s fascinating to observe how the lifecycle of online communities can parallel theoretical concepts like Hirschman’s exit, voice, and loyalty and grow from there. These frameworks help explain not just why communities evolve but also how users actively shape their social environments to meet their changing needs. Have you noticed similar patterns in the communities you’re a part of?


 Winner of GHBO 2024, Emily Zou’s, half-baked idea!
Winner of GHBO 2024, Emily Zou’s, half-baked idea!