Why learning some statistics and some data visualization matters. (Gif from Matejka and Fitzmaurice, “Same stats, different graphs”, CHI 2017: https://dl.acm.org/citation.cfm?id=3025912)
I taught a graduate-level introduction to applied statistics and statistical computing this past Spring. The course design iterated on a class Mako developed in 2017. Very nearly all of the course materials are available open access through the Community Data Science Collective wiki and I wanted to make sure to share them more widely with this post. I’ve also been reflecting a bit on how the course went and thought I’d share those thoughts here in case anyone wants to adopt the course in the future.
First off, the course uses the OpenIntro Statistics (3rd edition) textbook as the core of the course readings and assignments. If you’re not familiar with OpenIntro and you want to learn or teach applied statistics from a general, social scientific perspective, you should check it out! All of the data, code, and LaTeX used to produce the textbook is licensed freely for reuse and the site also hosts video lectures, lecture notes, homework assignments, a discussion forum and more.
Alongside the OpenIntro materials, I worked together with Jeremy Foote (who was the TA for the course before he left to be new faculty at Purdue) to develop a bunch of tutorials in RMarkdown to help students complete the problem set assignments. We also posted worked solutions to the problem sets (also in RMarkdown). These replicated and expanded on screencasts Mako had recorded for his course.
The classroom sessions focused on discussion and problem solving. Basically, students came to each session knowing that I expected them to have completed the problem sets. I then did my best to answer any questions people had and assigned individuals (in some cases using a randomization script in R to pick names!) to summarize their solutions and approaches to specific problems that seemed important to cover.
It was my first time teaching a course like this and I had a few reflections after completing the quarter and reading through the feedback from students.
A major challenge for a course like this is pitching the material to an appropriate level given that students (in the MTS and TSB programs here at Northwestern at least) arrive with such varied knowledge of the subject matter. I think I did okay on this front in some ways and not in others. It was especially challenging given the semi-flipped classroom approach.
In some weeks, there was just too much material to cover in adequate depth. In some others, I was insufficiently organized and concise to cover everything. Whatever the case, I would cut back a bit next time. (I’ve noticed that this is a common issue for me the first time I teach any class, but I still struggle to correct it.)
Whatever challenges and failures I may have introduced in the design or instruction of the course, the students produced a bunch of highly original and engaging final projects. I’m optimistic that some of these projects will wind up as published work soon. Nothing like brilliant, motivated students to help the professor feel better about his own shortcomings!
Nearly all of the course materials are available on the CDSC wiki. The exceptions are a few of the readings and supplementary materials that I didn’t have the rights or desire to post on the public web. If you’re looking for any of that, feel free to send me an email and I can see if it’s appropriate to share.
Also, OpenIntro just came out with the fourth edition of their statistics textbook! I haven’t had a chance to check it out yet, but I’m eager to see what kinds of changes they introduced.
This post was co-authored by Benjamin Mako Hill and Aaron Shaw. We wrote it following a conversation with the CSCW 2018 papers chairs. At their encouragement, we put together this proposal that we plan to bring to the CSCW town hall meeting. Thanks to Karrie Karahalios, Airi Lampinen, Geraldine Fitzpatrick, and Andrés Monroy-Hernández for engaging in the conversation with us and for facilitating the participation of the CSCW community.
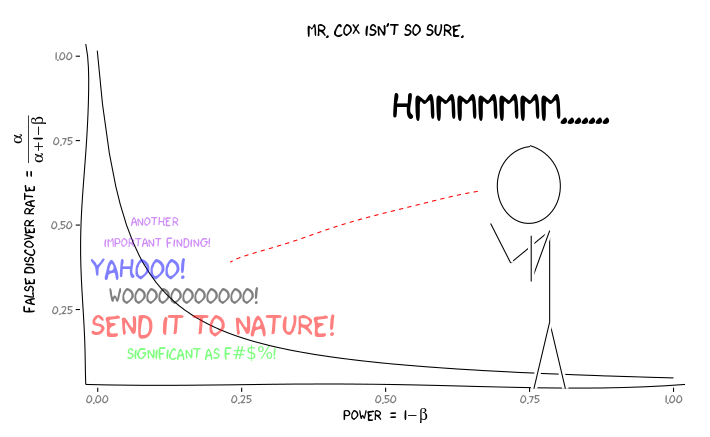
Quantitative methodologists argue that the high rates of false discovery are, among other reasons, a function of common research practices carried out in good faith. Such practices include accidental or intentional p-hacking where researchers try variations of their analysis until they find significant results; a garden of forking paths where researcher decisions lead to a vast understatement of the number of true “researcher degrees of freedom” in their research designs; the file-drawer problem which leads only statistically significant results to be published; and underpowered studies, which make it so that only overstated effect sizes can be detected.
Graph of the relationship between statistical power and the rates of false discovery. [Taken from this answer on the statistics Q&A site Cross Validated.]
To the degree that much of CSCW and HCI use the same research methods and approaches as these other social scientific fields, there is every reason to believe that these issues extend to social computing research. Of course, given that replication is exceedingly rare in HCI, HCI researchers will rarely even find out that a result is wrong.
To date, no comprehensive set of solutions to these issues exists. However, scholarly communities can take steps to reduce the threat of false discovery. One set of approaches to doing so involves the introduction of changes to the way quantitative studies are planned, executed, and reviewed. We want to encourage the CSCW community to consider supporting some of these practices.
Among the approaches developed and adopted in other research communities, several involve breaking up research into two distinct stages: a first stage in which research designs are planned, articulated, and recorded; and a second stage in which results are computed following the procedures in the recorded design (documenting any changes). This stage-based process ensures that designs cannot shift in ways that shape findings without some clear acknowledgement that such a shift has occurred. When changes happen, adjustments can sometimes be made in the computation of statistical tests. Readers and reviewers of the work can also have greater awareness of the degree to which the statistical tests accurately reflect the analysis procedures or not and adjust their confidence in the findings accordingly.
Versions of these stage-based research designs were first developed in biomedical randomized controlled trials (RCTs) and are extremely widespread in that domain. For example, pre-registration of research designs is now mandatory for NIH funded RCTs and several journals are reviewing and accepting or rejecting studies based on pre-registered designs before results are known.
A proposal for CSCW
In order to address the challenges posed by false discovery, CSCW could adopt a variety of approaches from other fields that have already begun to do so. These approaches entail more or less radical shifts to the ways in which CSCW research gets done, reviewed, and published.
As a starting point, we want to initiate discussion around one specific proposal that could be suitable for a number of social computing studies and would require relatively little in the way of changes to the research and reviewing processes used in our community.
Drawing from a series of methodological pieces in the social sciences ([1], [2], [3]), we propose a method based on split-sample designs that would be entirely optional for CSCW authors at the time of submission.
Essentially, authors who chose to do so could submit papers which were written—and which will be reviewed and revised—based on one portion of their dataset with the understanding that the paper would be published using identical analytic methods also applied to a second, previously un-analyzed portion of the dataset. Authors submitting under this framework would choose to have their papers reviewed, revised and resubmitted, and accepted or rejected based on the quality of the research questions, framing, design, execution, and significance of the study overall. The decision would not be based on the statistical significance of final analysis results.
The idea follows from the statistical technique of “cross validation,” in which an analysis is developed on one subset of data (usually called the “training set”) and then replicated on at least one other subset (the “test set”).
To conduct a project using this basic approach, a researcher would:
Randomly partition their full dataset into two (or more) pieces.
Design, refine, and complete their analysis using only one piece identified as the training sample.
Undergo the CSCW review process using the results from this analysis of the training sample.
If the submission receives a decision of “Revise and Resubmit,” authors would then make changes to the analysis of the training sample as requested by ACs and reviewers in the current normal way.
If the paper is accepted for publication, the authors would then (and only then) run the final version of the analysis using another piece of their data identified as the test sample and publish those results in the paper.
We expect that authors would also publish the training set results used during review in the online supplement to their paper uploaded to the ACM Digital Library.
Like any other part part of a paper’s methodology, the split sample procedure would be documented in appropriate parts of the paper.
We are unaware of prior work in social computing that has applied this process. Researchers in data mining, machine learning, and related fields of computer science use cross-validation all the time, they do so differently in order to solve distinct problems (typically related to model overfitting).
The main benefits of this approach (discussed in much more depth in the references at the beginning of this section) would be:
Heightened reliability and reproducibility of the analysis.
Reduced risk that findings reflect spurious relationships, p-hacking, researcher or reviewer degrees of freedom, or other pitfalls of statistical inference common in the analysis of behavioral data—i.e., protection against false discovery.
A procedural guarantee that the results do not determine the publication (or not) of the work—i.e., protection against publication bias.
The most salient risk from the approach is that results might change when authors run the final analysis on the test set. In the absence of p-hacking and similar issues, such changes will usually be small and will mostly impact the magnitude of effects estimates and their associated standard errors. However, some changes might be more dramatic. Dealing with changes of this sort would be harder for authors and reviewers and would potentially involve something along the lines of the shepherding that some papers receive now.
Let’s talk it over!
This blog post is meant to spark a wider discussion. We hope this can happen during CSCW this year and beyond. We believe the procedure we have proposed would enhance the reliability of our work and is workable in CSCW because it involves narrow changes to the way that quantitative CSCW research and reviewing is usually conducted. We also believe this procedure would serve the long term interests of the HCI and social computing research community. CSCW is a leader in building better models of scientific publishing within HCI through the R&R process, eliminated page limits, the move to PACM, and more. We would like to extend this spirit to issues of reproducibility and publication bias. We are eager to discuss our proposal and welcome suggestions for changes.
Michael L Anderson and Jeremy Magruder. Split-sample strategies for avoiding false discoveries. Technical report, National Bureau of Economic Research, 2017. https://www.nber.org/papers/w23544
Susan Athey and Guido Imbens. Recursive partitioning for heterogeneous causal effects. Proceedings of the National Academy of Sciences, 113(27):7353–7360, 2016. https://doi.org/10.1073/pnas.1510489113
Marcel Fafchamps and Julien Labonne. Using split samples to improve inference on causal effects. Political Analysis, 25(4):465–482, 2017. https://doi.org/10.1017/pan.2017.22
Couchsurfing and Airbnb are websites that connect people with an extra guest room or couch with random strangers on the Internet who are looking for a place to stay. Although Couchsurfing predates Airbnb by about five years, the two sites are designed to help people do the same basic thing and they work in extremely similar ways. They differ, however, in one crucial respect. On Couchsurfing, the exchange of money in return for hosting is explicitly banned. In other words, couchsurfing only supports the social exchange of hospitality. On Airbnb, users must use money: the website is a market on which people can buy and sell hospitality.
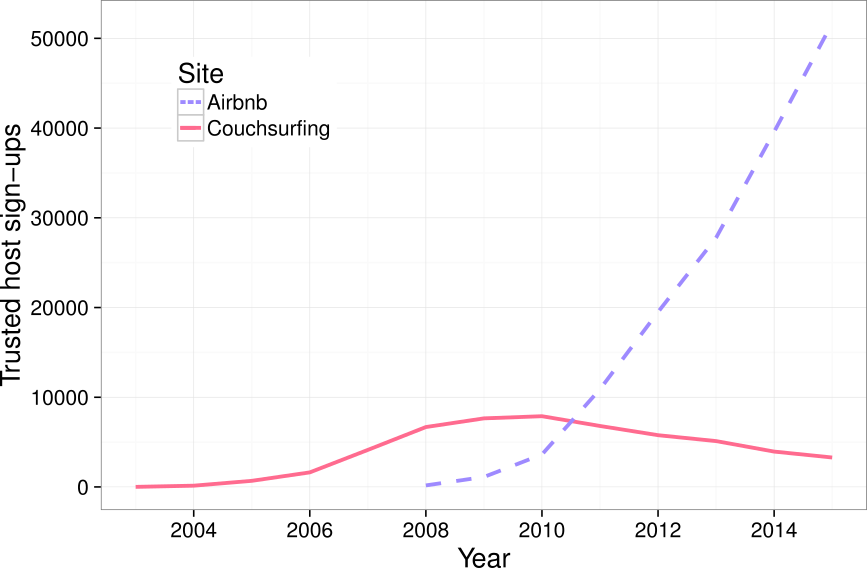
Comparison of yearly sign-ups of trusted hosts on Couchsurfing and Airbnb. Hosts are “trusted” when they have any form of references or verification in Couchsurfing and at least one review in Airbnb.
The figure above compares the number of people with at least some trust or verification on both Couchsurfing and Airbnb based on when each user signed up. The picture, as I have argued elsewhere, reflects a broader pattern that has occurred on the web over the last 15 years. Increasingly, social-based systems of production and exchange, many like Couchsurfing created during the first decade of the Internet boom, are being supplanted and eclipsed by similar market-based players like Airbnb.
In a paper led by Max Klein that was recently published and will be presented at the ACM Conference on Computer-supported Cooperative Work and Social Computing (CSCW) which will be held in Jersey City in early November 2018, we sought to provide a window into what this change means and what might be at stake. At the core of our research were a set of interviews we conducted with “dual-users” (i.e. users experienced on both Couchsurfing and Airbnb). Analyses of these interviews pointed to three major differences, which we explored quantitatively from public data on the two sites.
First, we found that users felt that hosting on Airbnb appears to require higher quality services than Couchsurfing. For example, we found that people who at some point only hosted on Couchsurfing often said that they did not host on Airbnb because they felt that their homes weren’t of sufficient quality. One participant explained that:
“I always wanted to host on Airbnb but I didn’t actually have a bedroom that I felt would be sufficient for guests who are paying for it.”
An another interviewee said:
“If I were to be paying for it, I’d expect a nice stay. This is why I never Airbnb-hosted before, because recently I couldn’t enable that [kind of hosting].”
We conducted a quantitative analysis of rates of Airbnb and Couchsurfing in different cities in the United States and found that median home prices are positively related to number of per capita Airbnb hosts and a negatively related to the number of Couchsurfing hosts. Our exploratory models predicted that for each $100,000 increase in median house price in a city, there will be about 43.4 more Airbnb hosts per 100,000 citizens, and 3.8 fewer hosts on Couchsurfing.
A second major theme we identified was that, while Couchsurfing emphasizes people, Airbnb places more emphasis on places. One of our participants explained:
“People who go on Airbnb, they are looking for a specific goal, a specific service, expecting the place is going to be clean […] the water isn’t leaking from the sink. I know people who do Couchsurfing even though they could definitely afford to use Airbnb every time they travel, because they want that human experience.”
In a follow-up quantitative analysis we conducted of the profile text from hosts on the two websites with a commonly-used system for text analysis called LIWC, we found that, compared to Couchsurfing, a lower proportion of words in Airbnb profiles were classified as being about people while a larger proportion of words were classified as being about places.
Finally, our research suggested that although hosts are the powerful parties in exchange on Couchsurfing, social power shifts from hosts to guests on Airbnb. Reflecting a much broader theme in our interviews, one of our participants expressed this concisely, saying:
“On Airbnb the host is trying to attract the guest, whereas on Couchsurfing, it works the other way round. It’s the guest that has to make an effort for the host to accept them.”
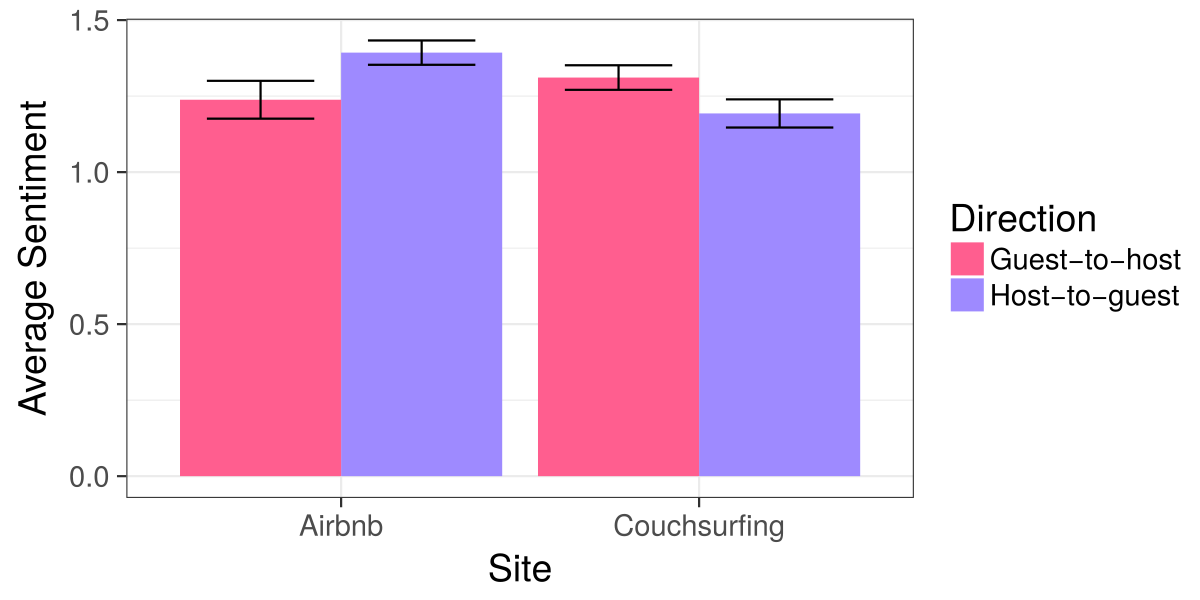
Previous research on Airbnb has shown that guests tend to give their hosts lower ratings than vice versa. Sociologists have suggested that this asymmetry in ratings will tend to reflect the direction of underlying social power balances.
Average sentiment score of reviews in Airbnb and Couchsurfing, separated by direction (guest-to-host, or host-to-guest). Error bars show the 95% confidence interval.
We both replicated this finding from previous work and found that, as suggested in our interviews, the relationship is reversed on Couchsurfing. As shown in the figure above, we found Airbnb guests will typically give a less positive review to their host than vice-versa while in Couchsurfing guests will typically a more positive review to the host.
As Internet-based hospitality shifts from social systems to the market, we hope that our paper can point to some of what is changing and some of what is lost. For example, our first result suggests that less wealthy participants may be cut out by market-based platforms. Our second theme suggests a shift toward less human-focused modes of interaction brought on by increased “marketization.” We see the third theme as providing somewhat of a silver-lining in that shifting power toward guests was seen by some of our participants as a positive change in terms of safety and trust in that guests. Travelers in unfamiliar places often are often vulnerable and shifting power toward guests can be helpful.
Although our study is only of Couchsurfing and Airbnb, we believe that the shift away from social exchange and toward markets has broad implications across the sharing economy. We end our paper by speculating a little about the generalizability of our results. I have recently spoken at much more length about the underlying dynamics driving the shift we describe in my recent LibrePlanet keynote address.
More details are available in our paper which we have made available as a preprint on our website. The final version is behind a paywall in the ACM digital library.
Every CASBS study is labeled with a list of “ghosts” who previously occupied the study. This year, I’m spending the year in Study 50 where I’m haunted by an incredible cast that includes many people whose scholarship has influenced and inspired me.
The top part of the list of ghosts in Study #50 at CASBS.
Foremost among this group is Study 50’s third occupant: Claude Shannon.¹
At 21 years old, Shannon’s masters thesis (sometimes cited as the most important masters thesis in history) proved that electrical circuits could encode any relationship expressible in Boolean logic and opened the door to digital computing. Incredibly, this is almost never cited as Shannon’s most important contribution. That came in 1948 when he published a paper titled A Mathematical Theory of Communication which effectively created the field of information theory. Less than a decade after its publication, Aleksandr Khinchin (the mathematician behind my favorite mathematical constant) described the paper saying:
Rarely does it happen in mathematics that a new discipline achieves the character of a mature and developed scientific theory in the first investigation devoted to it…So it was with information theory after the work of Shannon.
As someone whose own research is seeking to advance computation and mathematical study of communication, I find it incredibly propitious to be sharing a study with Shannon.
Although I teach in a communication department, I know Shannon from my background in computing. I’ve always found it curious that, despite the fact Shannon’s 1948 paper is almost certainly the most important single thing ever published with the word “communication” in its title, Shannon is rarely taught in communication curricula is sometimes completely unknown to communication scholars.
In this regard, I’ve thought a lot about this passage in Robert’s Craig’s influential article “Communication Theory as a Field” which argued:
In establishing itself under the banner of communication, the discipline staked an academic claim to the entire field of communication theory and research—a very big claim indeed, since communication had already been widely studied and theorized. Peters writes that communication research became “an intellectual Taiwan-claiming to be all of China when, in fact, it was isolated on a small island” (p. 545). Perhaps the most egregious case involved Shannon’s mathematical theory of information (Shannon & Weaver, 1948), which communication scholars touted as evidence of their field’s potential scientific status even though they had nothing whatever to do with creating it, often poorly understood it, and seldom found any real use for it in their research.
In preparation for moving into Study 50, I read a new biography of Shannon by Jimmy Soni and Rob Goodman and was excited to find that Craig—although accurately describing many communication scholars’ lack of familiarity—almost certainly understated the importance of Shannon to communication scholarship.
For example, the book form of Shannon’s 1948 article was published by University Illinois on the urging of and editorial supervision of Wilbur Schramm (one of the founders of modern mass communication scholarship) who was a major proponent of Shannon’s work. Everett Rogers (another giant in communication) devotes a chapter of his “History of Communication Studies”² to Shannon and to tracing his impact in communication. Both Schramm and Rogers built on Shannon in parts of their own work. Shannon has had an enormous impact, it turns out, in several subareas of communication research (e.g., attempts to model communication processes).
Although I find these connections exciting. My own research—like most of the rest of communication—is far from the substance of technical communication processes at the center of Shannon’s own work. In this sense, it can be a challenge to explain to my colleagues in communication—and to my fellow CASBS fellows—why I’m so excited to be sharing a space with Shannon this year.
Upon reflection, I think it boils down to two reasons:
Shannon’s work is both mathematically beautiful and incredibly useful. His seminal 1948 article points to concrete ways that his theory can be useful in communication engineering including in compression, error correcting codes, and cryptography. Shannon’s focus on research that pushes forward the most basic type of basic research while remaining dedicated to developing solutions to real problems is a rare trait that I want to feature in my own scholarship.
Shannon was incredibly playful. Shannon played games, juggled constantly, and was always seeking to teach others to do so. He tinkered, rode unicycles, built a flame-throwing trumpet, and so on. With Marvin Minsky, he invented the “ultimate machine”—a machine that’s only function is to turn itself off—which he kept on his desk. A version of the Shannon’s “ultimate machine” that is sitting on my desk at CASBS.
I have no misapprehension that I will accomplish anything like Shannon’s greatest intellectual achievements during my year at CASBS. I do hope to be inspired by Shannon’s creativity, focus on impact, and playfulness. In my own little ways, I hope to build something at CASBS that will advance mathematical and computational theory in communication in ways that Shannon might have appreciated.
Incredibly, the year that Shannon was in Study 50, his neighbor in Study 51 was Milton Friedman. Two thoughts: (i) Can you imagine?! (ii) I definitely chose the right study!
Rogers book was written, I found out, during his own stint at CASBS. Alas, it was not written in Study 50.
Forming: Group members get to know each other and define their task.
Storming: Through argument and disagreement, power dynamics emerge and are negotiated.
Norming: After conflict, groups seek to avoid conflict and focus on cooperation and setting norms for acceptable behavior.
Performing: There is both cooperation and productive dissent as the team performs the task at a high level.
Fortunately for organizational science, 1965 was hardly the last stage of development for Tuckman’s theory!
Twelve years later, Tuckman suggested that adjourning or mourning reflected potential fifth stages (Tuckman and Jensen 1977). Since then, other organizational researchers have suggested other stages including transforming and reforming (White 2009), re-norming (Biggs), and outperforming (Rickards and Moger 2002).
What does the future hold for this line of research?
The good news is that despite the active stream of research producing new stages that end or rhyme with -orming, there are tons of great words left!
For example, stages in a group’s development might include:
Scorning: In this stage, group members begin mocking each other!
Misinforming: Groups that reach this stage start producing fake news.
Shoehorning: These groups try to make their products fit into ridiculous constraints.
Chloroforming: Groups become languid and fatigued?
One benefit of keeping our list in the wiki is that the organizational research community can use it to coordinate! If you are planning to use one of these terms—or if you know of a paper that has—feel free to edit the page in our wiki to “claim” it!
Many organizations have unprecedented access to data, experiments, and statistical inference. The diffusion of these resources has created pressure to develop the skills and practices necessary to use them. However, the distribution of these skills and practices has an organizational component, leading some teams and organizations to harness social scientific insights far more effectively than others.
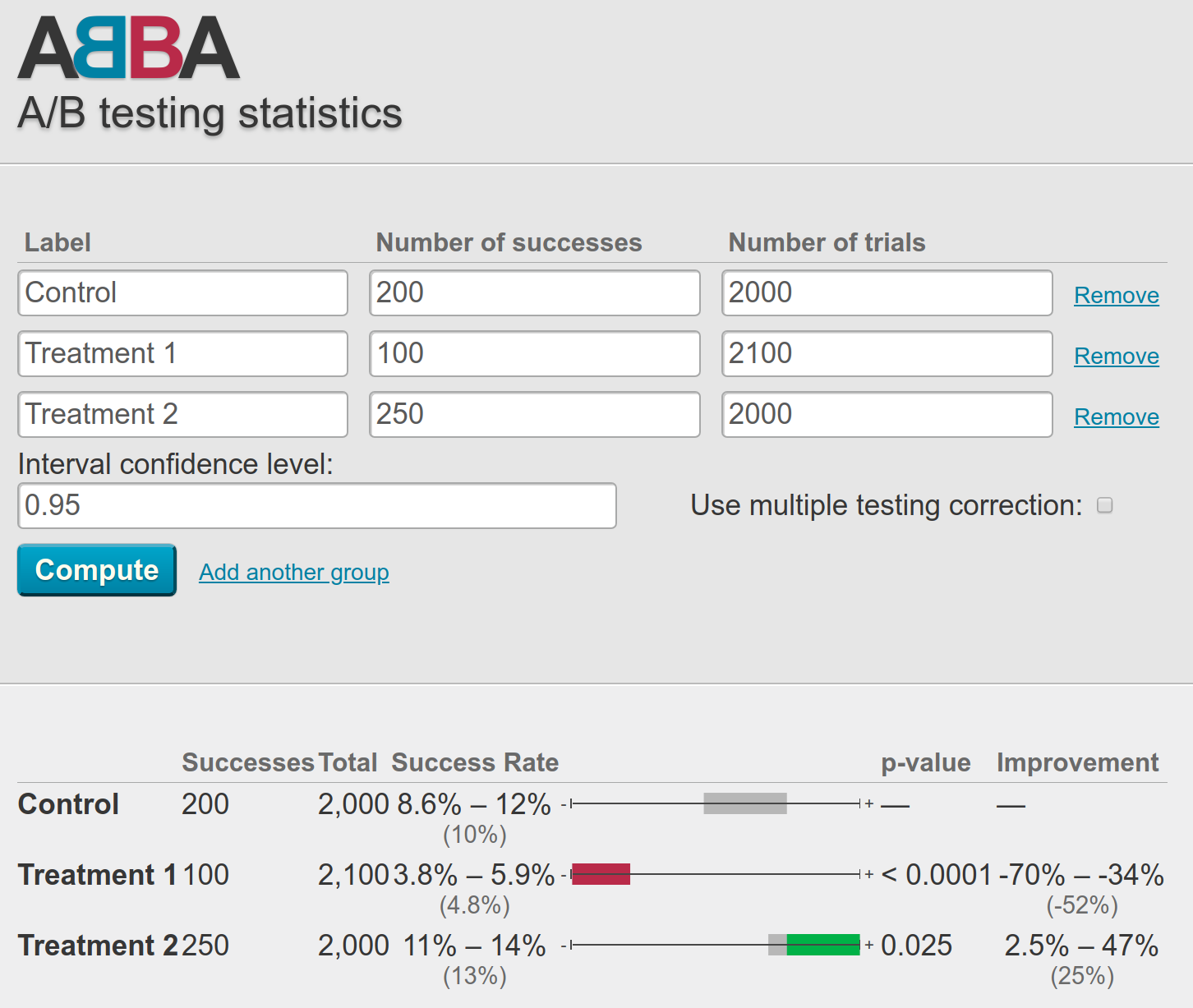
Handy web-based tools like ABBA can make a-b testing more accessible
We hear plenty about examples of “bad” statistics in the news. For example, Brian Wansink and the Cornell Food Lab have gotten a whole lot of attention for problems in their statistical analysis and interpretation. More than sheer ignorance or malfeasance (although there may be some evidence of that too), I think the reproducibility crisis illustrates how pervasive pressure to produce statistical evidence has combined with uneven professional standards can lead to dodgy research.
Our capacity to gather data and apply inferential statistics may have gotten ahead of our collective ability to manage these resources skillfully. In academia, this might lead to publications with spurious findings. In other kinds of environments, it might lead to decisions based on evidence of questionable quality. In both cases organizational resource constraints and communication challenges shape whether, where, and how well data science and statistics get done.
A slightly long story illustrates how this can play out in a non-academic environment, specifically a fairly small technology company. I share the story as a cautionary tale that can hopefully provoke some useful reflection about how we (people who care about evidence-based decision making, data science, statistics, and applied social science) can improve our work. I have de-identified the organization and the individuals involved because this is really not about them per se. The challenges they face are common. I think the story can tell us something interesting about those challenges.
Within the organization, several teams conduct experiments, user tests, and other sorts of data-intensive, social scientific research. One of these teams had reached out because they had some questions about methods of analysis. Within the organization, this particular team had gotten positive feedback for their adoption of a data-driven pipeline of A/B testing, but there were concerns about whether the testing was being done well. I went to visit them planning to do a little bit of informal statistical consulting and to learn more about that part of the organization.
A few team members walked me through a typical field experiment with multiple (about 10) treatment conditions. Everything runs on a small stack of custom scripts that pulled summary data from the platform’s databases. The team uses spreadsheets to record the number of individuals assigned to each condition along with the number of “successful” trials (e.g., cases where an end-user has the desired response to a given design change).
The team then enters the raw summary information into an open source web-based tool called ABBA that runs some calculations and reports a “success rate” (a smoothed percentage) for each trial, a raw and percentage-based confidence interval for the success rate, and a p-value (based on a binomial cumulative distribution function or a normal approximation for large samples). ABBA also presents a handy little visualization plotting the interval estimated for each experimental condition along a bar colored either gray (not different from control), red (lower success rate than control), or green (higher success rate than control) depending on the results of the corresponding hypothesis test. I’ve included a screenshot of what this looks like at the top of the post and you can try it yourself.
Those of you with a statistical background following me into the weeds here might be nodding and thinking “okay, sounds maybe not ideal, but reasonable enough.” While the system puts too much faith in p-values, it follows a pretty standard approach. It’s also a great example of the kind of statistics-as-a-service approach to A/B testing that many organizations have adopted in response to various pressures to be more data driven.
That’s when things started to get weird. As we spoke more, it turned out that the ways members of the team conduct the tests, enter the data, and interpret the results raise major red flags.
For example, they regularly update the number of experimental conditions on-the-fly, dropping old conditions and adding new conditions when others already had thousands of observations (ABBA makes this super easy!).
When experimental conditions are dropped or added, the team routinely re-computes statistical tests and p-values with/without the new/old observations included. Mostly, conditions that do not seem to produce different outcomes from the control were silently removed from the analysis.
For some of the analysis itself, the team uses parametric tests that assume normal distributions on heavily skewed data.
Then, when it comes time to interpret the results, the analysts use the relative magnitude of p-values as an estimate of the magnitude of conditional effect sizes.
At this point, those of you with relevant training in applied statistics, experimental research methods, data science, etc. might be scratching your heads or experiencing full-on panic.
Separately, each of these steps are inferential howlers capable of invalidating results. Together, they render whatever results were coming out of this process untrustworthy in the extreme.
For the rest of the meeting, I did my best to identify a series of steps the team could take to avoid the problems above. But I still walked away disconcerted. This was a technically sophisticated organization with plenty of resources. The team was using a pretty well-designed tool for analyzing experimental data. They had gotten critical feedback on the work they were doing. How did a situation like this happen?
The individuals on the team were doing their best. Nobody is born with deep knowledge of applied statistics. Confronted with a challenging mandate from their supervisors, these people were all doing their absolute best to apply some tools they didn’t fully understand to solve a practical problem. They had generally been told that their work was good, knew they had some issues to fix, and reached out to someone with more knowledge (in this case me) for help.
What about the tools? Can we at least blame the tools? As I mentioned earlier, a bunch of companies are in the business of providing “statistics-as-a-service” or A/B testing platforms, but I’m not convinced that these are the root of the problem either. Sure, ABBA makes some mistakes a little too easy, but the tool was also built and shared by skilled data scientists who painstakingly documented everything before distributing it on GitHub. Their documentation is why I was able to sort out exactly what was happening in the first place and help the team members understand some of the issues involved. Indeed, nothing seems obviously or fundamentally wrong with the implementation of the underlying software or the statistical tests. Instead, the misuse of the system happened despite the software designers’ best efforts.
Here we get into one problem area: the incentives to produce specific kinds of outcomes. The team using the tool needed to run experiments and interpret them as decisive “wins” or “losses.” The reality was much less clear and, in this way, the p-values obscured some of that ambiguity. Imposing a dichotomous logic on experimental evidence is often impossible and will, even under the best conditions, lead to systematic abuses of statistical reasoning.
What about the organizational leadership then? Shouldn’t they be responsible for making sure that the company does high quality data science? On the one hand yes, and on the other hand, this is hard too and understandable problems arise. Executives and managers often lack the requisite statistical expertise to evaluate operations like this in a rigorous way. They have heard, through professional networks, industry publications, media, etc., that more data and more A/B tests are Good Things for their organization. At a certain point, they cannot do the auditing of experimental procedures and inference themselves.
Shouldn’t the managers just make sure someone else can audit the statistics then? This is probably where the most important breakdowns occurred. Turns out that other staff possess all the skills to diagnose and repair the issues I identified (and more). One of these people had even been assigned to work with the team in question for a while! However, that assignment had ended during a restructuring and statistical expertise had never returned to the team. In the meantime, managers continued to demand results without fully appreciating that the existing approach had deep problems.
So given this particular mix of data and organizational sciences gone awry, what lessons can we learn?
The future of data-intensive social science remains, as William Gibson might say, unevenly distributed. As the infrastructure for data collection and analysis has become more widely accessible, the choke-point in many organizations has become the dissemination of deeper knowledge of the techniques necessary to produce valid, reliable inference. These inequalities emerge both within and between organizations. Some companies and some teams have more expertise than others. Some have more effective systems for feedback and improvement than others.
In this sense, organizational (not just technical or statistical) obstacles stand in the way of more effective, accountable, and transparent uses of evidence to make decisions. Web-scale organizations can run 100,000 randomized trials and analyze the results very quickly. The results can look real and have p-values attached and the executives can believe that they have got the whole data science thing nailed down. However, the analysis might not mean much unless it is implemented skillfully.
The inundation of behavioral trace data does not guarantee that we will be similarly inundated by reliable findings, valid inference, or skilled implementation. High quality research design and interpretation may not scale so easily as the data or the analysis tools.
All of this has distributive implications. Organizations with access to the best social scientific knowledge as well as the organizational capacity to deploy and harness that knowledge will be the ones most likely to reap benefits from it. Others, such as many public administrations in the U.S. (especially those that deliver social services), smaller firms, non-profits, and community organizations will likely get inferior inference (to the extent they get any at all).
It takes time and effort to build organizational resources and cultures capable of supporting widespread, high quality, data-driven inference. Some recent work in HCI and related fields speaks to these issues. For example, some folks at CU Boulder have a 2017 CHI paper about how mission-driven organizations can struggle to do data-driven work. In a more interventionist vein, Catherine D’Ignazio and Rahul Barghava have launched the Data Culture Project in an effort to help smaller non-profits and community organizations use data more effectively.
Whatever the organizational context, high quality social scientific and statistical work requires more than just a clear understanding of p-values and massive A/B testing infrastructure. Statistical expertise also needs to be embedded and managed effectively within organizations and teams in order to produce reliable inference.
This is a cross-post from the CASBS Medium channel. Thanks to members of the CDSC, Margaret Levi, and some anonymous friends for feedback on earlier versions of the text.
The International Symposium on Open Collaboration (OpenSym, formerly WikiSym) is the premier academic venue exclusively focused on scholarly research into open collaboration. OpenSym is an ACM conference which means that, like conferences in computer science, it’s really more like a journal that gets published once a year than it is like most social science conferences. The “journal”, in this case, is called the Proceedings of the International Symposium on Open Collaboration and it consists of final copies of papers which are typically also presented at the conference. Like journal articles, papers that are published in the proceedings are not typically published elsewhere.
Along with Claudia Müller-Birn from the Freie Universtät Berlin, I served as the Program Chair for OpenSym 2017. For the social scientists reading this, the role of program chair is similar to being an editor for a journal. My job was not to organize keynotes or logistics at the conference—that is the job of the General Chair. Indeed, in the end I didn’t even attend the conference! Along with Claudia, my role as Program Chair was to recruit submissions, recruit reviewers, coordinate and manage the review process, make final decisions on papers, and ensure that everything makes it into the published proceedings in good shape.
In OpenSym 2017, we made several changes to the way the conference has been run:
In previous years, OpenSym had tracks on topics like free/open source software, wikis, open innovation, open education, and so on. In 2017, we used a single track model.
Because we eliminated tracks, we also eliminated track-level chairs. Instead, we appointed Associate Chairs or ACs.
We eliminated page limits and the distinction between full papers and notes.
We allowed authors to write rebuttals before reviews were finalized. Reviewers and ACs were allowed to modify their reviews and decisions based on rebuttals.
To assist in assigning papers to ACs and reviewers, we made extensive use of bidding. This means we had to recruit the pool of reviewers before papers were submitted.
Although each of these things have been tried in other conferences, or even piloted within individual tracks in OpenSym, all were new to OpenSym in general.
Overview
Statistics
Papers submitted
44
Papers accepted
20
Acceptance rate
45%
Posters submitted
2
Posters presented
9
Associate Chairs
8
PC Members
59
Authors
108
Author countries
20
The program was similar in size to the ones in the last 2-3 years in terms of the number of submissions. OpenSym is a small but mature and stable venue for research on open collaboration. This year was also similar, although slightly more competitive, in terms of the conference acceptance rate (45%—it had been slightly above 50% in previous years).
As in recent years, there were more posters presented than submitted because the PC found that some rejected work, although not ready to be published in the proceedings, was promising and advanced enough to be presented as a poster at the conference. Authors of posters submitted 4-page extended abstracts for their projects which were published in a “Companion to the Proceedings.”
Topics
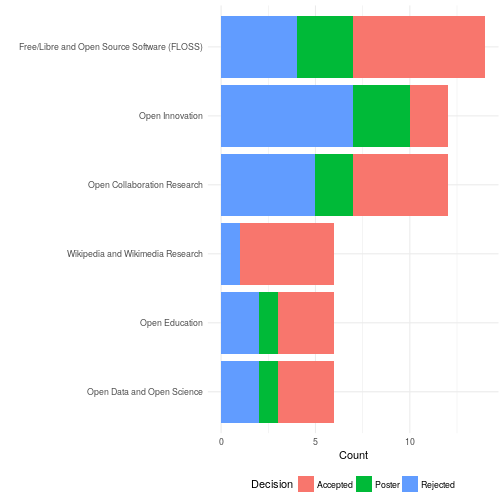
Over the years, OpenSym has established a clear set of niches. Although we eliminated tracks, we asked authors to choose from a set of categories when submitting their work. These categories are similar to the tracks at OpenSym 2016. Interestingly, a number of authors selected more than one category. This would have led to difficult decisions in the old track-based system.
The figure above shows a breakdown of papers in terms of these categories as well as indicators of how many papers in each group were accepted. Papers in multiple categories are counted multiple times. Research on FLOSS and Wikimedia/Wikipedia continue to make up a sizable chunk of OpenSym’s submissions and publications. That said, these now make up a minority of total submissions. Although Wikipedia and Wikimedia research made up a smaller proportion of the submission pool, it was accepted at a higher rate. Also notable is the fact that 2017 saw an uptick in the number of papers on open innovation. I suspect this was due, at least in part, to work by the General Chair Lorraine Morgan’s involvement (she specializes in that area). Somewhat surprisingly to me, we had a number of submission about Bitcoin and blockchains. These are natural areas of growth for OpenSym but have never been a big part of work in our community in the past.
Scores and Reviews
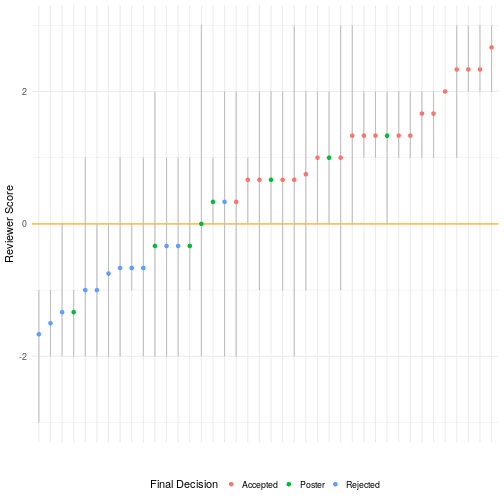
As in previous years, review was single blind in that reviewers’ identities are hidden but authors identities are not. Each paper received between 3 and 4 reviews plus a metareview by the Associate Chair assigned to the paper. All papers received 3 reviews but ACs were encouraged to call in a 4th reviewer at any point in the process. In addition to the text of the reviews, we used a -3 to +3 scoring system where papers that are seen as borderline will be scored as 0. Reviewers scored papers using full-point increments.
The figure above shows scores for each paper submitted. The vertical grey lines reflect the distribution of scores where the minimum and maximum scores for each paper are the ends of the lines. The colored dots show the arithmetic mean for each score (unweighted by reviewer confidence). Colors show whether the papers were accepted, rejected, or presented as a poster. It’s important to keep in mind that two papers were submitted as posters.
Although Associate Chairs made the final decisions on a case-by-case basis, every paper that had an average score of less than 0 (the horizontal orange line) was rejected or presented as a poster and most (but not all) papers with positive average scores were accepted. Although a positive average score seemed to be a requirement for publication, negative individual scores weren’t necessary showstoppers. We accepted 6 papers with at least one negative score. We ultimately accepted 20 papers—45% of those submitted.
Rebuttals
This was the first time that OpenSym used a rebuttal or author response and we are thrilled with how it went. Although they were entirely optional, almost every team of authors used it! Authors of 40 of our 46 submissions (87%!) submitted rebuttals.
Lower
Unchanged
Higher
6
24
10
The table above shows how average scores changed after authors submitted rebuttals. The table shows that rebuttals’ effect was typically neutral or positive. Most average scores stayed the same but nearly two times as many average scores increased as decreased in the post-rebuttal period. We hope that this made the process feel more fair for authors and I feel, having read them all, that it led to improvements in the quality of final papers.
Page Lengths
In previous years, OpenSym followed most other venues in computer science by allowing submission of two kinds of papers: full papers which could be up to 10 pages long and short papers which could be up to 4. Following some other conferences, we eliminated page limits altogether. This is the text we used in the OpenSym 2017 CFP:
There is no minimum or maximum length for submitted papers. Rather, reviewers will be instructed to weigh the contribution of a paper relative to its length. Papers should report research thoroughly but succinctly: brevity is a virtue. A typical length of a “long research paper” is 10 pages (formerly the maximum length limit and the limit on OpenSym tracks), but may be shorter if the contribution can be described and supported in fewer pages— shorter, more focused papers (called “short research papers” previously) are encouraged and will be reviewed like any other paper. While we will review papers longer than 10 pages, the contribution must warrant the extra length. Reviewers will be instructed to reject papers whose length is incommensurate with the size of their contribution.
The following graph shows the distribution of page lengths across papers in our final program.
In the end 3 of 20 published papers (15%) were over 10 pages. More surprisingly, 11 of the accepted papers (55%) were below the old 10-page limit. Fears that some have expressed that page limits are the only thing keeping OpenSym from publshing enormous rambling manuscripts seems to be unwarranted—at least so far.
Bidding
Although, I won’t post any analysis or graphs, bidding worked well. With only two exceptions, every single assigned review was to someone who had bid “yes” or “maybe” for the paper in question and the vast majority went to people that had bid “yes.” However, this comes with one major proviso: people that did not bid at all were marked as “maybe” for every single paper.
Given a reviewer pool whose diversity of expertise matches that in your pool of authors, bidding works fantastically. But everybody needs to bid. The only problems with reviewers we had were with people that had failed to bid. It might be reviewers who don’t bid are less committed to the conference, more overextended, more likely to drop things in general, etc. It might also be that reviewers who fail to bid get poor matches which cause them to become less interested, willing, or able to do their reviews well and on time.
Having used bidding twice as chair or track-chair, my sense is that bidding is a fantastic thing to incorporate into any conference review process. The major limitations are that you need to build a program committee (PC) before the conference (rather than finding the perfect reviewers for specific papers) and you have to find ways to incentivize or communicate the importance of getting your PC members to bid.
Although we tried quite a lot of new things, my sense is that nothing we changed made things worse and many changes made things smoother or better. Although I’m not directly involved in organizing OpenSym 2018, I am on the OpenSym steering committee. My sense is that most of the changes we made are going to be carried over this year.
Finally, it’s also been announced that OpenSym 2018 will be in Paris on August 22-24. The call for papers should be out soon and the OpenSym 2018 paper deadline has already been announced as March 15, 2018. You should consider submitting! I hope to see you in Paris!
This Analysis
OpenSym used the gratis version of EasyChair to manage the conference which doesn’t allow chairs to export data. As a result, data used in this this postmortem was scraped from EasyChair using two Python scripts. Numbers and graphs were created using a knitr file that combines R visualization and analysis code with markdown to create the HTML directly from the datasets. I’ve made all the code I used to produce this analysis available in this git repository. I hope someone else finds it useful. Because the data contains sensitive information on the review process, I’m not publishing the data.
Over at Crooked Timber, Henry Farrell and others recently held a book seminar to discuss Cory Doctorow’s Walkaway. The symposium led to an extended discussion between Henry, Cory, Henry again, and Yochai Benkler about Benkler’s early work on commons-based peer production, spaces of resistance in the contemporary information economy, and the state of peer production a little over fifteen years since Benkler introduced the term. This (far too long) post summarizes some of their key points as a way of starting to collect my own thoughts on these questions.
I haven’t read Walkaway yet (downloaded my DRM-free digital copy, but the fiction slot in my brain is currently occupied by Philip Pullman’s totally engrossing La Belle Sauvage), but I can’t wait to get to it. Cory says the book started as an exercise in projecting how the sociotechnical transformations Benkler laid out in Coase’s Penguin might facilitate the spread of utopian energies at the periphery of radically unequal societies not so different from our own:
It’s been 15 years since Benkler made the connection between “commons-based peer-production” and Coase…
Down and Out in the Magic Kingdom projected Slashdot karma and Napster superdistribution across a whole society as a way of illuminating the strengths and weaknesses of both. Walkaway tries to do the same with commons-based peer-production: what would a skyscraper look like if it was a Wikipedia-style project? How about a space program?
As a Coasean tale, Walkaway is one the battleground between the technological, Promethean left—which has promised to lift peasants up to the material comfort of lords—and the de-growth green left, which promises to bring lords down to the level of the peasants in the name of saving the planet.
and later:
This is (in my view) a Utopian vision. It supposes that the Bohemian projects that even the most buttoned-down societies allow at their margins can breed real discontent and nurture and sustain it into something that genuinely challenges its host… They provided real-world lessons on which tactics worked and where the weaknesses were. They were battles, not the war. The only thing more extraordinary than a social justice prevailing at all is for it to prevail on its first outing, or second, or third.
In his contribution to the seminar, Henry points to Cory’s assumption that “exit” (in Hircshman’s sense) remains viable in a society pervaded by vast power inequalities, surveillance capabilities, and an (increasingly weaponized) disregard for privacy:
Again, Doctorow’s book isn’t an exercise in predictive science – he’s not saying that things will be so. But he is saying, I think, that things could and should be so, or sort-of so. Walkaway is quite unashamedly a didactic book in the way that earlier books such as Homeland were didactic – he has a very clear message to get across. In conversations with Steve Berlin Johnson years ago, I came up with the term BoingBoing Socialism to refer to a specific set of ideas associated with Doctorow and the people around him – that free exchange of ideas unimpeded by intellectual property law and the like, together with transformative technologies of manufacture, could open up a path towards a radically egalitarian future. Unless I’m seriously mistaken (in which case I’m sure that Doctorow will tell me), Walkaway wants to do two things – to argue for why such a future might be attractive, and to suggest that something like this future could be feasible.
For Henry, the implications boil down to questions of power and the role powerful entities play in shaping the lives of even the most peripheral, socially excluded groups within a society. He also (later on) expresses skepticism at the political prospects of the revolutionary vision of “BoingBoing Socialism” that adopts a rhetoric of contingency and self-marginalization as its platform for change.
Ronald Coase. 2003, U of Chicago Law School.
In a followup post, Henry elaborates a claim that Benkler engaged in a sort of naive Coasean disregard for power relations when he laid out the definitional statements on peer production. Henry says Benkler emphasized transaction cost and efficiency-centric explanations for the potential of peer production to substitute for firm or market-based modes of knowledge production and exchange:
Power relationships often explain who gets what, and which forms of organization are taken up, and which fall by the wayside. In general, forms of production that are (a) more efficient, but (b) inconvenient or unprofitable for powerful actors, are probably not going to be taken up, since those powerful actors will block them. Yet if one starts from an efficiency perspective, it is very hard to build power relations in, since one believes that change in practices and institutions is not driven by power relations but by efficiency.
and later:
What this means, if you take it seriously, is that Coaseian coordination is a special case of bargaining. Broadly speaking, Coaseian processes will lead to efficient outcomes only under very specific circumstances – when the actors have symmetrical breakdown values, as in the first game, so that neither of them is able to prevail over the other. More simply put, the Coase transaction cost account of how efficient institutions emerge will only work when all actors are more or less equally powerful. Under these conditions, it is perfectly alright to assume as Coase (and Benkler by extension) do, that efficiency considerations rather than power relations will drive change. In contrast, where there are significant differences of power, actors will converge on the institutions that reflect the preferences of powerful actors, even if those institutions are not the most efficient possible.
and finally:
In short – we need to distinguish between the rhetorical claims that technological change will bring openness along with it, and the (far more sustainable) claim that technology will probably only have openness enhancing benefits in a world where we are already dealing with the underlying power relations.
Benkler responds that Farrell is right to question his (Benkler’s) approach to power, but wrong in that the failure of his (Benkler’s) arguments in Coase’s Penguin and The Wealth of Networks is not driven by naive Coaseanism, but a different dimension of power entirely:
My primary mistake in my work fifteen years ago, and even ten, was not ignoring the role of power in shaping market patterns, but in understating the extent to which the new “market actors who will build the tools that make this population better able…” will themselves become the new incumbent market actors who will shape the environment to increase and lock-in their power. That is certainly a mistake in reading the landscape of power grabs, and I have tried to correct over the intervening years, most recently by offering a map of what has developed in the past decade…
In other words, today’s Benkler argues that yesterday’s Benkler underestimated the adaptive capacities of various incumbent powers as well as the way that a continuously shifting technical, regulatory, and political environment would alter the landscape along the way.
All of this speaks to an ongoing conversation Mako and I have been having about the past, present, and future of peer production. A pessimistic account might run like this: peer production thrived from ~1995-2008 in part because incumbent firms and private actors had not figured out how to capitalize on the possibilities for community-based provision of resources unlocked by the diffusion of digitally networked communications infrastructure. Now that increasing numbers of firms have done so, there is no going back. Large firms as well as their venture-funded spawn will continue to eat peer production communities’ lunch, undermining their viability as well as their autonomy. Peer production as we know it will eventually disappear, becoming a curious relic of a more naive era when the electronic frontier remained an unsettled, experimental space.
Another possibility, arguably more optimistic, can be seen in Benkler and Doctorow’s contributions to this exchange. Rather than consigning peer production to the dustbin of history, they both suggest that room for maneuver (or “degrees of freedom” in Benkler’s terms) will remain at the margins of the networked information economy and that communities of “walkaways” may persist in experimenting with “real utopian” autonomous alternatives to the more extractive, winner-take-all models of “supercapitalist” knowledge production and exchange. Doctorow’s fiction seems to explore the (hopeful) potential of these walkaway communities to generate radical, systematic transformation. Benkler, in his more recent writings, holds out some hope, but of a highly contingent, tenuous, and circumscribed sort.
I recently read Deborah M. Gordon’s Ant Encounters and thought I’d summarize some thoughts about it. Gordon is a Professor of Biology at Stanford. The book pulls together several decades of research (hers and others’) on the behavior and ecology of ants. In it, Gordon makes nuanced claims about the importance of communication and interaction for distributed collective behavior in clear, non-technical language. Many of the findings should inspire people (like me) interested in understanding the organization of collective behavior in humans.
Gordon argues that ant behavior and colony dynamics encompass a complex system driven by patterns of interactions, information exchange, and environmental influences. She contrasts this with more deterministic accounts of ants prevalent in earlier scientific literature and popular culture. Gordon emphasizes how ants operate by behavioral heuristics and information processing rather than a fixed set of rules or genetically encoded traits.
Argentine ant (cc-by-sa, Penarc, Wikimedia Commons)
Consider the division of labor within an ant colony. The prevailing (wrong) view depicts ants born into a pre-specified, genetically determined “caste” which has a clearly-defined task within a hierarchically structured colony. Following this story, the Queen of the colony births out larva who grow into task-specialized sterile adults. Individuals within each caste supposedly possess physical traits that support their specialization as foragers, trash removers, larva-tenders, patrollers, or whatever. Each individual supposedly pursues their specialized task tirelessly until death.
It turns out that this account reflects a mixture of reasonable misinterpretation and fantastical thinking. First off, Gordon notes, ants change tasks within their life course. Today’s larva-tender may be tomorrow’s forager. These changes do not entail biological changes within each ant (although there seems to be evidence that ants do tend to adopt specific tasks at specific stages of their lives within a colony), but instead reflect responses to interactions with other members of the colony and external forces shaping those interactions. In a younger, less populous colony, ants may change tasks in response to immediate needs and threats that arise suddenly. In larger, more mature colonies where things are less likely to change suddenly, many ants may have more stable activities. Some ants in large colonies even literally sit around doing nothing because the information they receive from their nest-mates indicates that the colonies needs are being met. None of this is fixed by genetic encoding or hierarchical commands.
Second, Gordon shows how ants respond probabilistically to local stimuli. Individual ants, it turns out, act a lot like heuristic distributed sensors or nodes in a communications network—each with some likelihood of changing its behavior depending on the feedback it receives from its environment. They are not automatons with deterministic programming to pursue a single-minded course of action.
Third, Gordon shows how colonies as a whole change in reaction to their environments and collective interactions. If one colony finds itself in proximity to another, the individuals within it may alter how much collective effort is dedicated to specific tasks depending on the species, size, and temperament of its neighbors. Individual ants respond to the number of nest-mates and neighbors they encounter. If their last ten encounters were with foragers from their home nest returning with food to feed the larval brood, they may continue to go about their business uninterrupted. As the portion of recent interactions includes outsiders or nest-mates responding frantically to an unwelcome intruder of some sort, the probability rises that the next ant will change its behavior in response (maybe to start running around in a panic or bite an intruder).
Harvester ants collecting seeds (cc-by-sa Donkey Shot, Wikimedia Commons)
Through many examples, Gordon conveys how patterns of collective ant behavior emerge and adapt to local circumstances without a centralized coordination mechanism or hierarchy of control. She describes this almost entirely without recourse to the jargon of complexity theory or complex systems research.
A concrete, measured, and example-driven account of how actually existing complex systems work is maybe the most impressive achievement of the book. Many texts discuss complexity in human and ecological systems, but none that I have read do so with the clarity of Ant Encounters. While I should read more books on these topics, more people in my little corner of the research world should read Gordon’s work too.
Ant Encounters ultimately left me excited to pursue some of the potential extensions and connections between Gordon’s work and research on human social systems and organizations. For example, I’d love to follow up on her comment that higher interaction frequency is associated with colony growth or survival (I currently forget which). Would such a finding hold up in the context of human organizations? If so, what would it look like and mean in the context of building effective peer production systems? Gordon has also written elsewhere about some of the potential connections between ant behavior, human organization, communication protocols. Recent findings from Gordon and her collaborators show how ants follow a set of behavior protocols very similar to those encoded in the TCP specification (apparently, she likes to refer to this idea as “the Anternet“). I’m eager to read more of the scientific publications from Gordon and her collaborators to understand these ideas more deeply and to see how well they travel when applied to a species I know a little bit more about.
A few hours ago, OpenSym 2017 kicked off in Galway. For those that don’t know, OpenSym is the International Symposium on Wikis and Open Collaboration (it was called WikiSym until 2014). Its the premier academic venue focused on research on wikis, open collboration, and peer production.
This year, Claudia Müller-Birn and I served as co-chairs of the academic program. Acting as program chair for an ACM conference like OpenSym is more like being a journal editor than a conference organizer. Claudia and I drafted and publicized a call for papers, recruited Associate Chairs and members of a program committee who would review papers and make decisions, coordinated reviews and final decisions, elicited author responses, sent tons of email to notify everybody about everything, and dealt with problems as they came up. It was a lot of work! With the schedule set, and the proceedings now online, our job is officially over!
OpenSym reviewed 43 papers this year and accepted 20 giving the conference a 46.5% acceptance rate. This is similar to both the number of submissions and the acceptance rates for previous years.
In addition to papers, we received 3 extended abstracts for posters for the academic program and accepted 1. There were an additional 7 promising papers that were not accepted but whose authors were invited to present posters and who will be doing so at the conference. The authors of posters will have extended abstracted about their posters published in the non-archival companion proceedings.
The list of papers being published and presented at OpenSym includes:
What do Wikidata and Wikipedia have in common? An analysis of their use of external references by Alessandro Piscopo (University of Southampton), Pavlos Vougiouklis (University of Southampton), Lucie-Aimee Kaffee (University of Southampton), Christopher Phethean (University of Southampton), Jonathon Hare (University of Southampton), Elena Simperl (University of Southampton)
Opening up New Channels for Scholarly Review, Dissemination, and Assessment by Edit Gorogh (University of Gottingen), Michela Vignoli (Austrian Institute of Technology Vienna), Eleni Toli (University of Athens), Electra Sifacaki (University of Athens), Peter Kraker (Know Center), Hasani-Mavriqi (Know Center), Stephan Gauch (German Centre for Higher Education Research and Science Studies [DZHW]), Daniela Luzi (Consiglio Nazionale delle Ricerche Rome), Mappet Walker (Frontiers), Clemens Blümel (German Centre for Higher Education Research and Science Studies [DZHW] & Humboldt University Berlin)
Implementing Federated Social Networking: Report from the Trenches by Gabriel Dos Santos Silva (University of Brasilia), Paulo Meirelles (LOSS Competence Center, University of San Paulo Larissa Reis (Colivre), Antonio Terceiro (Colivre), Fabio Kon (FLOSS Competence Center, University of San Paulo
Social Identity and Social Media Activities in Equity Crowdfunding by Sean Nevin (University College Cork), Rob Gleasure (University College Cork), Philip O’Reilly (University College Cork), Joseph Feller (University College Cork), Shanping Li (Zhejiang University), Jerry Cristoforo (State Street Corporation
A Glimpse into Babel: An Analysis of Multilingualism in Wikidata by Lucie-Aimee Kaffee (University of Southampton), Alessandro Piscopo (University of Southampton), Pavlos Vougiouklis (University of Southampton), Elena Simperl (University of Southampton), Leslie Carr (University of Southampton), Lydia Pintscher (Wikimedia Deutschland)
An Author Network to Classify Open Online Discussions by Mattias Mano (i3-Centre de Recherches en Gestion, Ecole Polytechnique), Jean-Michel Dalle (University Pierre et Marie Curie), Joanna Tomasik (Centrale Supelec)
Open Peer Review CMS Support by Oliver Zendel (Austrian Institute of Technology), Matthias Schorghuber (Austrian Institute of Technology), Michela Vignoli (Austrian Institute of Technology)
Managing Risk in Business Centric Crowdfunding Platforms by Peter Stack (University College Cork), Joe Feller (University College Cork), Phil O’Reilly (University College Cork), Rob Gleasure (University College Cork), Shanping Li (Zhejiang University), Jerry Cristoforo (State Street Corporation)
When to Use Rewards in Charitable Crowdfunding by Stephen Warren (University College Cork), Rob Gleasure (University College Cork), Philip O’Reilly (University College Cork), Joseph Feller (University College Cork), Shanping Li (Zheijang University), Jerry Christoforo (State Street Corporation)
There was also a doctoral consortium and a non-academic ”industry track” which Claudia and I weren’t involved in coordinating.
As part of running the program, we tried a bunch of new things this year including:
A move away from separate tracks back to a singlec combined model with Associate Chairs.
Bidding for papers among both Associate Chairs and normal PC members.
An author rebuttal/response period where authors got to respond to reviews and reviewers.
An elimination of page limits for papers. This meant that the category of notes also disappeared. Reviewers were instructed to evaluate the degree to which papers’ contributions were commensurate to their length.
I’m working on a longer post that will evaluate these changes. Until then, enjoy Galway if you were lucky enough to be there. If you couldn’t make it, enjoy the proceedings online!
You can learn more about OpenSym on it’s Wikipedia article on the OpenSym website. You can find details on the schedule and the program itself at its temporary home on the OpenSym website. I’ll update this page with a link to the ACM Digital Library page when it gets posted.



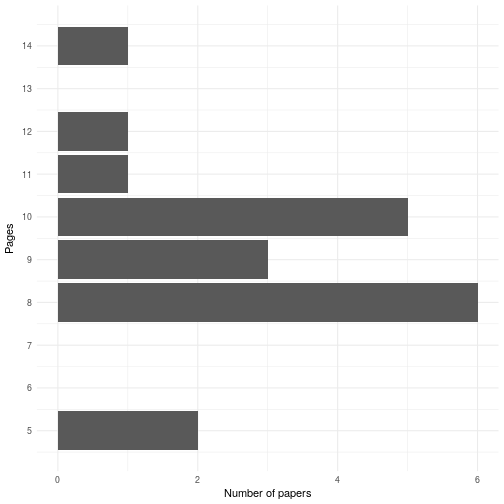 In the end 3 of 20 published papers (15%) were over 10 pages. More surprisingly, 11 of the accepted papers (55%) were below the old 10-page limit. Fears that some have expressed that page limits are the only thing keeping OpenSym from publshing enormous rambling manuscripts seems to be unwarranted—at least so far.
In the end 3 of 20 published papers (15%) were over 10 pages. More surprisingly, 11 of the accepted papers (55%) were below the old 10-page limit. Fears that some have expressed that page limits are the only thing keeping OpenSym from publshing enormous rambling manuscripts seems to be unwarranted—at least so far.




 A few hours ago,
A few hours ago,